MySQL的事务
实际上,会将许多SQL查询到一个组中,将执行所有的人都一起作为事务的一部分。比如你在银行给别人卡里转账就是一个事务,首先前需要从你的卡里扣掉,然后在对方的卡里增加,不可能 你的钱扣了,对方没有增加,又或者对方的卡里增加了,而你的卡没有扣钱。
事务的特性
事务有以下四个标准属性的缩写ACID,通常被称为:Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)、Durability(持久性)
- 原子性: 确保工作单元内的所有操作都成功完成,否则事务将被中止在故障点,和以前的操作将回滚到以前的状态。
- 一致性: 确保数据库正确地改变状态后,成功提交的事务。
- 隔离性: 使事务操作彼此独立的和透明的。
- 持久性: 确保提交的事务的结果或效果的系统出现故障的情况下仍然存在。
在MySQL中,事务开始使用COMMIT或ROLLBACK语句开始工作和结束。开始和结束语句的SQL命令之间形成了大量的事务。
COMMIT & ROLLBACK
这两个关键字提交和回滚主要用于MySQL的事务。
当一个成功的事务完成后,发出COMMIT命令应使所有参与表的更改才会生效。
如果发生故障时,应发出一个ROLLBACK命令返回的事务中引用的每一个表到以前的状态。
而我们使用终端连接mysql的时候,输入命令后直接会提交,这是因为MySQL的自动提交参数:
mysql> show variables like 'auto%'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_generate_certs | ON | | auto_increment_increment | 1 | | auto_increment_offset | 1 | | autocommit | ON | | automatic_sp_privileges | ON | +--------------------------+-------+ 5 rows in set (0.01 sec) mysql> # 注意到 autocommit ,自定提交是打开的。
PS:代码里不能自动提交,所以每次操作完毕后,需要手动的执行commit进行提交。
Python操作数据库
Python 提供了程序的DB-API,支持众多数据库的操作。由于目前使用最多的数据库为MySQL,所以我们这里以Python操作MySQL为例子,同时也因为有成熟的API,所以我们不必去关注使用什么数据,因为操作逻辑和方法是相同的。
安装模块
Python 程序想要操作数据库,首先需要安装 模块 来进行操作,Python 2 中流行的模块为 MySQLdb,而该模块在Python 3 中将被废弃,而使用PyMySQL,这里以PyMySQL模块为例。
使用pip命令安装PyMSQL模块
pip3 install pymysql
如果没有pip3命令那么需要确认环境变量是否有添加,安装完毕后测试是否安装完毕。
lidaxindeMacBook-Pro:~ DahlHin$ python3 Python 3.6.1 (v3.6.1:69c0db5050, Mar 21 2017, 01:21:04) [GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import pymysql >>> # 如果没有报错,则表示安装成功
创建一个连接
首先我们需要手动安装一个MySQL数据库,这里不再赘述,参考博文:http://www.cnblogs.com/dachenzi/articles/7159510.html
使用pymysql.connect方法来连接数据库
import pymysql
conn = pymysql.connect(host=None, user=None, password="",
database=None, port=0, unix_socket=None,
charset=''......)
