今天早上过来突然被告知我们提供给外系统的接口服务出问题了,失败率高达20%
很奇怪,昨天周末,今天也没做什么处理,怎么突然变成这样了
1.接口测试
第一反应是接口是不是出问题了,然后我立马打开jmeter调20次接口
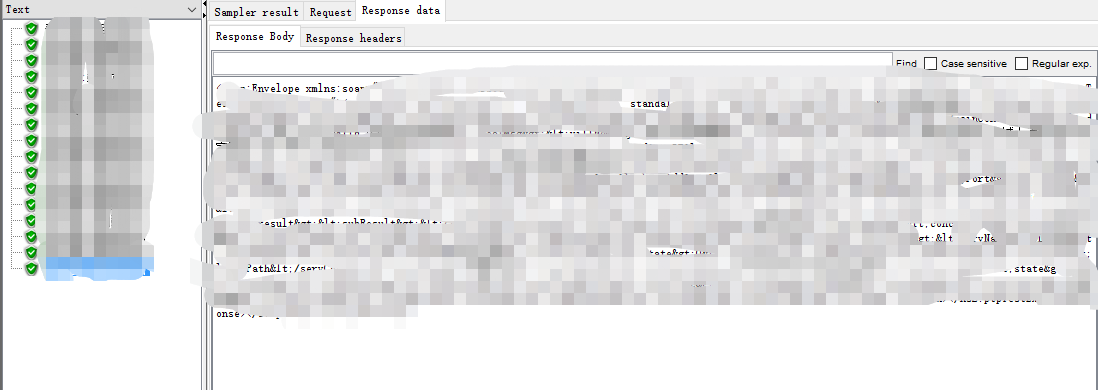
问题是全部成了???
这就很奇怪了,让对端提供截图证据,是不是别人搞我???
2.定位问题服务
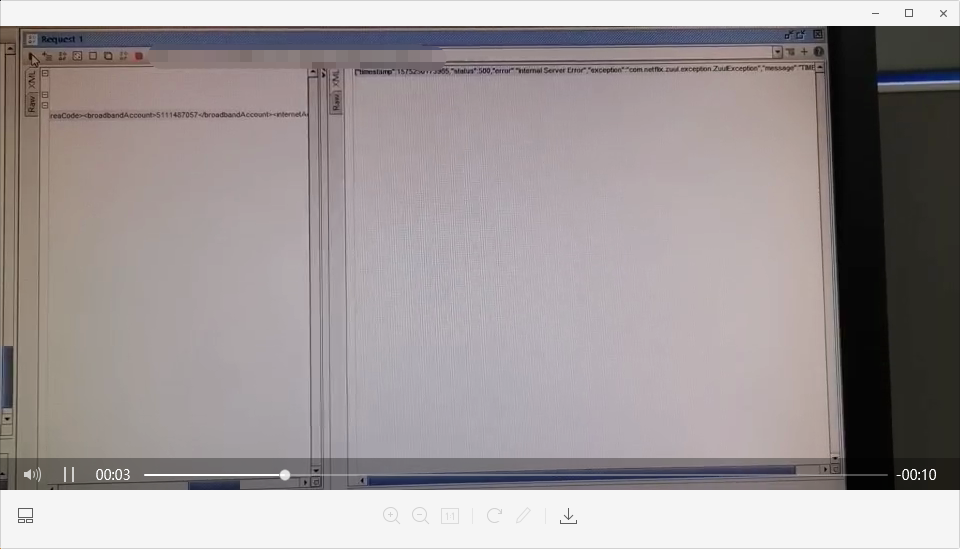
根据对端反馈的视频,可以看到反馈的报错是zuulexception
那么就可以确定,问题抛出的地方在zuul
然后打开日志一看,这一看直接爆炸。。。。
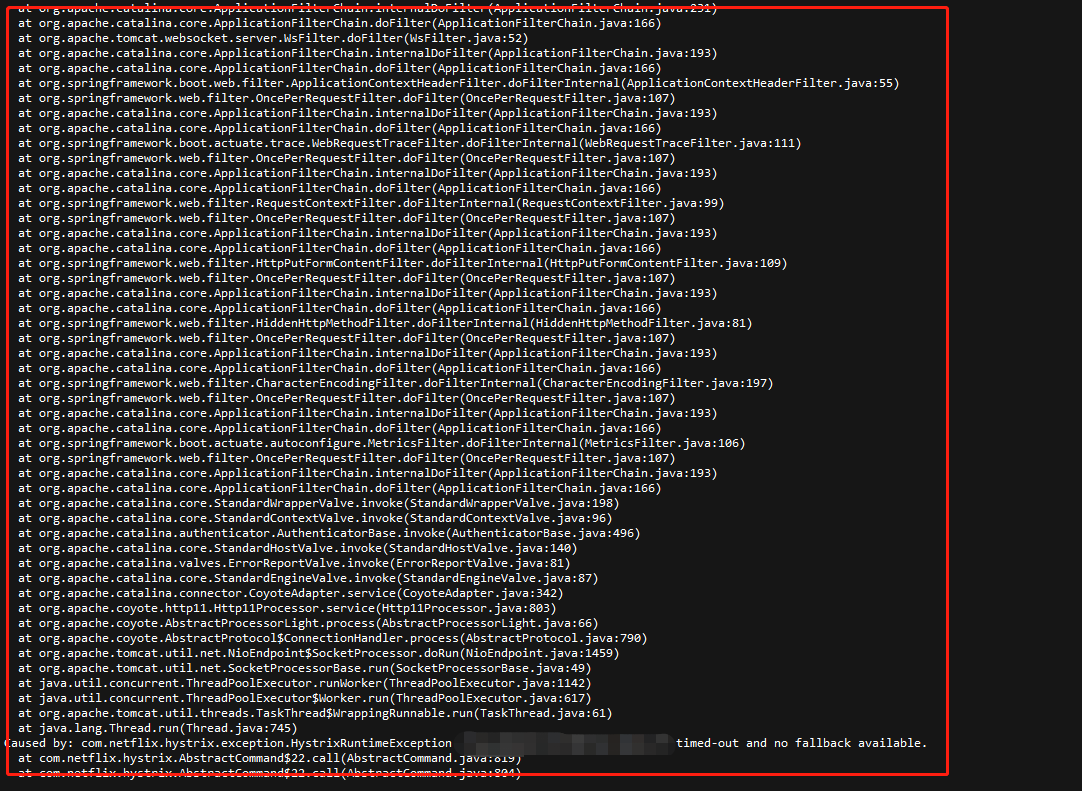
日志疯狂报错,timed-out and no fallback available.
因为当时部署的4个节点,这个机器上的2个节点疯狂报这个错,但是只有20%的的失败率,这个就很奇怪了,
于是我打开第二台机器的日志。。。。
哔了狗。。。。。第二天机器居然毫无波动???
啥意思?就瞧不起前面这台机器咯,到这里我就懵逼了,百思不得起解,然后我第一反应就是看源码。。。
3.源码定位问题
那么要通过源码定位问题,就要准备类似的环境了,生产肯定是不能乱动的
因为之前说过,有台机器是好的,我就先把第一台机器的服务关闭,先把第二台机器的2个节点顶一下了
那么现在生产先抛到一边,我们准备一下环境
1.eureka,2.zuul 3.demo服务
先起eureka

