深入理解namespaces & cgroups——docker的容器隔离术



chroot,即 change root directory (更改 root 目录)。在 linux 系统中,系统默认的目录结构都是以 `/`,即是以根 (root) 开始的。而在使用 chroot 之后,系统的目录结构将以指定的位置作为 `/` 位置。
在经过 chroot 之后,系统读取到的目录和文件将不在是旧系统根下的而是新根下(即被指定的新的位置)的目录结构和文件,因此它带来的好处大致有以下3个:
- 增加了系统的安全性,限制了用户的权力;
在经过 chroot 之后,在新根下将访问不到旧系统的根目录结构和文件,这样就增强了系统的安全性。这个一般是在登录 (login) 前使用 chroot,以此达到用户不能访问一些特定的文件。
- 建立一个与原系统隔离的系统目录结构,方便用户的开发;
使用 chroot 后,系统读取的是新根下的目录和文件,这是一个与原系统根下文件不相关的目录结构。在这个新的环境中,可以用来测试软件的静态编译以及一些与系统不相关的独立开发。
- 切换系统的根目录位置,引导 Linux 系统启动以及急救系统等。
chroot 的作用就是切换系统的根位置,而这个作用最为明显的是在系统初始引导磁盘的处理过程中使用,从初始 RAM 磁盘 (initrd) 切换系统的根位置并执行真正的 init。另外,当系统出现一些问题时,我们也可以使用 chroot 来切换到一个临时的系统。
cgoups: controls groups
控制存储 计算 网络 IO 等各种资源
cgroups,其名称源自控制组群(英语:control groups)的简写,是Linux内核的一个功能,用来限制、控制与分离一个进程组的资源(如CPU、内存、磁盘输入输出等)。
这个项目最早是由Google的工程师(主要是Paul Menage和Rohit Seth)在2006年发起,最早的名称为进程容器(process containers)[1]。在2007年时,因为在Linux内核中,容器(container)这个名词有许多不同的意义,为避免混乱,被重命名为cgroup,并且被合并到2.6.24版的内核中去[2]。自那以后,又添加了很多功能。
cgroups的一个设计目标是为不同的应用情况提供统一的接口,从控制单一进程(像nice)到操作系统层虚拟化(像OpenVZ,Linux-VServer,LXC)。cgroups提供:
- 资源限制:组可以被设置不超过设定的内存限制;这也包括虚拟内存。[3] [4]
- 优先级:一些组可能会得到大量的CPU[5] 或磁盘IO吞吐量。[6]
- 结算:用来度量系统实际用了多少资源。[7]
- 控制:冻结组或检查点和重启动。[7]







hugetlb 限制HugeTLB(huge translation lookaside buffer)的使用,TLB是MMU中的一块高速缓存(也是一种cache,是CPU内核和物理内存之间的cache),它缓存最近查找过的VA对应的页表项
Docker 技术基础:Cgroups - xftony's blogGithub-blog CSDNcgroups 简介 cgroups(control groups) 包含三个组件,分别为 cgroup、hierarchy,以及 subsystem。
cgroups 简介cgroups(control groups) 包含三个组件,分别为 cgroup、hierarchy,以及 subsystem。 cgroupcgroup 是对进程分组管理的一种机制,cgroups 中的资源控制都以 cgroup 为单位实现。cgroup 表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个任务可以加入某个 cgroup,也可以从某个 cgroup 迁移到另外一个 cgroup。 subsystemsubsystem 是一组资源控制的模块,主要包含 cpuset, cpu, cpuacct, blkio, memory, devices, freezer, net_cls, net_prio, perf_event, hugetlb, pids。具体介绍如下: cpuset 在多核机器上设置cgroup 中进程可以使用的CPU 和内存 cpu 设置cgroup 中进程的CPU 被调度的策略 cpuacct 可以统计cgroup 中进程的CPU 占用 blkio 设置对块设备(比如硬盘)输入输出的访问控制 memory 用于控制cgroup 中进程的内存占用 devices 控制cgroup 中进程对设备的访问 freezer 用于挂起和恢复cgroup 中的进程 net_cls 用于将cgroup 中进程产生的网络包分类,以便Linux 的tc (traffic con位oller)可以根据分类区分出来自某个cgroup 的包并做限流或监控 net_prio 设置cgroup 中进程产生的网络流量的优先级 perf_event 增加了对每group的监测跟踪的能力,即可以监测属于某个特定的group的所有线程以及运行在特定CPU上的线程 hugetlb 限制HugeTLB(huge translation lookaside buffer)的使用,TLB是MMU中的一块高速缓存(也是一种cache,是CPU内核和物理内存之间的cache),它缓存最近查找过的VA对应的页表项 pids 限制cgroup及其所有子孙cgroup里面能创建的总的task数量 查看 kernel 支持的 subsystem 可以使用 root@xftony:~# lssubsys -a cpuset cpu,cpuacct blkio memory devices freezer net_cls,net_prio perf_event hugetlb pids 同时可以在 root@xftony:/sys/fs/cgroup# ls blkio cpu,cpuacct freezer net_cls perf_event cpu cpuset hugetlb net_cls,net_prio pids cpuacct devices memory net_prio systemd hierarchy把一组 cgroup 串成一个树状的结构,一个这样的树便是一个 hierarchy。