https://github.com/czl411/Pigtails
| 姓名 | 分工 | 博客链接 |
|---|---|---|
| 陈志良 | 前端,后端 | |
| 赵威威 | PS,原型设计,AI算法 | https://www.cnblogs.com/XINJIUXJ/p/15451820.html |
一、原型设计
1.设计说明
原型链接:https://modao.cc/app/43d227cc2388b75c1e60a0eed60d869c1bfcc2c7
原型设计参考欢乐斗地主游戏,利用原型开发工具墨刀,总共实现了四大模块:单机模式,联机模式,关于游戏,更多模式。
设计前期,我们多次对原型的UI界面进行设计,但都达不到想要的效果。为了保证项目开发进度和效率,我们先设计出了低保真的原型,将其基本基本功能和逻辑在原型中完善,界面设计方面则一律从简。
- 欢迎界面:用户点击任意键进入主页面

- 主页面:包含五个模块,单机模式,联机模式,更多模式,退出游戏,关于游戏。
其中单机模式包含PVP,PVE两大模块。
联机模式包含PVP,EVE两大模块。

- 选择界面:用户根据自己的需求选择PVP(双人对战),PVE(人机对战)模块

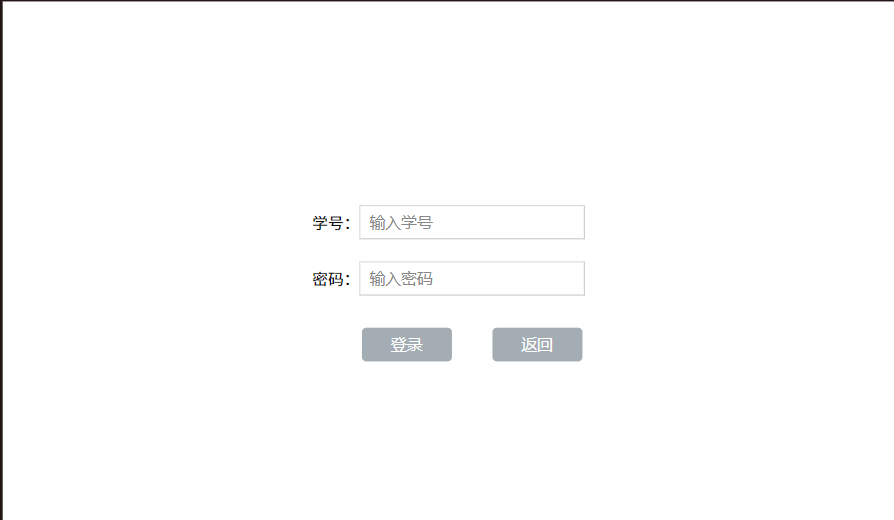
- 登录界面:如果用户选择联机模式,则进入登录界面,登录账号密码,即可进行在线对战。
- 游戏界面:用户进入游戏界面,开始对战。

- 关于游戏:用户点击此页面将会显示关于猪尾巴游戏的说明,帮助玩家获得更好的游戏体验。

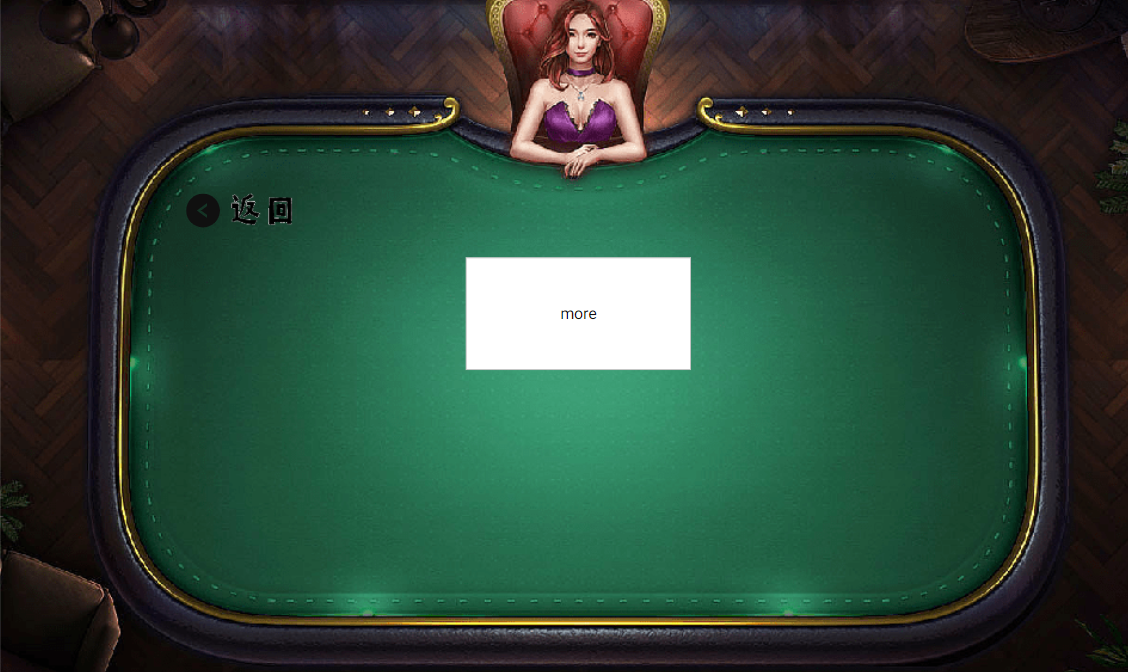
- 更多模式:此页面主要是用于存储将来开发的新的模式。
- 设置:此页面主要有设置音量大小,调整音效功能。

2.遇到的困难及解决方法
| 困难 | 解决方法 |
|---|---|
| 对原型设计工具使用不熟练 | 跟着B站学习墨刀教程 |
| 界面的UI素材很难找 | 从零开始学习PS,最终P出了所有界面 |
| 设计前期对原型设计没有头绪 | 参考欢乐斗地主的原型设计,在此基础上进行改动 |
| 前期不知道原型要设计到哪种程度 | 在查资料的过程中,看到其他程序员的回答,于是决定做低保真原型,最后琢磨界面 |
3.收获
- 学会了PS的一部分技能
- 能较为熟练使用原型设计工具墨刀
- 审美有一定的提升
- 思路真的很重要,确定思路再写代码才能保证高效率
- 做事情分清主次,明白自己想做什么,要做什么,再去做
- 一定要学会使用搜索引擎和Github
- 解决问题的能力有所提升
- debug的能力大幅度增加
- 对做项目和人工智能有了更加深刻的了解
- 对自己的能力有了更深刻的认识
二、原型设计实现
1.代码实现思路