-
- host:表示连接的数据库的地址
- user:表示连接使用的用户
- password:表示用户对应的密码
- database:表示连接哪个库
- port:表示数据库的端口
- unix_socket:表示使用socket连接时,socket文件的路径
- charset:表示连接使用的字符集
- read_default_file:读取mysql的配置文件中的配置进行连接
上面仅仅列举了几个常用的参数,其他还有很对连接的选项,可以通过pymysql.connect函数来查看源码。
程序的健壮性
现在的程序基本是都是要连接数据库的,那么在一个程序里面可能会有很多功能都会去连接数据库,那么如果每次都去创建连接指定数据库的地址,端口等信息,先不说麻烦,如果我的数据库端口改了,我们岂不是要在所有调用数据库的地方进行修改? 所以这就引出了一个概念:模块化。
前面我们已经学过包和模块了,我们把连接数据库的操作写成一个函数做成一个包,那么什么地方使用,只需要调用即可,并且修改的时候只需要修改模块的代码即可,这样大大的方便了我们日后可能的操作。
import pymysql
def connect_mysql():
db_config = {
'host':'127.0.0.1',
'port':3306,
'user':'root',
'password':'abc.123',
'charset':'utf8'
}
conn = pymysql.connect(**db_config)
return conn
# 注意:端口不能加引号,因为port接受的数据类型为整型
# 注意:charset的字符集不是utf-8,是utf8
PS:当然对于这种可能频繁修改的当作配置写到文件中去也是可以的。
连接
调用connect函数,将创建一个数据库连接并得到一个Connection对象,Connection对象定义了很多的方法和异常。
- begin:开始事务
- commit:提交事务
- rollback:回滚事务
- cursor:返回一个Cursor对象
- autocommit:设置事务是否自动提交
- set_character_set:设置字符集编码
- get_server_info:获取数据库版本信息
在实际的编程过程中,一般不会直接调用begin、commit和rollback函数,而是通过上下文管理器实现事务的提交与回滚操作。
游标
游标是系统为用户开设的一个数据缓存区,存放SQL语句执行的结果,用户可以用SQL语句逐一从游标中获取记录,并赋值给变量,交由Python进一步处理。
在数据库中,游标是一个十分重要的概念。游标提供了一种对从表中检索出的数据进行操作的灵活手段,就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标总是与一条SQL 选择语句相关联因为游标由结果集(可以是零条、一条或由相关的选择语句检索出的多条记录)和结果集中指向特定记录的游标位置组成。当决定对结果集进行处理时,必须声明一个指向该结果集的游标。
正如前面我们使用Python对文件进行处理,那么游标就像我们打开文件所得到的文件句柄一样,只要文件打开成功,该文件句柄就可代表该文件。对于游标而言,其道理是相同的。
利用游标操作数据库
在进行数据库的操作之前需要创建一个游标对象,来执行sql语句。
import pymysql
def connect_mysql():
db_config = {
'host':'127.0.0.1',
'port':3306,
'user':'root',
'password':'abc.123',
'charset':'utf8'
}
conn = pymysql.connect(**db_config)
return conn
if __name__ == '__main__':
conn = connect_mysql()
cursor = conn.cursor() # 创建游标
sql = r" select user,host from mysql.user " # 要执行的sql语句
cursor.execute(sql) # 交给 游标执行
result = cursor.fetchall() # 获取游标执行结果
print(result)
游标的方法
游标内置了很多方法常用的有: cursor.fetchall(),cursor.fetchone(),cursor.fetchmany()
cursor.execute(sql),executemany(sql,parser)
用于执行sql语句,execut执行一条sql语句,executemany执行多条语句
# execute 执行单条sql语句
conn = connect_mysql()
cursor = conn.cursor() # 创建游标
sql = r" select user,host from mysql.user " # 要执行的sql语句
cursor.execute(sql) # 交给 游标执行
# executemany 执行多条SQL语句
conn = connect_mysql()
cursor = conn.cursor()
sql = 'insert into tmp(id) VALUES(%s)' # %s 表示占位符
parser = [1,2,3,4,5,6]
cursor.execute('use test')
cursor.executemany(sql,parser) # 把参数进行填充,parset是参数的列表
conn.commit()
conn.close()
cursor.fetchone(),fetchmany(),fetchall()
用户获取数据,fetchone获取一行,fetchmany获取多行,fetchall获取所有
conn = connect_mysql() cursor = conn.cursor() # 创建游标 sql = r" select user,host from mysql.user " cursor.execute(sql) # 交给 游标执行 result1 = cursor.fetchone() result2 = cursor.fetchmany(2) # 获取2行 result3 = cursor.fetchall() print(result1) print(result2) print(result3)
注意:cursor的数据只能取一次,比如上面的示例,一共有三行数据,fetchone取了一行,fetchmany(2)取了两行,那么fetchall()将会得到空数据。
corsor.rowncount 常量,表示sql语句的结果集中,返回了多少条记录
cursor.arraysize 常量,保存了当前获取记录的下标
corsor.close() 关闭游标
小结
- 导入相应的Python模块
- 使用connect函数连接数据库,并返回一个Connection对象
- 通过Connection对象的cursor方法,返回一个Cursor对象
- 通过Cursor对象的execute方法执行SQL语句
- 如果执行的是查询语句,通过Cursor对象的fetchall语句获取返回结果
- 调用Cursor对象的close关闭Cursor
- 调用Connection对象的close方法关闭数据库连接
利用数据库链接池操作数据库
在python编程中可以使用MySQLdb/pymysql等模块对数据库的连接及诸如查询/插入/更新等操作,但是每次连接mysql数据库请求时,都是独立的去请求访问,相当浪费资源,而且访问数量达到一定数量时,对mysql的性能会产生较大的影响。因此,实际使用中,通常会使用数据库的连接池技术,来访问数据库达到资源复用的目的。
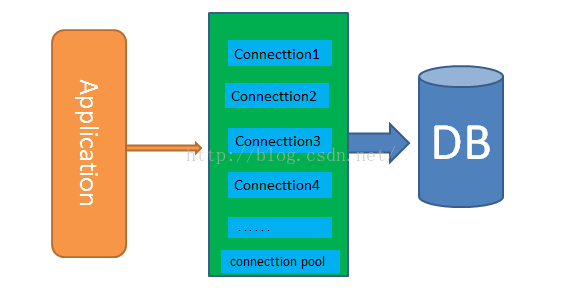
数据库连接池包 DBUtils
DBUtils是一套Python数据库连接池包,并允许对非线程安全的数据库接口进行线程安全包装。DBUtils来自Webware for Python。
DBUtils提供两种外部接口:
- * PersistentDB :提供线程专用的数据库连接,并自动管理连接。
- * PooledDB :提供线程间可共享的数据库连接,并自动管理连接。
import pymysql
from DBUtils.PooledDB import PooledDB # 导入线程池对象
pool = PooledDB(pymysql,host='127.0.0.1',port=3306,user='root',password='abc.123',mincached=20) # 利用线程池对象,实例化mysql连接对象,这里最少空闲20个链接,即实例化后会立即创建20个MySQL链接,并且空闲数少于20,会自动创建
# 第一个参数表示链接数据库使用的API,这里我使用pymysql,也可以使用MySQLdb。
conn = pool.connection() # 获取链接池中的mysql链接
cursor = conn.cursor()
cursor.execute('select user,host from mysql.user;')
data = cursor.fetchall()
cursor.close()
conn.close()
print(data)
PooledDB对象提供的参数还有:
1. mincached,最少的空闲连接数,如果空闲连接数小于这个数,pool会创建一个新的连接
2. maxcached,最大的空闲连接数,如果空闲连接数大于这个数,pool会关闭空闲连接
3. maxconnections,最大的连接数,
4. blocking,当连接数达到最大的连接数时,在请求连接的时候,如果这个值是True,请求连接的程序会一直等待,直到当前连接数小于最大连接数,如果这个值是False,会报错,
5. maxshared 当连接数达到这个数,新请求的连接会分享已经分配出去的连接
连接池对性能的提升表现在:
1.在程序创建连接的时候,可以从一个空闲的连接中获取,不需要重新初始化连接,提升获取连接的速度
2.关闭连接的时候,把连接放回连接池,而不是真正的关闭,所以可以减少频繁地打开和关闭连接
数据库相关操作
数据库主要有库和表来组成,库是表的集合,针对库和表有如下基本操作。
库相关操作
数据库在文件系统上就是用目录体现的,所以对库的操作,可以理解为对目录的操作。
- 创建数据库,会在MySQL的data目录下创建同名文件夹
创建数据库
|
1
2
3
4
|
create database db_name;create database db_name default charset utf8;--> 语法格式:create database 数据库名称--> 建议同时指定数据库的字符集 |
删除数据库
|
1
2
3
|
drop database db_name;--> 语法格式:drop database 数据库名称--> 删除数据库目录,注意会删除库下的所有表文件 |
查看及进入数据库
|
1
2
3
|
show databases;use db_name;--> 查看库的信息:show create database db_name; |
表相关操作
表在文件系统上是用文件体现的,所以对表的操作,可以理解为对文件的操作。
- 创建表,会在对应的库目录下创建表空间文件
创建表
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