一个系统可以有多个 hierarchy。通过这种树状结构,cgroups 可以做到继承。 root@xftony:~/test/c0# tree . ├── c1 │ ├── cgroup.clone_children │ ├── cgroup.procs │ ├── notify_on_release │ └── tasks ├── c2 │ ├── cgroup.clone_children │ ├── cgroup.procs │ ├── notify_on_release │ └── tasks ├── cgroup.clone_children ├── cgroup.procs ├── cgroup.sane_behavior ├── notify_on_release ├── release_agent └── tasks cgroup、subsystem、hierarchy 三者关系1、一个 subsystem 只能附加到一个 hierarchy 上面; cgroups 测试:cgroup 的创建创建一个挂载点,即创建一个文件夹,存放 cgroup 文件: 挂载一个 hierachy,不关联任何 subsystem #mount -t cgroup -o none,name=cgroup-root cgroup-root1 ./cgroup-test //此时使用mount查看可以看到 root@pgw-dev-4:~/test/cgroup-test# mount |grep cgroup cgroup-root1 on /root/test/cgroup-test type cgroup (rw,relatime,name=cgroup-root) cgroup-test 目录下会生成一组默认文件: root@pgw-dev-4:~/test/cgroup-test# ls cgroup.clone_children cgroup.procs cgroup.sane_behavior notify_on_release release_agent tasks
查看 此时我们在创建一个新的 hierachy #mount -t cgroup -o cpuset,name=c0-cpuset c0 ./c0 所有的`cgroup.procs`和`tasks`也都会加到c0内的`cgroup.procs`和`tasks`。 subsystem 的挂载subsystem 默认的 mount 的位置是在 umount subsystemumount /sys/fs/cgroup/cpuset/cpuset mount subsystem然后我们在创建 c0, c0 上不绑 subsustem,然后在 c0 下创建 c1, c1 上 mount cpuset 子系统: mkdir c0 mount -t cgroup -o none c0 ./c0 mkdir c1; cd c1 mount -t cgroup -o cpuset c0 ./c1 其得到的 cgroup 结构为: root@xftony:~/test# tree -L 3
.
└── c0
├── c1
│ ├── cgroup.clone_children
│ ├── cgroup.procs
│ ├── cgroup.sane_behavior
│ ├── cpuset.cpu_exclusive
│ ├── cpuset.cpus
│ ├── cpuset.effective_cpus
│ ├── cpuset.effective_mems
│ ├── cpuset.mem_exclusive
│ ├── cpuset.mem_hardwall
│ ├── cpuset.memory_migrate
│ ├── cpuset.memory_pressure
│ ├── cpuset.memory_pressure_enabled
│ ├── cpuset.memory_spread_page
│ ├── cpuset.memory_spread_slab
│ ├── cpuset.mems
│ ├── cpuset.sched_load_balance
│ ├── cpuset.sched_relax_domain_level
│ ├── notify_on_release
│ ├── release_agent
│ └── tasks
├── cgroup.clone_children
├── cgroup.procs
├── cgroup.sane_behavior
├── notify_on_release
├── release_agent
└── tasks
cgroup 的使用在 c1 目录下创建测试目录 cd c1 mkdir cputest; cd cputest //仅允许使用 Cpu1 echo 1 > cpuset.cpus 启动测试程序: root@xftony:~/test# cat test.sh
touch /root/test/my.lock
lock_file=/root/test/my.lock
x=0
while [ -f $lock_file ];do
x=$x+1
done;
root@xftony:~/test#./test.sh