- 网络接口的使用
通过利用python的request库的函数来实现,总体几个模块如下:

接口方面根据接口返回的数据处理和判断实现对程序状态做不同处理,以登录接口例子。若请求成功,返回的数据中‘message’=success,则登陆成功,弹出成功窗口,若失败弹出失败窗口,并且显示信息。其他接口如是。
def Login(id,pwd):
url="http://172.17.173.97:8080/api/user/login"
data = {
"student_id": id,
"password": pwd
}
res = requests.post(url, data).json()
if res["message"]=="Success":
token = res["data"]["token"]
token = "Bearer " + token
header = {
"Authorization": token
}
return (1,header)
else:
return (0,"NULL")
- 代码组织与内部实现设计
这个游戏的话,对于单机使用单线程其实对于用户体验感没影响,但是对于联机,因为需要发送请求,所以就得等待,所以单线程就体验感较差,对于用户的感觉会是一卡一卡的,但因时间关系,就没有改成双线程,就用单线程搞了(后面才想到双线程)。
对于这个游戏的页面实现,是通过pygame库以及tkinter库实现的:
对于每一个界面都设计成一个单独的类,分开写,当需要界面切换时,通过调用类来实现页面的切换。
举一个游戏主页面作为例子来讲解我的界面实现代码:
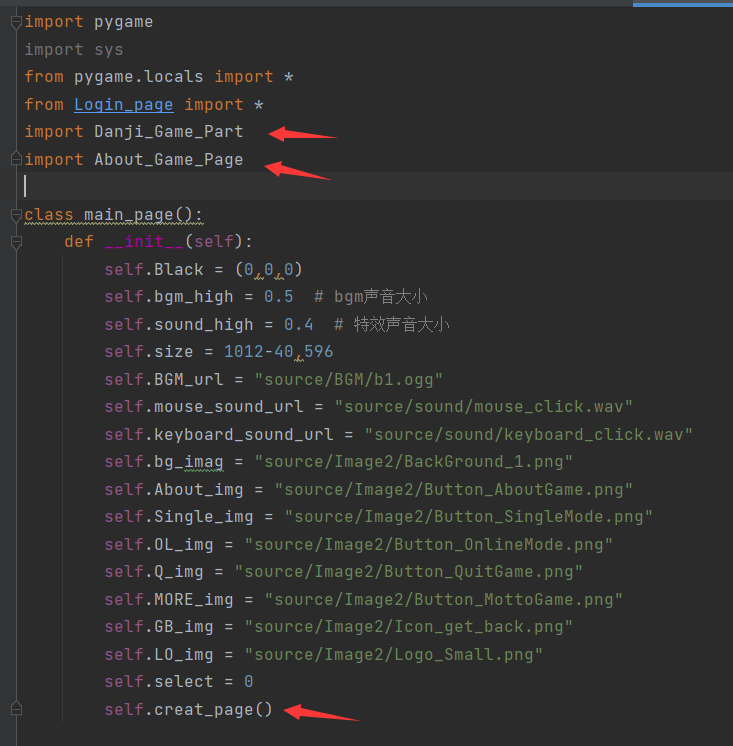
上面俩个箭头就是我说的我自己的页面类函数引入,需要的时候调用里面的类即可。
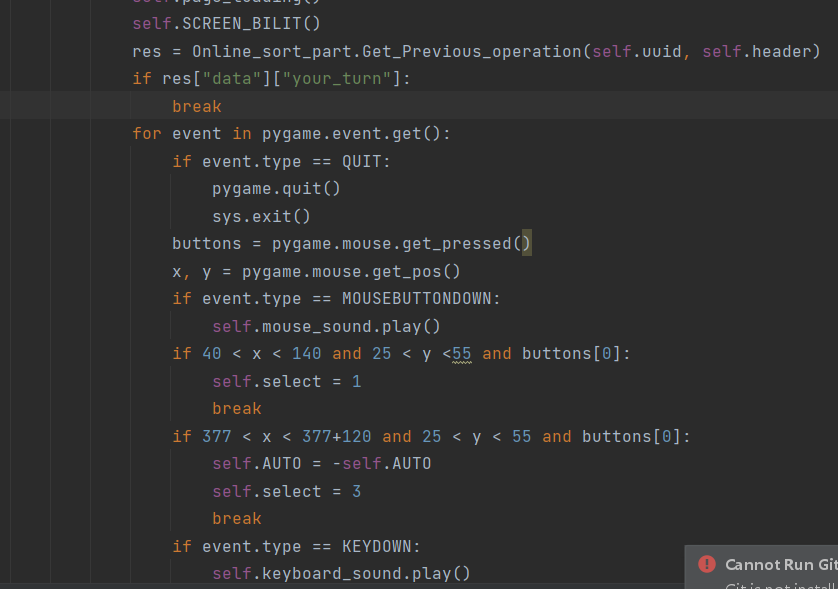
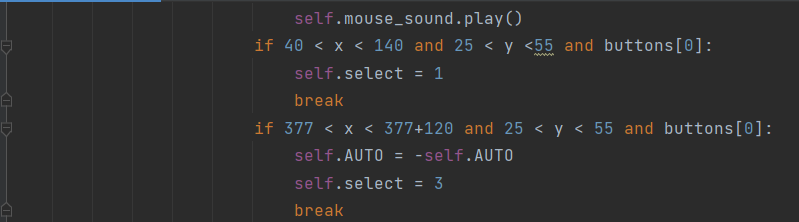
注意下面的主页面的初始化,上面一堆都只是他的属性,最下面一个就是页面的绘画。由于绘画界面代码较长,我这边就不全截图出来了,就截图我处理鼠标点击页面,产生页面切换的的代码。
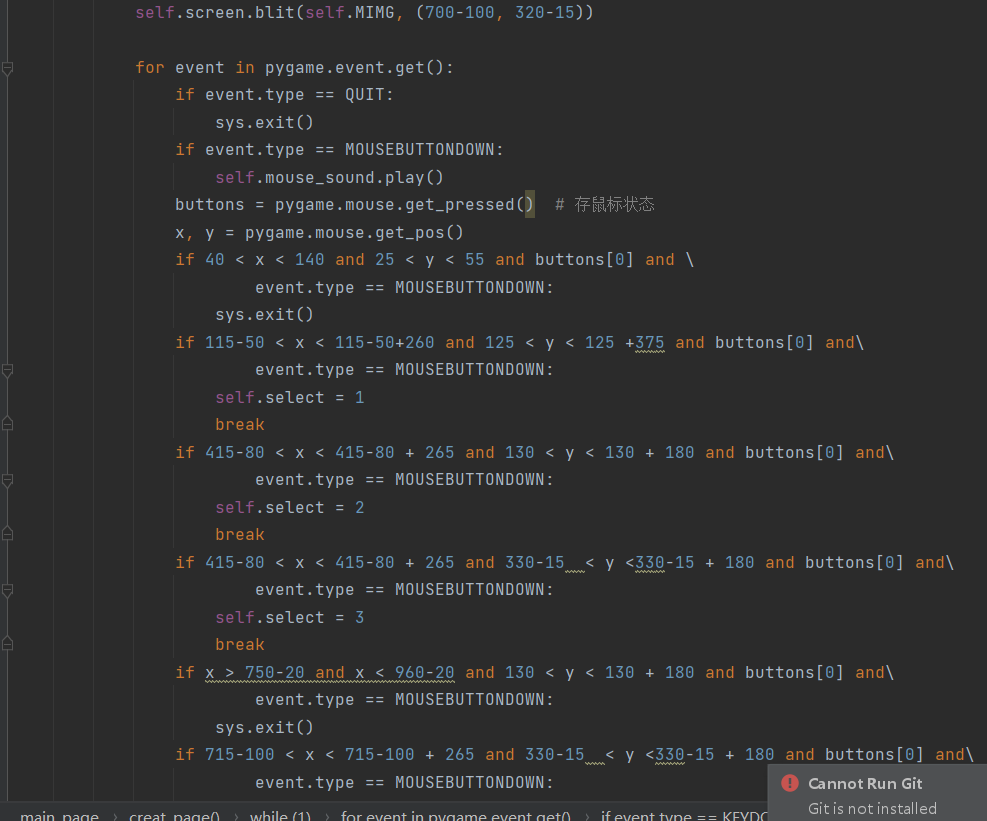

我通过pygame.event.get函数来获取,一个帧内,用户操作的所有数据,对于一组数据,循环判断的操作对应的何种具体的操作,若匹配到,跳出for循环(只要第一次有效操作),执行操作。For循环外套一个while,用于实现页面的刷新。
上面截图的代码,是我页面实现的重要代码。
