1-3,分布式缓存
在高并发的分布式的系统中,缓存是必不可少的一部分。没有缓存对系统的加速和阻挡大量的请求直接落到系统的底层,系统是很难撑住高并发的冲击,所以分布式系统中缓存的设计是很重要的一环。
分布式缓存特性
高性能:当传统数据库面临大规模数据访问时,磁盘I/O往往成为性能瓶颈,从而导致过高的响应延迟,能够将高速内存作为数据对象的存储介质,数据以key/value形式存储,理想情况下可以获得DRAM(动态随机存取存储器(Dynamic Random Access Memory))级的读写性能;
动态扩展性:支持弹性扩展,通过动态增加或减少节点应对变化的数据访问负载,提供可预测的性能与扩展性;同时最大限度地提高资源利用率;
高可用性:可用性包含数据可用性与服务可用性两方面.基于冗余机制实现高可用性,无单点失效,支持故障的自动发现,透明地实施故障切换,不会因服务器故障而导致缓存服务中断或数据丢失.动态扩展时自动均衡数据分区,同时保障缓存服务持续可用;
易用性:提供单一的数据与管理视图,API接口简单,,且与拓扑结构无关,动态扩展或失效恢复时无需人工配置,自动选取备份节点,多数缓存系统提供了图形化的管理控制台,便于统一维护。
分布式缓存优点
1,提升数据读取速度
2,提升系统扩展能力
3,降低存储成本
分布式缓存应用场景
1,用来缓存Web页面的内容片段,包括HTML、CSS和图片等,多应用于社交网站等;
2,缓存系统作为ORM框架的二级缓存对外提供服务,减轻数据库的负载压力,加速应用访问;
3,缓存包括Session会话状态及应用横向扩展时的状态数据等;,
4,并行处理,涉及大量中间计算结果需要共享;
5,分布式缓存提供了针对事件流的连续查询(continuousquery)处理技术,满足实时性需
6,分布式缓存为事务型应用提供高吞吐率、低延时的解决方案,支持高并发事务请求处理,多应用于铁路、金融服务和电信等领域。
4,redis 简介
nosql框架 , 持久化(数据库) 缓存(基于内存,速度快), 消息队列(list)
Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的 API的非关系型数据库。
5,Redis 有什么数据类型?分别用于什么场景?
字符串(strings):微博数,粉丝数,验证码,分布式锁(setnx expire)等
散列(hashes):可以Hash数据结构来存储用户信息,商品信息等等。
列表(lists)有序,值不可重复:关注列表,粉丝列表,消息队列等功能都可以用Redis的 list 结构来实现
集合(sets)无序,值不可重复:共同关注、共同粉丝、共同喜好等功能
有序集合 有序,值不可重复(sorted sets):地理位置功能(geo),各种排行榜,如在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息
6,Redis有哪些适合的场景?
1)Session共享(单点登录)
2)页面缓存
3)队列(消息队列)
4)排行榜/计数器
5)发布/订阅(注册中心)
redis bgsave和save的区别
SAVE 和 BGSAVE 两个命令都会调用 rdbSave 函数
但它们调用的方式各有不同:
SAVE 直接调用 rdbSave ,阻塞 Redis 主进程,直到保存完成为止。在主进程阻塞期间,服务器不能处理客户端的任何请求。
BGSAVE 则 fork 出一个子进程,子进程负责调用 rdbSave ,并在保存完成之后向主进程发送信号,通知保存已完成。因为 rdbSave 在子进程被调用,所以 Redis 服务器在BGSAVE 执行期间仍然可以继续处理客户端的请求。
7,Redis 的持久化方式?有什么优缺点?持久化实现原理?
