作者:天山老妖S
链接:http://blog.51cto.com/9291927
一、索引简介
1、索引简介
索引(Index)是帮助MySQL高效获取数据的数据结构。
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的。MyISAM和InnoDB存储引擎只支持BTREE索引,MEMORY/HEAP存储引擎支持HASH和BTREE索引。
2、索引的优点
A、提高数据检索效率,降低数据库的IO成本。
B、通过索引对数据进行排序,降低数据排序的成本降低了CPU的消耗。
C、大大加快数据的查询数据。
3、索引的缺点
A、创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加
B、索引也需要占空间,我们知道数据表中的数据也会有最大上线设置的,如果我们有大量的索引,索引文件可能会比数据文件更快达到上线值
C、当对表中的数据进行增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度。
4、索引的使用原则
A、主键自动建立唯一索引
B、频繁作为查询条件的字段应该创建索引
C、查询中与其他表关联的字段,外键关系建立索引
D、频繁更新的字段不适合建立索引,因为每次更新不单单是更新了记录还会更新索引
E、WHERE条件里用不到的字段不创建索引
F、单键/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
G、查询中排序的字段,排序的字段若通过索引去访问将大大提高排序速度
H、查询中统计或者分组字段
不适合使用索引的场合:
A、对经常更新的表就避免对其进行过多的索引,对经常用于查询的字段应该创建索引。
B、数据量小的表最好不要使用索引,由于数据较少,可能查询全部数据花费的时间比遍历索引的时间还要短,索引就可能不会产生优化效果。
C、在不同值少的列上不要建立索引,比如在学生表的"性别"字段上只有男,女两个不同值。在一个不同值较多的列可以建立索引。
二、索引的分类
1、单列索引
单列索引只包含单个列,但一个表中可以有多个单列索引。
A、普通索引
普通索引允许在定义索引的列中插入重复值和空值。
B、唯一索引
索引列中的值必须是唯一的,但是允许为空值。
C、主键索引
主键索引是一种特殊的唯一索引,不允许有空值。
2、复合索引
在表中的多个字段组合上创建的索引,只有在查询条件中使用了组合的多个字段的左边字段时,索引才会被使用,使用复合索引时遵循最左前缀集合。
3、全文索引
全文索引,只有MyISAM存储引擎支持,只能在CHAR、VARCHAR、TEXT类型字段上使用全文索引。
全文索引主要用来查找文本中的关键字,而不是直接与索引中的值相比较。在数据量较大时候,先将数据放入一个没有全文索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多。
4、空间索引
空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有四种:GEOMETRY、POINT、LINESTRING、POLYGON。
在创建空间索引时,使用SPATIAL关键字。
空间索引必须使用MyISAM存储引擎,并且空间索引的字段必须为非空。
三、索引的操作
1、索引的创建
创建表时创建索引的语法:
CREATE TABLE table_name[col_name data type] [UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [index_name] (col_name[length]) [asc|desc]
在表上创建索引的语法:
ALTER TABLE tablename ADD [UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [indexname] (col_name) [ASC|DESC]; CREATE [UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] indexname ON tablename(col_name[length]) [ASC|DESC];
uniquer|fulltext为何选参数,分别表示唯一索引、全文索引
col_name为需要创建索引的字段列,该列必须从数据表中该定义的多个列中选择
index_name指定索引的名称,为可选参数,如果不指定,默认col_name为索引值
length为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度
asc或desc指定升序或降序的索引值存储
在创建索引时如果不指定索引名,默认使用字段名索引名。
2、普通索引的创建
直接创建索引
CREATE INDEX index_name ON tablename(column(length))
修改表结构
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
创建表时指定索引
CREATE TABLE tablename
(
col_name1 type,
col_name2 type,INDEX index_name(col_name)
);3、唯一索引的创建
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
直接创建唯一索引
CREATE UNIQUE INDEX indexName ON tablename(column(length))
修改表结构
ALTER TABLE table_name ADD UNIQUE indexName ON (column(length))
创建表时直接指定
CREATE TABLE tablename
(
col_name1 type,
col_name2 type,UNIQUE INDEX index_name(col_name)
);4、主键索引的创建
修改表结构
ALTER TABLE table_name ADD PRIMARY KEY(col_name)
创建表时直接指定
CREATE TABLE tablename
(
col_name1 type,
col_name2 type,
PRIMARY KEY(col_name)
);5、复合索引的创建
直接创建复合索引
CREATE INDEX indexName ON tablename(col_name1,col_name2)
创建表时直接指定
CREATE TABLE tablename
(
col_name1 type,
col_name2 type,INDEX index_name(col_name1,col_name2)
);6、全文索引的创建
直接创建全文索引
CREATE FULLTEXT INDEX indexName ON tablename(col_name)
修改表结构
ALTER TABLE table_name ADD FULLTEXT INDEX indexName(col_name)
创建表时直接指定
CREATE TABLE tablename
(
col_name1 type,
col_name2 type,
FULLTEXT INDEX index_name(col_name)
);在使用全文索引时,需要借助MATCH AGAINST操作,而不是一般的WHERE语句加LIKE。全文索引的限制比较多,比如只能使用MyISAM存储引擎,比如只能在CHAR、VARCHAR、TEXT上设置全文索引。比如索引的关键字默认至少要4个字符,比如搜索的关键字太短就会被忽略掉。
