Python爬虫,爬取58租房数据
这俩天项目主管给了个爬虫任务,要爬取58同城上福州区域的租房房源信息。因为58的前端页面做了base64字体加密所以爬取比较费力,前前后后花了俩天才搞完。
项目演示与分析
使用python的request库和字体反爬文件,通过替换来实现爬取,最后保存 为excel文件
演示: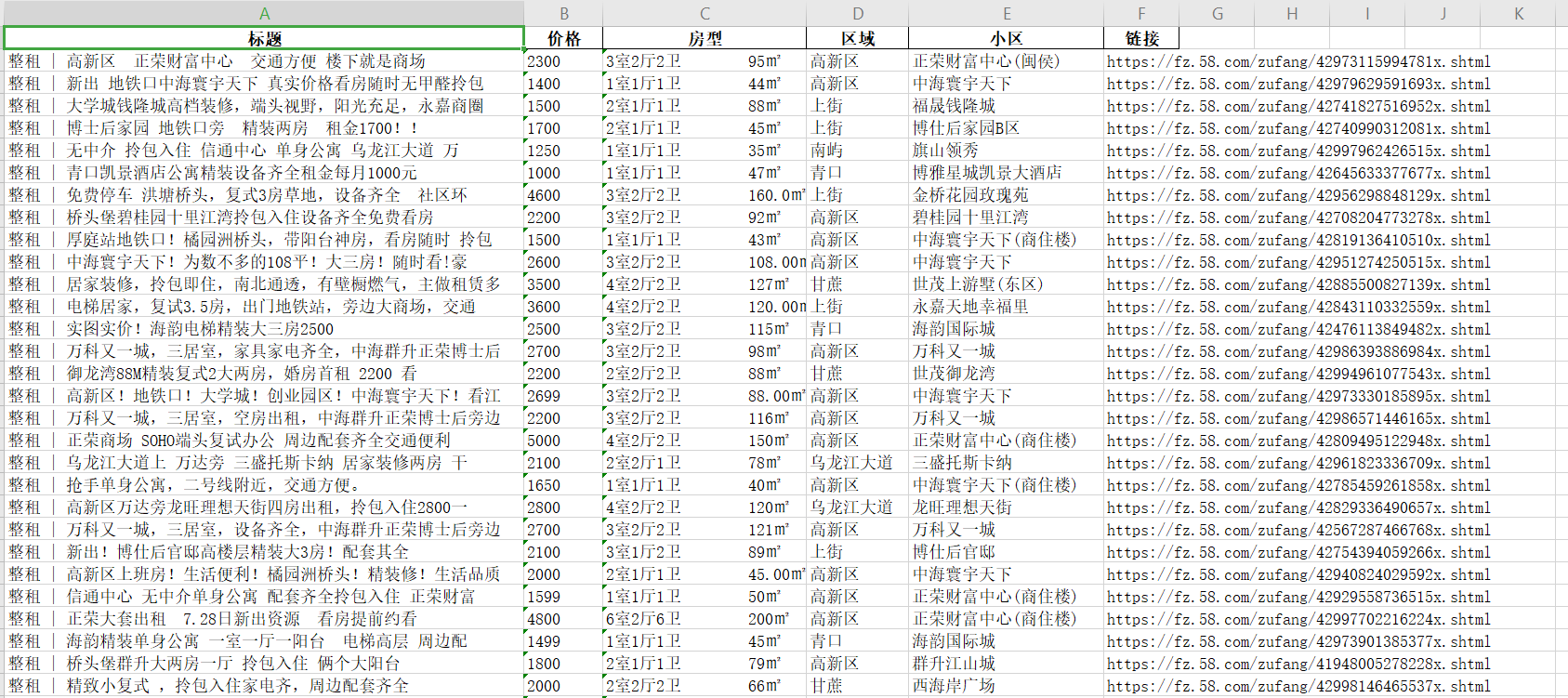
分析:
1.首先 直接从58爬取数据可以很明显的看到所有的数字都被替换成了乱码

2.我们打开页面右键点击查看源代码,可以发现所有的数字都变成了一串诡异的编码,而这些编码似乎又存在某种联系

3.我们翻到代码的最前端发现一连串的字母,这些其实就是base64加密后的字体文件信息,可以进行正则匹配提取,然后解码写入字体文件。

4.我们通过输出.xml和字体库文件可以分析编码规律
import requestsimport refrom fontTools.ttLib import TTFont#下载字体文件url="https://fz.58.com/chuzu/pn1"
response = requests.get(url=url.format(page=1),headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'})
font_base64 = re.findall("base64,(AA.*AAAA)", response.text)[0] # 找到base64编码的字体格式文件
font = base64.b64decode(font_base64)
with open('ztk01.ttf', 'wb') as tf:
tf.write(font)font_object = TTFont('58font2.ttf')font_object.saveXML('58font2.xml')
5.通过对比字体库文件和输出的xml内容,glyph00007对应6,glyph00006对应5。可以很明显的发现规律:对每一个glyph0000x对应数字x-1

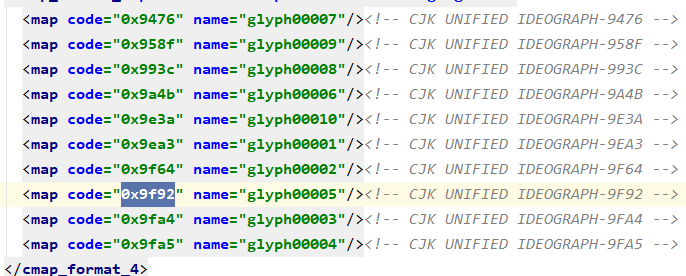
因此只需要将下载的网页中的 乱码内容替换为相应的数字即可,需要运用到fontTools模块,具体代码如下
def convertNumber(html_page):
base_fonts = ['uni9FA4', 'uni9F92', 'uni9A4B', 'uni9EA3', 'uni993C', 'uni958F', 'uni9FA5', 'uni9476', 'uni9F64',
'uni9E3A']
base_fonts2 = ['&#x' + x[3:].lower() + ';' for x in base_fonts] # 构造成 鸺 的形式
pattern = '(' + '|'.join(base_fonts2) + ')' #拼接上面十个字体编码
font_base64 = re.findall("base64,(AA.*AAAA)", response.text)[0] # 找到base64编码的字体格式文件
font = base64.b64decode(font_base64)
with open('58font2.ttf', 'wb') as tf:
tf.write(font)
onlinefont = TTFont('58font2.ttf')
convert_dict = onlinefont['cmap'].tables[0].ttFont.tables['cmap'].tables[0].cmap # convert_dict数据如下:{40611: 'glyph00004', 40804: 'glyph00009', 40869: 'glyph00010', 39499: 'glyph00003'
new_page = re.sub(pattern, lambda x: getNumber(x.group(),convert_dict), html_page)
return new_page
def getNumber(g,convert_dict):
key = int(g[3:7], 16) # '麣',截取后四位十六进制数字,转换为十进制数,即为上面字典convert_dict中的键
number = int(convert_dict[key][-2:]) - 1 # glyph00009代表数字8, glyph00008代表数字7,依次类推