此时 top 查看其内存 cpu 占用情况: %Cpu0 : 75.0 us, 23.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 2.0 st %Cpu1 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu2 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu3 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 32664 root 20 0 23268 5828 2228 R 99.3 0.1 1:13.56 bash 我们将该脚本的 pid: root@xftony:~/test/c0/c1/cputest#echo 32664 > tasks 此时在 top 中,该进程已经迁移到 %Cpu0 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 77.1 us, 22.9 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu2 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu3 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 32664 root 20 0 25060 7636 2228 R 100.0 0.1 5:09.95 bash top 中 cpu 各参数含义: us 用户空间占用CPU百分比 sy 内核空间占用CPU百分比 ni 用户进程空间内改变过优先级的进程占用CPU百分比 id 空闲CPU百分比 wa 等待输入输出的CPU时间百分比 hi 硬件中断 si 软件中断 st: 实时 以上~ |
|


非统一内存访问架构(英语:Non-uniform memory access,简称NUMA)是一种为多处理器的电脑设计的内存架构,内存访问时间取决于内存相对于处理器的位置。在NUMA下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些。
非统一内存访问架构的特点是:被共享的内存物理上是分布式的,所有这些内存的集合就是全局地址空间。所以处理器访问这些内存的时间是不一样的,显然访问本地内存的速度要比访问全局共享内存或远程访问外地内存要快些。另外,NUMA中内存可能是分层的:本地内存,群内共享内存,全局共享内存。
NUMA架构在逻辑上遵循对称多处理(SMP)架构。





| Systemd 是 Linux 系统工具,用来启动守护进程,已成为大多数发行版的标准配置。
Systemd 是 Linux 系统工具,用来启动守护进程,已成为大多数发行版的标准配置。 本文介绍它的基本用法,分为上下两篇。今天介绍它的主要命令,下一篇介绍如何用于实战。  一、由来下面的命令用来启动服务。 $ sudo /etc/init.d/apache2 start # 或者 $ service apache2 start 这种方法有两个缺点。 一是启动时间长。 二是启动脚本复杂。 二、Systemd 概述Systemd 就是为了解决这些问题而诞生的。它的设计目标是,为系统的启动和管理提供一套完整的解决方案。 根据 Linux 惯例,字母  (上图为 Systemd 作者 Lennart Poettering) 使用了 Systemd,就不需要再用 $ systemctl --version 上面的命令查看 Systemd 的版本。 Systemd 的优点是功能强大,使用方便,缺点是体系庞大,非常复杂。事实上,现在还有很多人反对使用 Systemd,理由就是它过于复杂,与操作系统的其他部分强耦合,违反 "keep simple, keep stupid" 的 Unix 哲学。 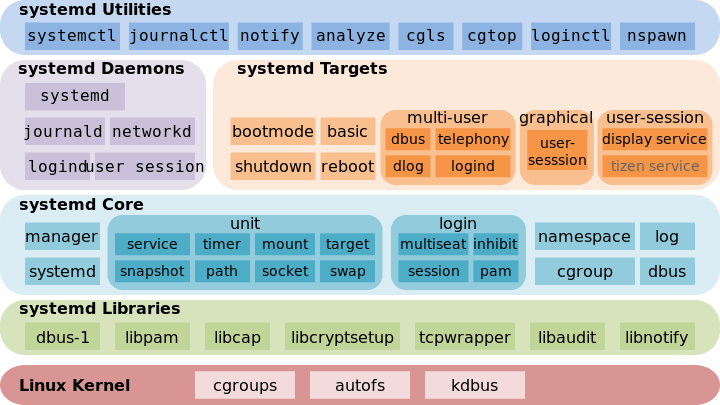 (上图为 Systemd 架构图) 三、系统管理Systemd 并不是一个命令,而是一组命令,涉及到系统管理的方方面面。 3.1 systemctl
# 重启系统 $ sudo systemctl reboot # 关闭系统,切断电源 $ sudo systemctl poweroff # CPU停止工作 $ sudo systemctl halt # 暂停系统 $ sudo systemctl suspend # 让系统进入冬眠状态 $ sudo systemctl hibernate # 让系统进入交互式休眠状态 $ sudo systemctl hybrid-sleep # 启动进入救援状态(单用户状态) $ sudo systemctl rescue 3.2 systemd-analyze
# 查看启动耗时 $ systemd-analyze # 查看每个服务的启动耗时 $ systemd-analyze blame # 显示瀑布状的启动过程流 $ systemd-analyze critical-chain # 显示指定服务的启动流 $ systemd-analyze critical-chain atd.service 3.3 hostnamectl
# 显示当前主机的信息 $ hostnamectl # 设置主机名。 $ sudo hostnamectl set-hostname rhel7 3.4 localectl
# 查看本地化设置 $ localectl # 设置本地化参数。 $ sudo localectl set-locale LANG=en_GB.utf8 $ sudo localectl set-keymap en_GB 3.5 timedatectl
# 查看当前时区设置 $ timedatectl # 显示所有可用的时区 $ timedatectl list-timezones # 设置当前时区 $ sudo timedatectl set-timezone America/New_York $ sudo timedatectl set-time YYYY-MM-DD $ sudo timedatectl set-time HH:MM:SS 3.6 loginctl
# 列出当前session $ loginctl list-sessions # 列出当前登录用户 $ loginctl list-users # 列出显示指定用户的信息 $ loginctl show-user ruanyf 四、Unit4.1 含义Systemd 可以管理所有系统资源。不同的资源统称为 Unit(单位)。 Unit 一共分成 12 种。
