Mongodb同步数据到hive(二)
1、 概述
上一篇文章主要介绍了mongodb-based,通过直连mongodb的方式进行数据映射来进行数据查询,但是那种方式会对线上的数据库产生影响,所以今天介绍第二种方式—BSON-based,即使用mongoexport将所需要的表导出到本地文件,文件个是默认为bson。然后将导出的bson文件put到HDFS文件系统里面,最后在hive里面创建相应的表来使用hive sql进行查询。
2、 导出bson文件
使用mongodump命令,导出所需要的collection或字段。常用的命令如下:
1)#/data/mongodb/bin/mongodump -uhqms -phqms123 -h 10.10.111.192:27017 --collection users --db saturn -o /data/mongodata/
!-u :指定用户,用于备份的用户必须对数据库有读的权限。
!-p: 指定用户密码
!-h:指定数据库服务器ip和端口,例如:ip:port
!-d: 指定数据库名称
!--collection: 指定要备份的collection的名称
!-o:指定输出路径
3)如果mongodb与hadoop和hive是分开部署的,那么需要在hadoop服务器上部署一个mongodb,此服务不用运行,只是为了使用mongoexport命令copy数据。
3、 将文件导入到HDFS
1)首先需要在HDFS里面创建相应的目录,用来存储相应的表文件。
2)注意,每个表需要对应创建一个目录
3)命令如下(我已经将hadoop的bin加到环境变量里面了):
#hdfs dfs -mkdir /myjob
#hdfs dfs -mkdir /myjob/job1
!!注意,hdfs的目录必须一级一级的创建,不能一次创建多级。
#将文件传入到HDFS
#hdfs dfs -put /data/job1 /myjob/job1
@/data/job1 为本地路径,即导出的mongodb的文件的路径
@/myjob/job1 为HDFS的路径
4)查看已经上传到HDFS的文件
#hdfs dfs -ls /myjob/job1
5)修改权限
#hdfs dfs -chmod 777 /myjob/job1
6)获取hdfs里面的文件
#hdfs dfs –get /myjob/job1 /data/job1
7)删除文件
#hdfs dfs -rm /myjob/job1
删除目录
#hdfs dfs -rm -r /myjob
Myjob目录需要为空,如果要强制删除非空目录,需要加上-f。
4、 hive里面创建表
#hive
hive>create table if not exists ${table_name}
(
Id string,
Userid string,
.
.
.
comment ‘描述’
row format serd ‘com.mongodb.hadoop.hive.BSONSerDe’
with serdeproperties('mongo.columns.mapping'='{hive字段与mongo字段的映射关系}')
stored as inputformat 'com.mongodb.hadoop.mapred.BSONFileInputFormat'
outputformat 'com.mongodb.hadoop.hive.output.HiveBSONFileOutputFormat'
location ‘HDFS的目录’
#location指示的是bson文件所在的HDFS目录,即/myjob/job1.
5、为了方便使用,将导出mongodb到本地,并将文件导入到HDFS里面。做了一个脚本。
#cat hdfs.sh
#!/bin/bash
#此脚本用于将mongodb里面的collection到处为BSON文件,并将文件上传到HDFS里面
#定义要导出的表名
list="
merchants
martproducts
products
coupons
couponlogs
reviews
orderoplogs
orders
"
#判断文件是否存在,存在则删除
for i in $list
do
if [ -e /data/mongodata/$i ];then
rm -rf /data/mongodata/$i
sleep 5s
fi
done
#从mongodb导出数据到本地
for a in $list
do
nohup /data/mongodb/bin/mongodump -uhqms -phqms123 -h 10.10.111.192:27017 --collection $a --db saturn -o /data/mongodata/$a >>/data/nohup.out 2>&1 &
sleep 1m
done
#将HDFS里面的文件删除
for b in $list
do
nohup /data/hadoop-2.7.3/bin/hdfs dfs -rm /$b/*.bson >>/data/nohuprm.out 2>&1 &
done
#将本地的文件导入到HDFS里面
for c in $list
do
cd /data/mongodata/$c/saturn
/data/hadoop-2.7.3/bin/hdfs dfs -put $c.bson /$c
sleep 1m
done
5、将脚本添加计划任务,有两种方式:一种是使用crontab;一种是使用jenkins。
1)使用crontab
#crontab -e
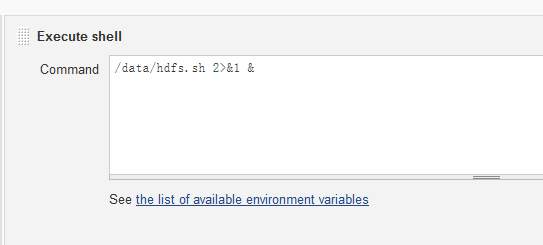
0 00 * * * /data/hdfs.sh 2>&1 &
2)使用jenkins
1、创建一个项目,名称自己定义,

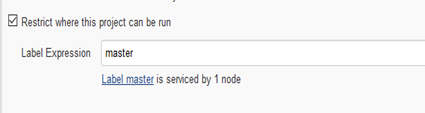
2、创建运行周期
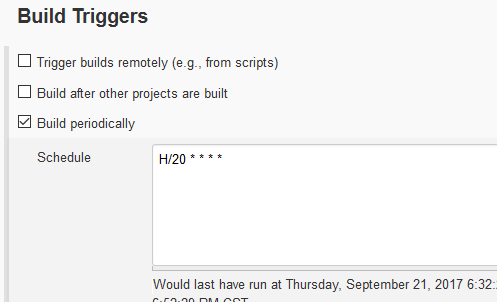
3)执行