SELECT * FROM tablename WHERE MATCH(col_name) AGAINST('pattern');
col_name为全文索引列,'pattern'为匹配的字符串
7、索引的删除
DROP INDEX [indexName] ON tablename;
ALTER TABLE tablename DROP INDEX indexname;
8、索引信息的查看
SHOW INDEX FROM table_name;
9、索引的注意事项
A、索引不会包含有null值的列
在数据库设计时不要让字段的默认值为null。
B、使用短索引
C、索引列排序
因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
D、like语句操作
一般情况下不推荐使用like操作,如果非使用不可。like"%aaa%不会使用索引而like"aaa%"可以使用索引。
E、不要在列上进行运算
在索引列上进行运算将导致索引失效而进行全表扫描例如
SELECT * FROM table_name WHERE YEAR(column_name)<2017;
F、不使用not in和<>操作
四、索引查询速度比较
1、插入记录
create procedure addStudent(in num int)
begin
declare i int;
set i=1;delete from TStudent;while num>=i doinsert TStudent values (
LPAD(convert(i,char(10)),10,'0'),
CreateName(), if(ceil(rand()*10)%2=0,'男','女'),
RPAD(convert(ceil(rand()*1000000000000000000),char(18)),18,'0'),
Concat(convert(ceil(rand()*10)+1980,char(4)),'-',LPAD(convert(ceil(rand()*12),char(2)),2,'0'),'-',LPAD(convert(ceil(rand()*28),char(2)),2,'0')),
Concat(PINYIN(sname),'@hotmail.com'),
case ceil(rand()*3) when 1 then '网络与网站开发' when 2 then 'JAVA' ELSE 'NET' END,
NOW()
);
set i=i+1;
end while;select * from TStudent;
end修改addStuent存储过程,插入500000条记录
call addStudent(500000);
SQL语句查询xxx号cardID以12345开头的学生。
select * from TStudent where cardID like '12345%'
花费时间为1.27秒
2、给XXX列添加索引
alter table TStudnet add index cardidIndex(cardID);
SQL查询xxx号cardID以12345开头的学生。
select * from TStudent where cardID like'12345%'
花费时间31毫秒。
3、查看索引占用的磁盘空间
schoolDB数据库索引占用的磁盘空间。
SELECT CONCAT(ROUND(SUM(index_length)/(1024*1024), 2), ' MB')
AS 'Total Index Size' FROM information_schema.TABLESWHERE table_schema LIKE 'schoolDB'; 查看schoolDB数据库数据占用的磁盘空间。
SELECT CONCAT(ROUND(SUM(data_length)/(1024*1024), 2), ' MB')
AS 'Total Data Size' FROM information_schema.TABLES WHERE table_schema LIKE 'schoolDB';4、查看SQL语句执行计划
EXPLAIN可以查看SQL查询语句的查询计划,使用索引还是全表扫描,key显示使用的索引。
explain select * from TStudent where cardid like '12345%' G;
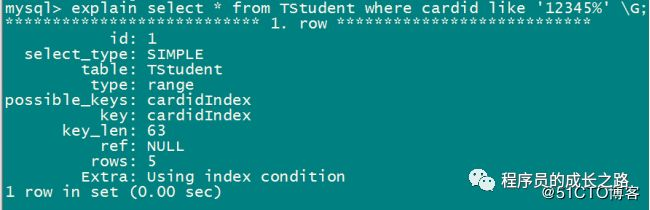
id:SELECT识别符,即SELECT的查询序列号,一条语句中,select是第几次出现。
select_type:所使用的SELECT查询类型,SIMPLE表示为简单的SELECT,不实用UNION或子查询。其他取值,PRIMARY:最外面的SELECT在拥有子查询时,就会出现两个以上的SELECT。UNION:union(两张表连接)中的第二个或后面的select语句 SUBQUERY:在子查询中,第二SELECT。
table:数据表的名字。按被读取的先后顺序倒序排列。
type:指定本数据表和其他数据表之间的关联关系,表中所有符合检索值的记录都会被取出来和从上一个表中取出来的记录做联合。ref用于连接程序使用键的最左前缀或者键不是primary key或unique索引的情况。取值有system、const、eq_ref、index和AII。
possible_keys:MySQL在搜索数据记录时可以选用的各个索引
key:实际选用的索引
key_len:显示MySQL使用索引的长度(使用的索引个数),当key字段的值为null时,索引的长度就是null。
ref:给出关联关系中另一个数据表中数据列的名字。
rows:MySQL在执行查询时预计会从数据表里读出的数据行的个数。
extra:提供与关联操作有关的信息。
五、覆盖索引
1、覆盖索引
一个包含查询所需的字段的索引称为覆盖索引(covering index)。MySQL只需要通过索引就可以返回查询所需要的数据,而不必在查到索引之后进行回表操作,减少IO,提供效率。
通过EXPLAIN查看SQL语句的执行计划时,说明SQL查询使用覆盖索引。
2、使用覆盖索引的SQL语句
Tstudent表cardID列创建了索引,SQL语句查找的列是cardID,就会使用cardID索引进行查找,不需要扫描表的页。
explain select sname from TStudent where sname like '刘%';
执行结果Extra出现using index,说明是使用覆盖索引查找。
3、使用覆盖索引实现order by排序
在MySQL中的ORDER BY有两种排序实现方式:
A、利用有序索引获取有序数据
B、文件排序
使用EXPLAIN分析SQL查询时,利用有序索引获取有序数据显示Using index。而文件排序显示Using filesort。
explain select email from TStudent order by email;
email列没有索引,SQL语句的查询计划可以看到Extra是using filesort,说明是将结果在内存中排序,需要额外时间开销。
给Email列添加索引后,
alter table TStudent add index emailIndex(email);explain select email from TStudent order by email;
再次执行,可以看到Extra列是Using index,说明使用索引排序,没有额外时间开销。
喜欢的小伙伴们可以搜索我们个人的微信公众号“程序员的成长之路”点击关注或扫描下方二维码