# 列出正在运行的 Unit $ systemctl list-units # 列出所有Unit,包括没有找到配置文件的或者启动失败的 $ systemctl list-units --all # 列出所有没有运行的 Unit $ systemctl list-units --all --state=inactive # 列出所有加载失败的 Unit $ systemctl list-units --failed # 列出所有正在运行的、类型为 service 的 Unit $ systemctl list-units --type=service 4.2 Unit 的状态
# 显示系统状态 $ systemctl status # 显示单个 Unit 的状态 $ sysystemctl status bluetooth.service # 显示远程主机的某个 Unit 的状态 $ systemctl -H root@rhel7.example.com status httpd.service 除了 # 显示某个 Unit 是否正在运行 $ systemctl is-active application.service # 显示某个 Unit 是否处于启动失败状态 $ systemctl is-failed application.service # 显示某个 Unit 服务是否建立了启动链接 $ systemctl is-enabled application.service 4.3 Unit 管理对于用户来说,最常用的是下面这些命令,用于启动和停止 Unit(主要是 service)。 # 立即启动一个服务 $ sudo systemctl start apache.service # 立即停止一个服务 $ sudo systemctl stop apache.service # 重启一个服务 $ sudo systemctl restart apache.service # 杀死一个服务的所有子进程 $ sudo systemctl kill apache.service # 重新加载一个服务的配置文件 $ sudo systemctl reload apache.service # 重载所有修改过的配置文件 $ sudo systemctl daemon-reload # 显示某个 Unit 的所有底层参数 $ systemctl show httpd.service # 显示某个 Unit 的指定属性的值 $ systemctl show -p CPUShares httpd.service # 设置某个 Unit 的指定属性 $ sudo systemctl set-property httpd.service CPUShares=500 4.4 依赖关系Unit 之间存在依赖关系:A 依赖于 B,就意味着 Systemd 在启动 A 的时候,同时会去启动 B。
$ systemctl list-dependencies nginx.service 上面命令的输出结果之中,有些依赖是 Target 类型(详见下文),默认不会展开显示。如果要展开 Target,就需要使用 $ systemctl list-dependencies --all nginx.service 五、Unit 的配置文件5.1 概述每一个 Unit 都有一个配置文件,告诉 Systemd 怎么启动这个 Unit 。 Systemd 默认从目录
$ sudo systemctl enable clamd@scan.service # 等同于 $ sudo ln -s '/usr/lib/systemd/system/clamd@scan.service' '/etc/systemd/system/multi-user.target.wants/clamd@scan.service' 如果配置文件里面设置了开机启动, 与之对应的, $ sudo systemctl disable clamd@scan.service 配置文件的后缀名,就是该 Unit 的种类,比如 5.2 配置文件的状态
# 列出所有配置文件 $ systemctl list-unit-files # 列出指定类型的配置文件 $ systemctl list-unit-files --type=service 这个命令会输出一个列表。 $ systemctl list-unit-files UNIT FILE STATE chronyd.service enabled clamd@.service static clamd@scan.service disabled 这个列表显示每个配置文件的状态,一共有四种。
注意,从配置文件的状态无法看出,该 Unit 是否正在运行。这必须执行前面提到的 $ systemctl status bluetooth.service 一旦修改配置文件,就要让 SystemD 重新加载配置文件,然后重新启动,否则修改不会生效。 $ sudo systemctl daemon-reload $ sudo systemctl restart httpd.service 5.3 配置文件的格式配置文件就是普通的文本文件,可以用文本编辑器打开。
$ systemctl cat atd.service [Unit] Description=ATD daemon [Service] Type=forking ExecStart=/usr/bin/atd [Install] WantedBy=multi-user.target 从上面的输出可以看到,配置文件分成几个区块。每个区块的第一行,是用方括号表示的区别名,比如 每个区块内部是一些等号连接的键值对。 [Section] Directive1=value Directive2=value . . . 注意,键值对的等号两侧不能有空格。 5.4 配置文件的区块