对于联机,由于是单线程,所以发送请求与获取页面操作不能同时进行,所以初版,我把获取请求和页面操作分开,请求在前,获取界面操作信息在后,延迟贼高,而且获取页面操作信息的时间也特别的短,这需要你重复快速的点击,才能操作成功。因此,改进了获取操作部分,只要获取一次有效即可,不要遍历完整个操作数据信息,加快了反应,增加了体验感。
- 说明算法的关键与关键实现部分流程图

AI方面:
算法流程图:
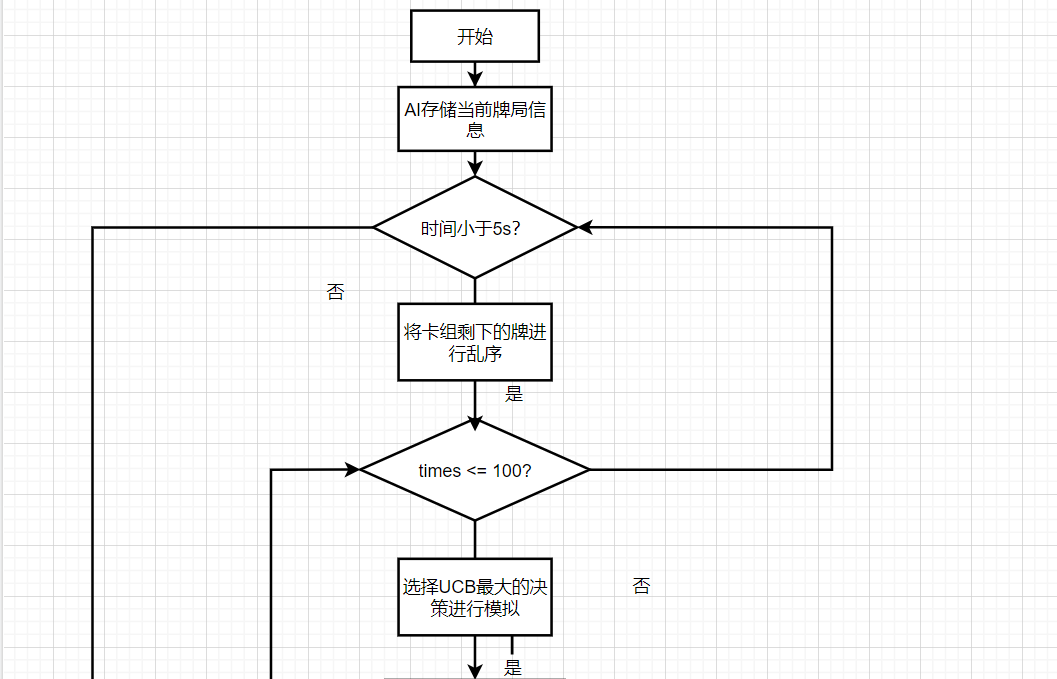
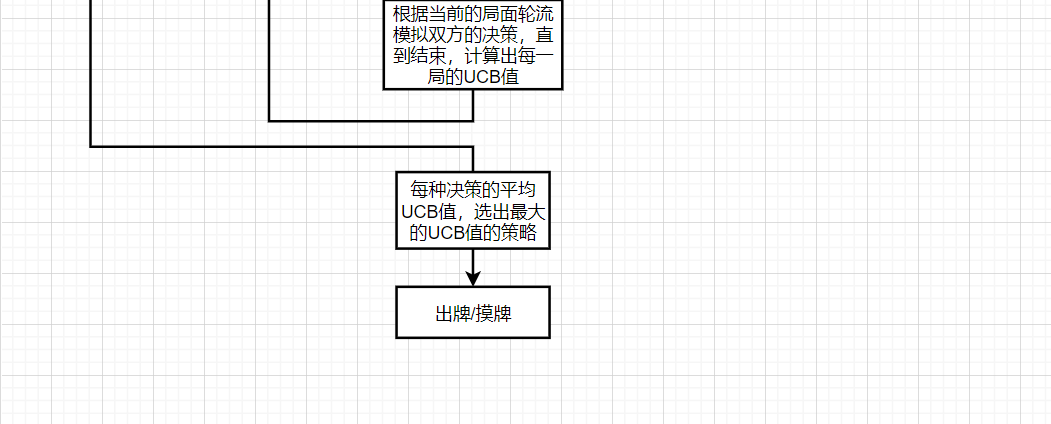
在项目前期,对算法这方面完全没有概念,后来经过查找资料了解了mcts算法。
在这边给大家放个有关mcts的算法知识链接:https://blog.csdn.net/qq_34470213/article/details/79490534
算法实现的关键:
mcts搜索树是本质是启发式搜索,经过一定的策略使得搜索空间减少。但是由于猪尾巴游戏有52张牌。即使mcts可以实现搜索,其空间复杂度和时间复杂度也很大。
因此,在mcts思想的基础上我们想出了自己的AI算法:对于当前局面而言,我们队卡组剩余的牌堆进行乱序。假定剩下的牌的顺序就是乱序后的顺序,对于当前这个确定的顺序,我们对双方对战模拟100次:在模拟过程中,第一步先选择UCB最大的策略,然后双方按照一定的策略轮流对战,在模拟一局结束后记录下Q值与n值,我们定义Q值表示对手的手牌数-自己的手牌数。通过这个思想,不断模拟对局,得到一个较优的策略。
- 贴出你认为重要的/有价值的代码片段,并解释
AI方面:
def ai(Cards, P, Place_Area): # 当前卡组, 两个玩家的状态, 当前放置堆的状态
tot = 0
ans = {}
ans_tot = {}
ans_choice = ['C', 'D', 'H', 'S', 5]
for i in ans_choice:
ans_tot[i] = int(0)
ans[i] = int(0)
ti = float(format(time.process_time()))
# print("time=", ti)
ti_now = float(format(time.process_time()))
dechoice = ['C', 'D', 'H', 'S', 5] # 1:C, 2:D, 3:H 4:S, 5:摸牌
dechoice = judge(P[1], dechoice) # 对UCB进行初始化
while ti < ti_now + 5:
_vir_card = Card_zu()
_vir_card.sum = Cards.sum
for j in Cards.card:
_vir_card.card.append(j) # 将现在卡组的情况赋值给vir_card,得到卡组区卡牌信息