吧对应的服务注册上去

准备接口请求,然后我准备在原来的服务上打个断点,卡一会再过去看看效果
然后我发现卡半天,毫无波动。。。。
几分钟后。。。
终于报错了,但是报的错确不是之前的那个错了

为了模拟那种情况
调试zuul网关参数
设置熔断超时时间:150毫秒,够少了吧

测试一波

终于问题得到复现,很显然是在熔断超时的时间内没有得到返回导致的
但是我们对接口响应时间有要求,3s之内没有返回就应该算超时
那么这个值默认是多少呢??
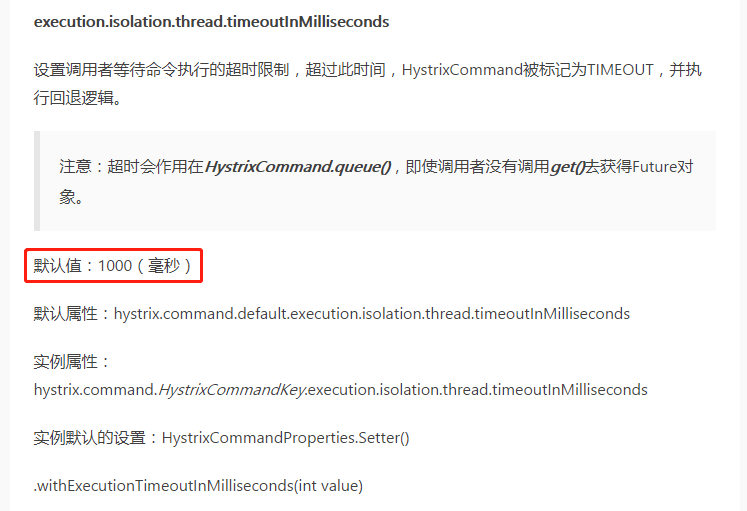
这也太短了,1s不返回就当超时,我们这个接口涉及到的子接口就有6个,更不用说自己还有部分逻辑了,又不能直接把原子接口直接给外系统用
那这边只能改参数了
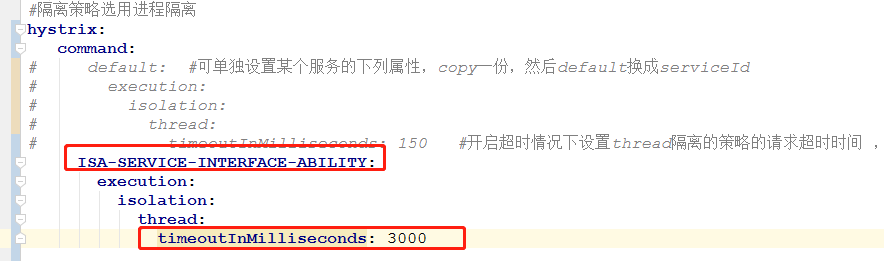
调整之后,调整之后,我们再试试效果
效果确实得到改观
测试请求时间:16点26分26s
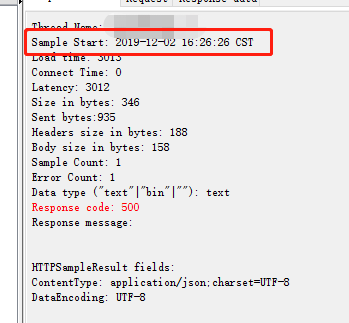
我们报错时间:16:26:29.