Unit 配置文件的完整字段清单,请参考官方文档。 六、Target启动计算机的时候,需要启动大量的 Unit。如果每一次启动,都要一一写明本次启动需要哪些 Unit,显然非常不方便。Systemd 的解决方案就是 Target。 简单说,Target 就是一个 Unit 组,包含许多相关的 Unit 。启动某个 Target 的时候,Systemd 就会启动里面所有的 Unit。从这个意义上说,Target 这个概念类似于 "状态点",启动某个 Target 就好比启动到某种状态。 传统的 # 查看当前系统的所有 Target $ systemctl list-unit-files --type=target # 查看一个 Target 包含的所有 Unit $ systemctl list-dependencies multi-user.target # 查看启动时的默认 Target $ systemctl get-default # 设置启动时的默认 Target $ sudo systemctl set-default multi-user.target # 切换 Target 时,默认不关闭前一个 Target 启动的进程, # systemctl isolate 命令改变这种行为, # 关闭前一个 Target 里面所有不属于后一个 Target 的进程 $ sudo systemctl isolate multi-user.target Target 与 传统 RunLevel 的对应关系如下。 Traditional runlevel New target name Symbolically linked to... Runlevel 0 | runlevel0.target -> poweroff.target Runlevel 1 | runlevel1.target -> rescue.target Runlevel 2 | runlevel2.target -> multi-user.target Runlevel 3 | runlevel3.target -> multi-user.target Runlevel 4 | runlevel4.target -> multi-user.target Runlevel 5 | runlevel5.target -> graphical.target Runlevel 6 | runlevel6.target -> reboot.target 它与 (1)默认的 RunLevel(在 (2)启动脚本的位置,以前是 (3)配置文件的位置,以前 七、日志管理Systemd 统一管理所有 Unit 的启动日志。带来的好处就是,可以只用
# 查看所有日志(默认情况下 ,只保存本次启动的日志) $ sudo journalctl # 查看内核日志(不显示应用日志) $ sudo journalctl -k # 查看系统本次启动的日志 $ sudo journalctl -b $ sudo journalctl -b -0 # 查看上一次启动的日志(需更改设置) $ sudo journalctl -b -1 # 查看指定时间的日志 $ sudo journalctl --since="2012-10-30 18:17:16" $ sudo journalctl --since "20 min ago" $ sudo journalctl --since yesterday $ sudo journalctl --since "2015-01-10" --until "2015-01-11 03:00" $ sudo journalctl --since 09:00 --until "1 hour ago" # 显示尾部的最新10行日志 $ sudo journalctl -n # 显示尾部指定行数的日志 $ sudo journalctl -n 20 # 实时滚动显示最新日志 $ sudo journalctl -f # 查看指定服务的日志 $ sudo journalctl /usr/lib/systemd/systemd # 查看指定进程的日志 $ sudo journalctl _PID=1 # 查看某个路径的脚本的日志 $ sudo journalctl /usr/bin/bash # 查看指定用户的日志 $ sudo journalctl _UID=33 --since today # 查看某个 Unit 的日志 $ sudo journalctl -u nginx.service $ sudo journalctl -u nginx.service --since today # 实时滚动显示某个 Unit 的最新日志 $ sudo journalctl -u nginx.service -f # 合并显示多个 Unit 的日志 $ journalctl -u nginx.service -u php-fpm.service --since today # 查看指定优先级(及其以上级别)的日志,共有8级 # 0: emerg # 1: alert # 2: crit # 3: err # 4: warning # 5: notice # 6: info # 7: debug $ sudo journalctl -p err -b # 日志默认分页输出,--no-pager 改为正常的标准输出 $ sudo journalctl --no-pager # 以 JSON 格式(单行)输出 $ sudo journalctl -b -u nginx.service -o json # 以 JSON 格式(多行)输出,可读性更好 $ sudo journalctl -b -u nginx.serviceqq -o json-pretty # 显示日志占据的硬盘空间 $ sudo journalctl --disk-usage # 指定日志文件占据的最大空间 $ sudo journalctl --vacuum-size=1G # 指定日志文件保存多久 $ sudo journalctl --vacuum-time=1years |
|




网络栈




| 容器核心技术 --Cgroup 与 Namespace - 简书容器的核心技术是 Cgroup + Namespace。 容器 = cgroup + namespace + rootfs + 容器引擎 Cgroup: 资源控制 nam...