return str(number)
通过xpath路径解析h5代码,并存入字典
itle = li_tag.xpath('.//div[@class="des"]/h2/a/text()')[0].strip()
room = li_tag.xpath('.//p[@class="room"]/text()')[0].replace('
', '').replace(r' ', '')
price = li_tag.xpath('.//div[@class="money"]//b/text()')[0].strip().replace('
', '').replace(r' ', '')
url = li_tag.xpath('.//div[@class="des"]/h2/a/@href')[0]
url = re.sub(r'?.*', '', url)
place=li_tag.xpath('.//p[@class="infor"]/a/text()')[0].replace('
', '').replace(r' ', '')
if('.//p[@class="infor"]/a/text()'==None):
break
xiaoqu = li_tag.xpath('.//p[@class="infor"]/a/text()')[1].replace('
', '').replace(r' ', '')
i = i + 1
number=number+1
print(title, room, price, url,place,xiaoqu,number)
shuju.append({"title":title,"room":room,"price":price,"url":url,"place":place,"xiaoqu":xiaoqu})
最后封装成excel导入数据
pf=pd.DataFrame(list(all_datas))
order=['title','price','room','place','xiaoqu','url']
pf=pf[order]
columns_map = {
'title':'标题',
'price':'价格',
'room':'房型',
'place': '区域',
'xiaoqu':'小区',
'url':'链接'
}
pf.rename(columns = columns_map,inplace = True)
file_path = pd.ExcelWriter('15.xlsx')
pf.fillna(' ',inplace = True)
pf.to_excel(file_path,encoding = 'utf-8',index = False)
file_path.save()
整体代码:
import requests
import re
import base64
import time
import xlwt
import pandas as pd
import random
from bs4 import BeautifulSoup
from fontTools.ttLib import TTFont
from io import BytesIO
from lxml import etree, html
def getNumber(g,convert_dict):
key = int(g[3:7], 16) # '麣',截取后四位十六进制数字,转换为十进制数,即为上面字典convert_dict中的键
number = int(convert_dict[key][-2:]) - 1 # glyph00009代表数字8, glyph00008代表数字7,依次类推
return str(number)
htmls=[]
headers={
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36',
}
def p(htmls):
print(htmls)
result = re.search(r"base64,(.*?))", htmls, flags=re.S).group(1)
b = base64.b64decode(result)
tf = TTFont(BytesIO(b))
convert_dict = tf['cmap'].tables[0].ttFont.tables['cmap'].tables[0].cmap
base_fonts = ['uni9FA4', 'uni9F92', 'uni9A4B', 'uni9EA3', 'uni993C', 'uni958F', 'uni9FA5', 'uni9476', 'uni9F64',