跟我们设置的参数吻合,很好
那是不是吧这个调大就把这个问题解决了呢???
4、压测
我们再试试再大量请求的情况下是否还是会出现这种情况,或者是等待
为了更好的测试,我们设置进程池最大数量为2个
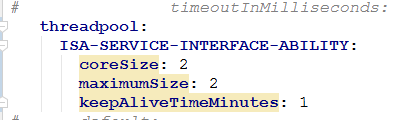
单请求没问题
我们接下来直接模拟8个线程同时请求接口,并在服务中添加线程等待的方法模拟业务繁忙

接下来我们测试一下
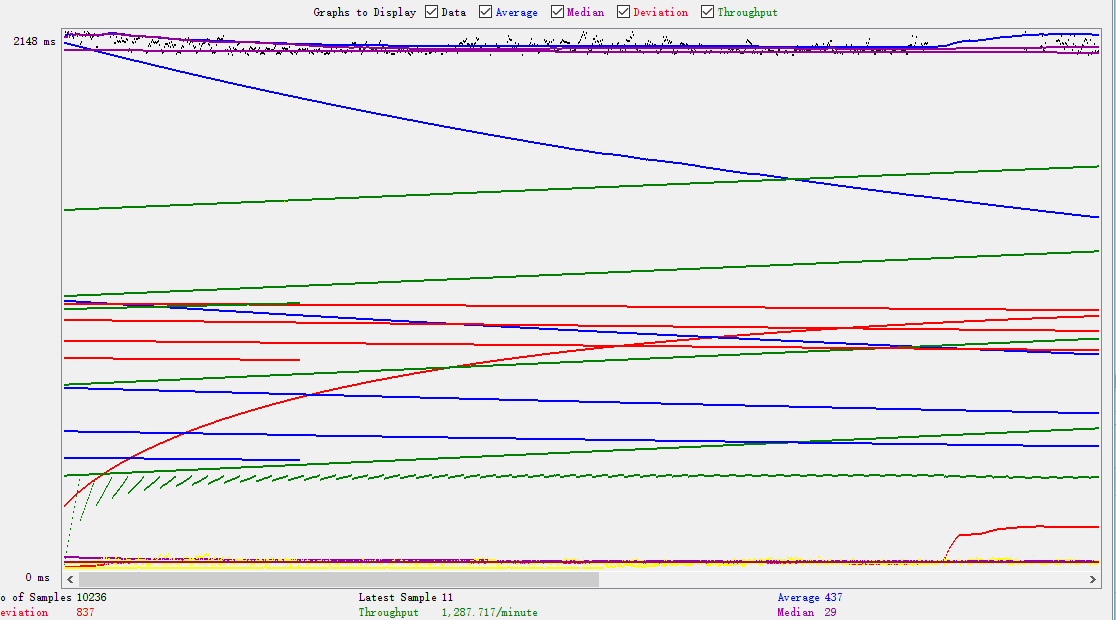
随着时间的推移,我们发现失败的数量越来越多,前面的未执行完,后面的继续堆积
总结:
说白了就是调整熔断返回超时的时间,这个default可以手动设置为对应的服务id
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds
最后注意一点:
这个值要比:ribbon.ReadTimeout 与 ribbon.ConnectTimeout两个参数的值之和要大