0.2482019.02.08 17:02:34 字数 2,113 阅读 3,465 容器的核心技术是 Cgroup + Namespace。 容器 = cgroup + namespace + rootfs + 容器引擎
一、 CgroupCgroup 是 Control group 的简称,是 Linux 内核提供的一个特性,用于限制和隔离一组进程对系统资源的使用。对不同资源的具体管理是由各个子系统分工完成的。
在 Cgroup 出现之前,只能对一个进程做资源限制,如 子系统介绍
cpuset 的主要接口如下:
二、 NamespaceNamespace 是将内核的全局资源做封装,使得每个 namespace 都有一份独立的资源,因此不同的进程在各自的 namespace 内对同一种资源的使用互不干扰。 目前,Linux 内核实现了 6 种 Namespace。
与命名空间相关的三个系统调用:
6 种命名空间
最后,回到 Docker 上,经过上述讨论,namespace 和 cgroup 的使用很灵活,需要注意的地方也很多。 Docker 通过 更新 三、rootfsrootfs 代表一个 Docker 容器在启动时 (而非运行后) 其内部进程可见的文件系统视角,或者叫 Docker 容器的根目录。  Ubuntu 容器文件视角 在容器中修改用户视角下文件时,Docker 借助 COW(copy-on-write) 机制节省不必要的内存分配。 以上。 |
|||||||||||||||||||||||||||||||||||||
Linux 的 Namespace 与 Cgroups 介绍
Namespace 的概念Linux Namespace 是 kernel 的一个功能,它可以隔离一系列系统的资源,比如 PID(Process ID),User ID, Network 等等。一般看到这里,很多人会想到一个命令 比如一家公司向外界出售自己的计算资源。公司有一台性能还不错的服务器,每个用户买到一个 tomcat 实例用来运行它们自己的应用。有些调皮的客户可能不小心进入了别人的 tomcat 实例,修改或者关闭了其中的某些资源,这样就会导致各个客户之间互相干扰。也许你会说,我们可以限制不同用户的权限,让用户只能访问自己名下的 tomcat,但是有些操作可能需要系统级别的权限,比如 root。我们不可能给每个用户都授予 root 权限,也不可能给每个用户都提供一台全新的物理主机让他们互相隔离,因此这里 Linux Namespace 就派上了用场。使用 Namespace, 我们就可以做到 UID 级别的隔离,也就是说,我们可以以 UID 为 n 的用户,虚拟化出来一个 namespace,在这个 namespace 里面,用户是具有 root 权限的。但是在真实的物理机器上,他还是那个 UID 为 n 的用户,这样就解决了用户之间隔离的问题。当然这个只是 Namespace 其中一个简单的功能。 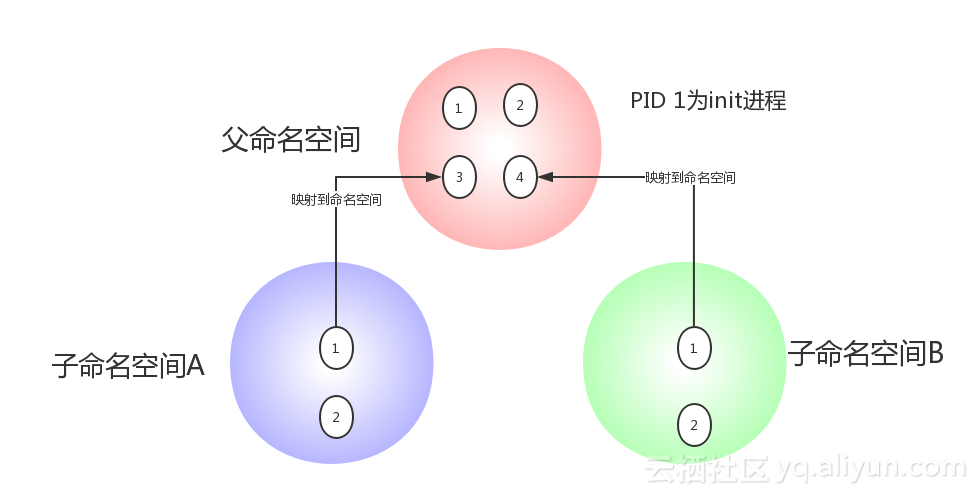 除了 User Namespace ,PID 也是可以被虚拟的。命名空间建立系统的不同视图, 对于每一个命名空间,从用户看起来,应该像一台单独的 Linux 计算机一样,有自己的 init 进程 (PID 为 1),其他进程的 PID 依次递增,A 和 B 空间都有 PID 为 1 的 init 进程,子容器的进程映射到父容器的进程上,父容器可以知道每一个子容器的运行状态,而子容器与子容器之间是隔离的。从图中我们可以看到,进程 3 在父命名空间里面 PID 为 3,但是在子命名空间内,他就是 1. 也就是说用户从子命名空间 A 内看进程 3 就像 init 进程一样,以为这个进程是自己的初始化进程,但是从整个 host 来看,他其实只是 3 号进程虚拟化出来的一个空间而已。 Namespace 是 Linux 内核用来隔离内核资源的方式。通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。 Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。 Namespace 的用途可能绝大多数的使用者和我一样,是在使用 docker 后才开始了解 linux 的 namespace 技术的。