redis提供两种方式进行持久化,一种是RDB持久化(原理是将Reids在内存中的数据库记录定时dump到磁盘上的RDB持久化),另外一种是AOF持久化(原理是将Reids的操作日志以追加的方式写入文件)。
区别:
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
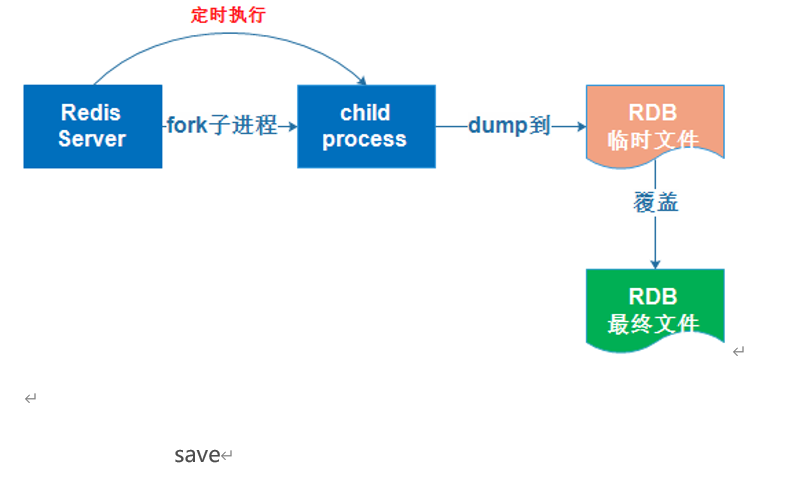
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。

rdb优缺点:
优:
1)适合备份(它保存了 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份: 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。 这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。)
2)适合容灾(它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心 )
3)性能最大化(父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。)
4 ) 恢复数据快(与aop相比)
缺:
1) 容易丢失数据
2) 数据庞大时,影响主进程( 在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 )
aop优缺点:
优:
1)更高数据安全性(默认配置,最多只丢失一秒数据)
2)便于恢复(写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。)
3) 通过重写(rewrite)功能,不让文件体积大(即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性)
4) aof内容更容易读懂(AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析 也很轻松)
缺:
1) 相同数量数据,aof体积大于rdb, rdb恢复数据速度快
2) 根据同步策略的不同,AOF在运行效率上往往会慢于RDB
https://blog.csdn.net/denghonghao/article/details/82108770
8,Redis 的主从复制是如何实现的?
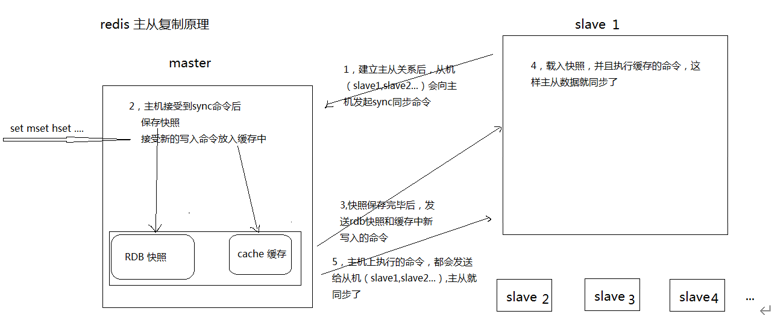
- 从服务器连接主服务器,发送 SYNC(同步) 命令;ASYNC(异步)
- 主服务器接收到 SYNC 命名后,开始执行 BGSAVE 命令生成 RDB 文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器 BGSAVE 执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
9-11 Redis 有哪些架构模式?讲讲各自的特点
单机版
特点:简单
问题:
1、内存容量有限 2、处理能力有限 3、无法高可用
主从复制
特点:
1、master/slave 角色
2、master/slave 数据相同
3、降低 master 读压力在转交从库
问题:
1,无法保证高可用(写)
2,没有解决 master 写的压力
哨兵
特点:
1、保证高可用
2、监控各个节点
3、自动故障迁移
问题:
1、主从模式,切换需要时间丢数据
2、没有解决 master 写的压力
集群
特点:
1、无中心架构(不存在哪个节点影响性能瓶颈),少了 proxy 层。
2、数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
3、可扩展性,可线性扩展到 1000 个节点,节点可动态添加或删除。
4、高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本
5、实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave到 Master 的角色提升。
问题:
1、资源隔离性较差,容易出现相互影响的情况(多个业务使用同一套集群时,无法根据统计区分冷热数据)。
2、数据通过异步复制,不保证数据的强一致性
12,什么是一致性哈希算法?什么是哈希槽?