r.shuffle(_vir_card.card) # 在5s内对牌面进行乱序
# 现在牌面确定
tot += 1
choice = ['C', 'D', 'H', 'S', 5] # 1:C, 2:D, 3:H 4:S, 5:摸牌
choice = judge(P[1], choice) # 筛选可以进行的choice
# print(choice)
UCB = {} # 初始化UCB
for j in choice:
UCB[j] = [0, 0]
# operation = -1
ai_times = 100
for i in range(1, ai_times + 1): # 对每个确定的牌面模拟1000次对局
vir_card = Card_zu() # 给虚拟卡组赋值
vir_card.sum = _vir_card.sum
for j in _vir_card.card:
vir_card.card.append(j)
vir_area = Placement_Area() # 给虚拟放置区赋值
vir_area.sum = Place_Area.sum
for j in Place_Area.card:
vir_area.card.append(j)
gamer = [] # 给两个虚拟玩家赋值
gamer.append(Player("xxx"))
gamer.append(Player("hhh"))
gamer[0].sum = P[0].sum
for j in P[0].card:
gamer[0].card.append(j)
gamer[1].sum = P[1].sum
for j in P[1].card:
gamer[1].card.append(j)
# gamer = copy.deepcopy(_gamer)
Max = -1e9
op = 5
_ucb = {}
for j in choice:
if UCB[j][1] == 0:
_ucb[j] = 1e8
else:
_ucb[j] = UCB[j][0] * 1.0 / UCB[j][1] + math.sqrt(5.0 / UCB[j][1])
if (Max < _ucb[j]):
Max = _ucb[j]
op = j
operation = op
if op == 5: # 如果是5,则直接摸牌
v_card = gamer[1].Touch_Card(vir_card)
Put_vir_area(vir_area, Game, v_card, 1, gamer)
else: # op为其他情况需要出牌
every_card = ['A', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K']
for j in every_card:
t = str(op) + j
if gamer[1].card.count(t) != 0: # 出牌
index = gamer[1].card.index(t)
gamer[1].card.pop(index)
gamer[1].sum -= 1
Put_vir_area(vir_area, Game, t, 1, gamer)
break
# 接下来进行双方对战模拟:
turn = 0
while vir_card.sum != 0:
_result = random.uniform(0, 1)
if _result >= 0.5: # 需要摸牌
v_card = gamer[turn].Touch_Card(vir_card) # 摸牌
Put_vir_area(vir_area, Game, v_card, turn, gamer)
else: # 需要打牌
Choice = ['C', 'D', 'H', 'S'] # 两个玩家的choice
Choice = judge(gamer[turn], Choice) # 筛选可以进行的choice
_result = random.uniform(0, gamer[turn].sum) # 随机决策一个choice
_sum = 0
op = 0
every_card = ['A', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K']
for _op in Choice:
for j in every_card:
t = str(_op) + j
if gamer[turn].card.count(t) != 0:
_sum = _sum + 1
if(_sum >= _result):
op = _op
if op != 0:
break
for j in every_card:
t = str(op) + j
if gamer[turn].card.count(t) != 0: # 出牌
index = gamer[turn].card.index(t)
gamer[turn].card.pop(index)
gamer[turn].sum -= 1
Put_vir_area(vir_area, Game, t, turn, gamer)
break
turn = (turn + 1) % 2
UCB[operation][0] = gamer[0].sum - gamer[1].sum # Q值
UCB[operation][1] += 1 # n值
# 100次模拟已经结束
for i in choice:
if UCB[i][1] != 0:
ans[i] = ans[i] + UCB[i][0] * 1.0 / UCB[i][1] + 2.0 * math.sqrt(math.log(ai_times) / UCB[i][1])
ans_tot[i] = ans_tot[i] + 1
ti = float(format(time.process_time()))
ans_max = -1e9
op = 5
for i in ans_choice:
if ans_tot[i] != 0:
# print("i=", i)
# print("ave=", ans[i] * 1.0 / ans_tot[i])
if ans[i] * 1.0 / ans_tot[i] > ans_max:
ans_max = ans[i] * 1.0 / ans_tot[i]
op = i
maxx = -1e9 # 如果ai的牌堆有超过20张牌,则强制出牌
if op == 5 and P[1].sum >= 20:
for i in ans_choice:
if ans_tot[i] != 0:
if ans[i] * 1.0 / ans_tot[i] == ans_max:
continue
if ans[i] * 1.0 / ans_tot[i] > maxx:
maxx = ans[i] * 1.0 / ans_tot[i]
op = i
if op == 5: # 操作类型:0:摸牌, 1:打牌,打出什么牌,
return 0
else:
return op
-
性能分析与改进

可以看出pygame板块的函数调用耗时较大,但这也是没有办法的事情, -
展示性能分析图和程序中消耗最大的函数

由上图可以看出creat_page函数,__init__函数在程序中消耗最大,这是因为每隔一段时间pygame就要画一次页面,因此在所有的函数中,creat_page函数是消耗最大的。 -
展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路
2.贴出Github的代码签入记录,合理记录commit信息
3.遇到的代码模块异常或结对困难及解决方法
陈志良:
-
困难描述
接口方面,第一次接触接口这东西,毫无思路?
登录界面的实现,如何做一个窗口,让用户在指定的位置输入数据,并且获取,并且密码显示为*?
联机功能实现,如何过滤重复的信息?
对于联机对战,对于收到的数据,如何及时更新本地页面? -
解决过程
刚刚开始,毫无头绪,我就去问了同学,知道了python有专门做接口的函数库:requests,但是,虽然知道了,却无从下手,百度了一早上,无丝毫进展,后来在B站搜,给我找到了教程,所以总共花费了半天的时间解决了接口方面的问题。