create table user_info( id int not null auto_increment primary key, name char(20), age int, gender char(1), deparment_id int, constraint 约束名称 foreign key(deparment_id) references dep_info(id))engine = innodb default charset=utf8;--> 语法格式:--> create table 表名(--> 列名 类型 [是否为空] [是否默认值] [自增] [主键] ,--> 列名2 类型--> .... ....--> [ constraint 外键名称 foreign key(本表的被约束字段) reference 目标表名(字段) ] --> ) engine = 存储引擎名称 default charset = utf8; |
各字段含义:
- 列名
- 数据类型
- 是否可以为空(null/not null)
- 是否默认值(default value)
- 是否自增(auto_icrement):一个表只能存在一个自增列并且必须有索引(普通索引或主键索引),类型必须是数值型。
- 主键(primarr key):数据不能为空、不能重复,可以加速查找(数据库的B树结构)
- 外键(constraint) :对表内某字段的内容进行约束,必须是某个表的某个字段已有的值,含外键的表可以理解为1对多,注意外键关联的两个字段数据类型要一致
基本数据类型
MySQL的数据类型大致分为:数值、时间 和 字符串。


1 数字: 2 整数 3 tinyint 小整数,数据类型用于保存一些范围的整数数值范围。 4 smallint 5 int 6 bigint 7 小数 8 float 浮点型(长度越长越不精准) 9 double 浮点型(双精度,精度比float稍高) 范围比float更大 10 decimal 精准(内部使用字符串进行存储的) -> 适合对精度有要求的 11 字符串 12 char(19)[字符长度] 定长字符串 --> 占用空间大,但是效率高 13 varchar(19)[字符长度] 不定长字符串 --> 占用空间是可变的,但是效率低 14 注意:最大可以存放255个字符 15 text() 65535个字符 16 mediumtext() 16777215个字符 17 longtext() 4294967254个字符 18 二进制: 19 TinyBlob 20 Blob 21 MediumBlob 22 LongBlob 23 存文件:虽然可以用二进制进行存储,但是一般是存储文件在服务器上的路径(URL) 24 时间: 25 date YYYY-MM-DD 26 time HH:MM:SS 27 year YYYY 28 DATETIME YYYY-MM-DD HH:MM:SS -->常用 29 TIMESTAMP 时间戳格式
创建多表外键关联
- 一对多:一个表的某个字段的数据来自于另一个表已存在的数据。
- 多对多:一个表的某几个字段的数据来自于另一个或几个表已存在的数据。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
一对多: create table user_info( id int not null auto_increment primary key, name char(20), age int, gender char(1), deparment_id int, constraint 约束名称 foreign key(deparment_id) references dep_info(id) )engine = innodb default charset=utf8; create table dep_info( id int not null auto_increment primary key, title char(32), )engine=innode default charset=utf8;多对多:(关系表) create table boy( id int not null auto_increment primary key, name char(32) )engine = innodb default charset=utf8; create table girl( id int not null auto_increment primary key, name char(32) )engine = innodb default charset=utf8; create table b2g( id int not null auto_increment primary key, b_id int, g_id int, constraint 约束名称1 foregin key(b_id) references boy(id), constraint 约束名称2 foregin key(g_id) references girl(id) )engine = innodb default charset = utf8; |
删除表
|
1
|
drop table tb_name; |
查看相关
|
1
2
3
4
5
6
7
8
|
--> 查看创建表的语句show create table table_name;--> 查看表结构desc table_name;--> 查看表show tables; |
操作表数据
针对表的数据进行操作,主要涉及4类:
- 增加 insert
- 删除 delete
- 修改 update
- 查找 select
而插入内容就相当于在表文件中按照MySQL的格式写数据
插入数据
|
1
2
3
4
5