https://www.cnblogs.com/lpfuture/p/5796398.html
哈希槽
从redis 3.0之后版本支持redis-cluster集群,Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
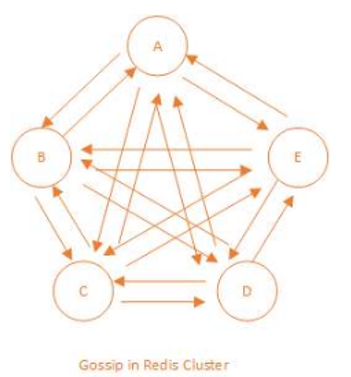
1、所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
2、节点的fail是通过集群中超过半数的节点检测失效时才生效。
3、客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
4、redis-cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster 负责维护node<->slot<->value。
5、Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。CRC16(key) mod 16384=0-16383之间的一个数字
14-16 缓存穿透、缓存击穿、缓存雪崩区别和解决方案
缓存处理流程
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
2:对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中(布隆过滤器),查询时通过该bitmap过滤。
缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
如何避免?
- 设置热点数据永远不过期。
- 加互斥锁,互斥锁参考思路如下
1)缓存中有数据,直接返回结果了
2)缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待100ms,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
如何避免?
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中。
- 设置热点数据永远不过期。
17,使用过Redis分布式锁么,它是怎么实现的?
如何使用redis完成分布式锁
1,使用setnx mylock "AAA" 等同于 set mylock "AAA" NX 设置一把锁,如果不存在可以设置,已经存在不可以设置
set lock "111" EX 5 NX 当lock不存在时,设置lock为111 失效时间为5秒
2,设置成功的线程执行业务,一般都是正常,如果执行业务过程中出现异常
3,执行任务完成,使用 del mylock删除这把锁
4,如果第2步出现异常,第3步没有执行,就会出现死锁等情况,造成大量请求等待,使用exprie把第1步锁设置上失效时间,当
第2步出现异常,第3步不执行时,锁也会自动释放 expire mylock 30 设置失效时间,不固定,根据第2步大于执行业务的时间
Redis为单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系Redis中可以使用SETNX命令实现分布式锁。
将 key 的值设为 value ,当且仅当 key 不存在。 若给定的 key 已经存在,则 SETNX 不做任何动作
解锁:使用 del key 命令就能释放锁
解决死锁:
1)通过Redis中expire()给锁设定最大持有时间,如果超过,则Redis来帮我们释放锁。
2) 使用 setnx key “当前系统时间+锁持有的时间”和getset key “当前系统时间+锁持有的时间”组合的命令就可以实现。
18, 使用过Redis做异步队列(mq)么,你是怎么用的?有什么缺点?
一般使用list结构作为队列,rpush生产消息,lpop消费消息。当lpop没有消息的时候,要适当sleep一会再重试。
缺点:
在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如rabbitmq,kafka等。
19,Redis的单线程为什么这么快
1.redis是基于内存的,内存的读写速度非常快;
2.redis是单线程的,省去了很多上下文切换线程的时间(上下文切换就是cpu在多线程之间进行轮流执行(抢占cpu资源),而redis单线程的,因此避免了繁琐的多线程上下文切换。);
3.redis使用多路复用技术,可以处理并发的连接;
多路复用技术:
多路-指的是多个socket连接,复用-指的是复用一个线程。
目前,多路复用主要有三种技术:select,poll,epoll。它们出现的顺序是按时间先后的,越排后的技术改正了之前技术的缺点。epoll是最新的也是目前最好的多路复用技术。
举个例子:一个酒吧服务员,前面有很多醉汉,epoll这种方式相当于一个醉汉吼了一声要酒,服务员听见之后就去给他倒酒,而在这些醉汉没有要求的时候服务员可以玩玩手机干点别的。但是select和poll技术是这样的场景:服务员轮流着问各个醉汉要不要倒酒,没有空闲的时间。io多路复用的意思就是多个醉汉共用一个服务员。