我百度搜索python登录界面设计,找到了python的一个函数库:eastGUi,但是,功能受限,我就转战另外一个tkinter,正好又找了一个做好的登陆界面,直接白嫖,改一改就完成了。
我通过设置一个转换状态变量,游戏开始,赋予返回的状态,若接下来返回的数据中,your turn != 该变量,获取该数据,且把your turn 赋值于该变量,然后对于该数据更新本地游戏信息,并更新页面,若your turn = 该变量,说明我们已处理过该数据,pass掉。
返回一条非重复数据,对于该数据更新本地游戏信息,然后更新本地界面,然后绘画;每次打牌或摸牌或吃牌,后面都跟上一个更新函数以及绘画函数,以达到及时更新界面的目的 -
有何收获
敲代码能力是肯定提高了,我都感觉这一个月时间,我敲的代码量快1w行,因为不仅这个游戏要敲,你还要学习新知识,也要敲代码练习,所以我的码力感觉又上了一层楼。
再次让我感受到我对于学习的热情,就是这个游戏越做越上头,越做越想把它做好,所以以至于我甚至为了它敲到三个更半夜,为了它学习新知识到三更半夜,让我重新拾起高三那股学习热情,或许后续我会再改进它。
学习到了很多知识,接口知识、小程序知识(因为中间想把它做成小程序,学了小程序),pygame、tkinter、Gui、原型工具、以及学习了一点AI知识等等。
赵威威:
- 困难描述
实现完AI算法之后,点击运行,发现真的很多bug,而且很多bug是因为自己对python语言并不了解,导致AI一下子吃掉700多张牌,包括python的一些函数的用法并不是很清楚,导致程序一直报错,以及算法的代码实现写的很傻,很不美观。以及在学习PS的过程中,有很多零碎的东西需要记住,以及在PS背景图的时候对于调色也是头大,因为想做出好看的渐变效果的纯色图片,但是自己上手的时候还是觉得挺难的,不管颜色怎么调就是觉得不满意,怎么看都很怪。之前自己作为游戏用户,对UI设计的界面也不会很在意,基本上常常忽视,经过这次游戏开发,以后会对其他软件的UI界面会更加留意。 - 解决过程
从零开始捡起python,每次遇到自己不确定的点都查清楚,复习了很多python知识。从零开始学习PS和原型设计。 - 有何收获
对python语法有了更深的掌握,以及debug的能力有所上升,学习了一些小程序开发的知识,最后没有用到也是比较遗憾,PS技术的到提高,自己的审美水平也有一定提升,但是感觉上述的收获还是有进步空间。同时也感觉自己的专业知识是不足的,日后还要多多学习。
4.评价你的队友
赵威威:
队友的执行力特别强,一开始完全就是队友拖着走的。在敲代码的过程中,感觉他的思维逻辑比较强,思考的很深,并且还是个debug小能手。以及做事有条不紊,给人一种很安心的感觉。在ddl很极限的时时候,我发现AI算法有bug,很大可能要推翻重来,当时还有许多收尾工作要做,队友还是鼓励我有想法就去做,很感激他。是个很棒很棒的队友!