6
7
8
|
insert into table_name(field) values(value),(value2) --> 语法格式: insert into 表名(字段) values(值1),(值2)--> 两个(value)表示插如多行数据--> 当字典省略时,表示插入字段所有数据,values后面的值需要列出所有字段insert into table_name(cname) select field from table_name --> 把select查到的结果,当作数据来赋值给value--> 查询到的数据字段要和插入的字段数量一致 |
删除数据
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
--> 清空表delete from table_name--> 删除之后,插入新数据自增列会继续之前的IDtruncate table table_name --> 物理删除,速度快,重新计算ID--> 删除某一条delete from table_name where filed = values and/or ...--> 只删除符合条件的数据例子:delete from table_name where filed in (1,2,3,4) delete from table_name where id between 5 and 10 |
修改数据
|
1
2
3
4
|
update table_name set field = 'value'--> 更新所有数据的field字段的值,加 where 只修改匹配到的行例子:update table_name set id = 8 , name = 'daxin' where age = 18; |
查询数据
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
--> where条件select * from table_name where id > 2select field as '别名' from table_name --> 加别名select * from table_name where id in (1,2)select * from table_name where cid in (select tid from teacher)--> 排序限制条件select * from table_name order by field asc/desc(正序/倒序)select * from table_name order by field asc limit 1 取第一个值select * from table_name limit 1,2(起始位置,找几个)--> 查找field字段包含key的数据,% 表示任意个任意字符, _表示任意一个字符select * from table_name where field like '%key%'--> 连表查询select student.sid,student.sname,class.caption from student LEFT JOIN class on student.class_id = class.cid ;--> 把class表中的字段放在student表的左边,并且进行 student.class_id = class.cid 匹配后显示,数据量以from指定的表为基准--> left join:以 from 指定的表为基准,对数据进行显示--> right join: 不常用,以 join 后面的表为基准进行显示。--> inner join:(join 使用的就是),只保留连个表中都有数据的条目--分组显示:select * from table_name group by field --> 分组显示,会去重,需要使用聚合函数来统计重复的次数select field,count(id) from table_name group by field--> 对id字段进行聚合(其他的还有min(),max(),sum(),avg()等)例子:1、获取每个班级多少人SELECT class.caption,count(sid) from class LEFT join student on student.class_id = class.cidgroup by class.caption2、获取每个班级有多少人并且选出认识大于2的班级,注意:如果针对 group by 的结果进行筛选,那么需要使用 having 不能在使用 where 了.SELECT class.caption,count(sid) as number from classLEFT join student on student.class_id = class.cidgroup by class.captionHAVING number >= 23、每个课程的不及格的人数。select course.cname,count(sid) from scoreleft join course on score.corse_id = course.cidwhere number < 60group by course.cname--> union:把两个SQL的结果进行组合(上下合并) select * from student union / union all select * from teacher; 注意上下两个表中的列数要统一注意: 1、如果所有数据都一致,那么union会对结果进行去重 2、union all ,会保存所有的 |
PS:这里仅列举了SQL的写法,如果利用python完成,只需要把上面语句交给cursor.execute去执行即可,别忘了,增删改需要commit哦!