实际上,Linux 内核实现 namespace 的一个主要目的就是实现轻量级虚拟化 (容器) 服务。在同一个 namespace 下的进程可以感知彼此的变化,而对外界的进程一无所知。这样就可以让容器中的进程产生错觉,认为自己置身于一个独立的系统中,从而达到隔离的目的。也就是说 linux 内核提供的 namespace 技术为 docker 等容器技术的出现和发展提供了基础条件。  上表中的前六种 namespace 正是实现容器必须的隔离技术,至于新近提供的 Cgroup namespace 目前还没有被 docker 采用。相信在不久的将来各种容器也会添加对 Cgroup namespace 的支持。 Namespace 的发展历史Linux 在很早的版本中就实现了部分的 namespace,比如内核 2.4 就实现了 mount namespace。大多数的 namespace 支持是在内核 2.6 中完成的,比如 IPC、Network、PID、和 UTS。还有个别的 namespace 比较特殊,比如 User,从内核 2.6 就开始实现了,但在内核 3.8 中才宣布完成。同时,随着 Linux 自身的发展以及容器技术持续发展带来的需求,也会有新的 namespace 被支持,比如在内核 4.6 中就添加了 Cgroup namespace。 Linux 提供了多个 API 用来操作 namespace,它们是 clone()、setns() 和 unshare() 函数,为了确定隔离的到底是哪项 namespace,在使用这些 API 时,通常需要指定一些调用参数:CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER、CLONE_NEWUTS 和 CLONE_NEWCGROUP。如果要同时隔离多个 namespace,可以使用 | (按位或) 组合这些参数。同时我们还可以通过 /proc 下面的一些文件来操作 namespace。下面就让让我们看看这些接口的简要用法。 查看进程所属的 Namespace从版本号为 3.8 的内核开始,/proc/[pid]/ns 目录下会包含进程所属的 namespace 信息,使用下面的命令可以查看当前进程所属的 namespace 信息: $ ll /proc/$$/ns  首先,这些 namespace 文件都是链接文件。链接文件的内容的格式为 xxx:[inode number]。其中的 xxx 为 namespace 的类型,inode number 则用来标识一个 namespace,我们也可以把它理解为 namespace 的 ID。如果两个进程的某个 namespace 文件指向同一个链接文件,说明其相关资源在同一个 namespace 中。 $ touch ~/uts $ sudo mount --bind /proc/$$/ns/uts ~/uts 使用 stat 命令检查下结果:  很神奇吧,~/uts 的 inode 和链接文件中的 inode number 是一样的,它们是同一个文件。 ----------------------------------------------------------------------------------------------------------------------------------------------- 上面是构建 Linux 容器的 namespace 技术,它帮进程隔离出自己单独的空间,但 Docker 又是怎么限制每个空间的大小,保证他们不会互相争抢呢?那么就要用到 Linux 的 Cgroups 技术。 Cgroups 概念Cgroups(Control Groups) 是 Linux 内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu,memory,IO 等等)的机制。可以对一组进程及将来的子进程的资源的限制、控制和统计的能力,这些资源包括 CPU,内存,存储,网络等。通过 Cgroups,可以方便的限制某个进程的资源占用,并且可以实时的监控进程的监控和统计信息。最初由 google 的工程师提出,后来被整合进 Linux 内核。Cgroups 也是 LXC 为实现虚拟化所使用的资源管理手段,可以说没有 cgroups 就没有 LXC (Linux Container)。 