'uni9E3A']
base_fonts2 = ['&#x' + x[3:].lower() + ';' for x in base_fonts] # 构造成 鸺 的形式
pattern = '(' + '|'.join(base_fonts2) + ')'
new_page = re.sub(pattern, lambda x: getNumber(x.group(), convert_dict), htmls)
data = html.fromstring(new_page)
li_tags = data.xpath('//ul[@class="house-list"]/li')
i = 0
number=0
shuju = []
for li_tag in li_tags:
if(i>32):
break
title = li_tag.xpath('.//div[@class="des"]/h2/a/text()')[0].strip()
room = li_tag.xpath('.//p[@class="room"]/text()')[0].replace('
', '').replace(r' ', '')
price = li_tag.xpath('.//div[@class="money"]//b/text()')[0].strip().replace('
', '').replace(r' ', '')
url = li_tag.xpath('.//div[@class="des"]/h2/a/@href')[0]
url = re.sub(r'?.*', '', url)
place=li_tag.xpath('.//p[@class="infor"]/a/text()')[0].replace('
', '').replace(r' ', '')
if('.//p[@class="infor"]/a/text()'==None):
break
xiaoqu = li_tag.xpath('.//p[@class="infor"]/a/text()')[1].replace('
', '').replace(r' ', '')
i = i + 1
number=number+1
print(title, room, price, url,place,xiaoqu,number)
shuju.append({"title":title,"room":room,"price":price,"url":url,"place":place,"xiaoqu":xiaoqu})
return shuju
index=0
for idx in range(3):
url=f"https://fz.58.com/chuzu/pn{idx+1}"
#if(index>5):
# index=0
# time.sleep(30)
#url = f"https://nj.58.com/pinpaigongyu/pn/{idx + 1}"
print(url)
r=requests.get(url,headers=headers)
r.encoding='utf-8'
if r.status_code!=200:
raise Exception("error")
htmls.append(r.text)
index=index+1
all_datas=[]
o=0
for ht in htmls:
o=o+1
all_datas.extend(p(ht))
print(o)
print(all_datas)
pf=pd.DataFrame(list(all_datas))
order=['title','price','room','place','xiaoqu','url']
pf=pf[order]
columns_map = {
'title':'标题',
'price':'价格',
'room':'房型',
'place': '区域',
'xiaoqu':'小区',
'url':'链接'
}
pf.rename(columns = columns_map,inplace = True)
file_path = pd.ExcelWriter('15.xlsx')
pf.fillna(' ',inplace = True)
pf.to_excel(file_path,encoding = 'utf-8',index = False)
file_path.save()