陈志良:
强啊!威威姐!这次的作业页面素材都是她PS搞得,牛的。而且AI是她一个人完成的,确实腻害,而且不愧是搞ACM的,debug能力确实腻害,线下代码测试的时候,亲眼目睹,而且沟通交流很不错。
队友需要改进的地方:
因为要打训练赛和比赛啥的,所以时间管理上存在一点不足,其他都完美。
5.提供此次结对作业的PSP和学习进度条(每周追加)
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 200 | 200 | 13 | 13 | 梳理逻辑思路,完成低保真原型设计,以及本地pvp |
| 2 | 500 | 700 | 25 | 38 | 完成联机pvp,弄好接口,学习微信小程序开发 |
| 3 | 5000 | 5700 | 30 | 68 | PS完成界面设计,学习AI算法,代码实现部分前端设计 |
| 4 | 1000 | 6700 | 30 | 98 | 实现AI算法,代码完成前端设计,debug |
三、心得
陈志良:
人生苦短,我用python。Python是真的好用,个人感觉,不喜勿喷,人家内心很脆弱。但是还是又很痛苦的地方,那就是bug,为什么这个世界上会存在bug这种东西呢???为什么?!!因为这次编程作业,我负责coding,界面实现、游戏功能实现。所以大大小小的bug碰到不少,估计这段时间碰到的bug快赶上我大一俩学期碰到的bug总和还多。每次写完,在运行前,我都会双手合十,心里默念:不要出错!不要出错!但大多数情况,都会出现bug,而且不是单独一个bug,而是连续的bug,就是你改完一个,运行一次,出现另外一个bug,及其折磨,我直接戴上痛苦面具。
这次的作业,有一点我个人认为我做的比较好的一点是:我有进行分类,一个界面一个类,一个功能一个函数,所以改bug的时候也会比较快,如果我是那种一个main函数写完一个东西的话,估计出现一个bug我都得改一整天(是真的一整天)。
经过这次作业,真的收获良多,而且又更加深一步的体会到柯神的神力。这次的成果并没有达到我预期的目标,没有实现动画出牌打牌吃牌的实现,以及部分特效没搞好,而且联机功能的实现,没有使用多线程,唉。这都是遗憾,时间不够。所以,这都要我以后去完善它,我是不会放弃它的,把它做成一个真的游戏。只有一有空我就会实现它。
最后,感谢队友的帮忙。
赵威威:
最大的收获就是前置准备一定要准备好,我们这次的项目也因为前置知识没有准备好走了一些弯路。比如我们最开始并不知道小程序,Web端,app开发的过程。最初的目标是做小程序,但开发过程中发现我们的开发和小程序的设计过程,特点是完全不同的。导致学了小程序开发的教程但没有用上,也是一种遗憾,不过结果还算是好的。以及不要赶ddl,会变得不幸,AI方面是从最后一周开始写的,这也导致了我们AI算法完成的比较仓促,算法也有很多的优化空间。最后感谢这一个月来给我提供帮助的朋友们和队友。
祝大家1024程序员节快乐!