ask:一个进程 control group:控制组群,按照某种标准划分的进程组 hierarchy:层级,control group 可以形成树形的结构,有父节点,子节点,每个节点都是一个 control group,子节点继承父节点的特定属性。 subsystem:子系统。 子系统就是资源控制器,每种子系统就是一个资源的分配器,比如 cpu 子系统是控制 cpu 时间分配的。 可以使用 lssubsys -all 来列出系统支持多少种子系统,和使用 ls /sys/fs/cgroup/ (ubuntu)来显示已经挂载的子系统:  可以看到这里的几个子系统,比如 cpu 是控制 cpu 时间片的,memory 是控制内存使用的。 Cgroups 可以做什么?Cgroups 最初的目标是为资源管理提供的一个统一的框架,既整合现有的 cpuset 等子系统,也为未来开发新的子系统提供接口。现在的 cgroups 适用于多种应用场景,从单个进程的资源控制,到实现操作系统层次的虚拟化(OS Level Virtualization)。Cgroups 提供了一下功能:
1. 限制进程组可以使用的资源数量(Resource limiting )。比如:memory 子系统可以为进程组设定一个 memory 使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发 OOM(out of memory)。
2. 进程组的优先级控制(Prioritization )。比如:可以使用 cpu 子系统为某个进程组分配特定 cpu share。
3. 记录进程组使用的资源数量(Accounting )。比如:可以使用 cpuacct 子系统记录某个进程组使用的 cpu 时间
4. 进程组隔离(isolation)。比如:使用 ns 子系统可以使不同的进程组使用不同的 namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
5. 进程组控制(control)。比如:使用 freezer 子系统可以将进程组挂起和恢复。
通过 mount -t cgroup 命令或进入 / sys/fs/cgroup 目录,我们看到目录中有若干个子目录,我们可以认为这些都是受 cgroups 控制的资源以及这些资源的信息。
如何为 Cgroup 分配限制的资源首先明白下,是先挂载子系统,然后才有 control group 的。意思就是比如想限制某些进程的资源,那么,我会先挂载 memory 子系统,然后在 memory 子系统中创建一个 cgroup 节点,在这个节点中,将需要控制的进程 id 写入,并且将控制的属性写入。 1、以 memory 子系统为例:进入 / sys/fs/cgroup/memory 这个目录,我们创建一个 test 文件夹就相当于创建了一个 control group 了,进入 test 目录,你会发现 test 目录下自动创建了许多文件 这些文件的含义如下:  于是,限制内存使用我们就可以设置 memory.limit_in_bytes 将一个进程 ID 加入到这个 test 中: echo $$ > tasks 这样就将当前这个终端进程加入到了内存限制的 cgroup 中了,如果需要删除 cgroup 只要删除刚创建的目录就可以了。 2、以 CPU 子系统为例:跑一个耗费 cpu 的脚本 x=0
while [ True ];do
x=$x+1
done;
用 top 命令可以看到这个脚本基本占了 100% 的 cpu 资源 下面用 cgroups 控制这个进程的 cpu 资源 mkdir -p /sys/fs/cgroup/cpu/hello/ #新建一个控制组hello echo 50000 > /sys/fs/cgroup/cpu/hello/cpu.cfs_quota_us #将cpu.cfs_quota_us设为50000,相对于cpu.cfs_period_us的100000是50% echo "$PID" > /sys/fs/cgroup/cpu/hello/tasks 然后观察 top 的实时统计数据,会发现 cpu 占用率将近 50%,看来 cgroups 关于 cpu 的控制起了效果。 |





run time:






