Generally, we create multitiered applications using Remoting and remote objects. Applications that contain multiple tiers separate the functions they perform into components that can be distributed across a network. .Net Remoting is powerful, but it is not without challenges.
There are two main typical multitiered applications based on .Net Remoting. Let’s illustrate them in detail and analyze their strongpoints and drawbacks respectively. It’s important and necessary to have a good command of application architecture to design an actual complicated system with high scalability, extensibility and maintainability.
Each tier in applications performs a specific function. The interfaces between the tiers are well defined. The programs in any tiers do not have to know anything about the internal operation of the programs in other tiers. As long as the interface between the tiers stays the same, a company can completely change the implementation of any one layer without impact on other tiers.
These two distinct architectural styles are as follows.
The top tier in the architecture, which is often called presentation tier, provides the user’s view of the application system. The end users will operate this tier directly. The second tier named business logic tier implements the application business rules and policies. The third tier is data access tier, which is responsible to access and update database. The lowest tier is actual database server, such as SQL Server, etc.
In addition, in most cases, there are other sub systems in actual systems taking care of common tasks, such as exception management, common class libraries, etc.
1, Deploy business objects on remote server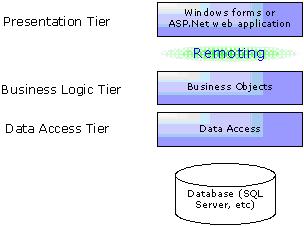
We know objects with fine-grained interface usually contain data members (fields) and methods together. It’s a basic rule of object-oriented technology. These objects may have many fields with associated getters and setters and many methods, each of which encapsulates a small and cohesive piece of functionality. Because of this fine-grained nature, many methods must be called to achieve a desired result. This fine-grained interface approach is ideal for stand-alone applications because it supports many desirable application characteristics such as maintainability, reusability and testability.
(我们知道面向对象技术的基本定义:将数据和操作行为(方法)包装在一起。这种良好的结构不仅让开发人员容易编写代码,而且提高代码的可维护性,重用性和可测试性。)
However, working with an object that exposes a fine-grained interface can greatly impede application performance, because a fine-grained interface requires many method calls across process and network boundaries. To improve performance, remote objects must expose a more coarse-grained interface. A coarse-grained interface is one that exposes a relatively small set of self-contained methods. Each method typically represents a high-level piece of functionality such as Place Order or Update Customer. These methods are considered self-contained because all the data that a method needs is passed in as a parameter to the method.
(但是,如果将对象部署为Remote Object,对这些public fields的操作,如getter/setter,将会导致大量的跨进程和网络边界的方法调用,显然会降低application的性能。其实,由于一些Remote Object的无状态特性,上述getter/setter方法可能根本就没有任何意义。为了提高性能,Remote Object必须暴露一些coarse-grained方法接口,一般这些方法都完成某一项特定的功能,如下订单或更新客户等等。另外,在调用这些方法时,需要传入方法在执行过程中所有需要的参数。)
I think it’s a big drawback of remote object. You have to pass a lot of parameters to a method when it needs access them. In addition, many methods in a class will need to access the same parameters. Due to remote object without data members, you have to pass these parameters again when calling other methods.
Luckily, Microsoft provides some solutions to the above issue, which is known as Data Transfer Object Pattern.
The Data Transfer Object pattern applies the coarse-grained interface concept to the problem of passing data between components that are separated by process and network boundaries. It suggests replacing many parameters with one object that holds all the data that a remote method requires. The same technique also works quite well for data that the remote method returns.
(引入数据传递对象模式(Data Transfer Object pattern)来解决上述问题,其实也就是引入参数类来代替大量的参数列表,这一思想在《重构(Refactoring)技巧读书笔记 之一》中已经提及。)
There are several options for implementing a data transfer object (DTO). One technique is to define a separate class for each different type of DTO that the solution needs. The classes usually have a strongly typed public field (or property) for each data element they contain. To transfer these objects across networks or process boundaries, these classes are serialized. The serialized object is marshaled across the boundary and then reconstituted on the receiving side. Performance and type safety are the key benefits to this approach. This approach has the least amount of marshaling overhead, and the strongly typed fields of DTO ensure that type errors are caught at compile time rather than at run time. The downside to his approach is that a new class is created for each DTO. If a solution requires a large number of DTOs, the effort associated with writing and maintaining these classes can be significant.
(其实就是引入参数类来代替参数列表,在跨进程或网络边界来传递参数,这些参数类必须可序列化。其优点是性能好(因为序列化时间最少)和类型安全,缺点是如果系统需要大量的DTO时,则需要写大量的参数类并维护。)
A second technique for creating a DTO is to use a generic container class for holding the data. A common implementation of this approach is to use something like the ADO.Net DataSet as the generic container class. This approach requires two extra translations. The first translation on the sending side converts the application data into a form that is suitable for use by the DataSet. The second translation happens on the receiving side when the data is extracted from the DataSet for use in the client application. These extra translations can impede performance in some applications. Lack of type safety is another disadvantage of this approach. If a customer object is put into a DataSet on the sending side, attempting to extract an order object on the receiving side results in a run-time error. The main advantage to his approach is that no extra classes must be written, tested, or maintained.
(第二种技术时使用DataSet作为通用的参数容器类,缺点是在发送端需要将参数转换为DataSet,在接收端需要从DataSet中提取数据参数,影响性能。另外,缺乏类型安全性,因为都为DataSet么。优点是不需要编写、测试和维护额外的参数类。)
ADO.Net offers a third alternative, the typed DataSet. ADO.Net provides a mechanism that automatically generates a type-safe wrapper around a DataSet. This approach has the same potential performance issues as the DataSet approach but allows the application to benefit from the advantages of type safety, without requiring the developer to develop, test, and maintain a separate class for each DTO.
A typed DataSet is a generated subclass of System.Data.DataSet. This means that it can be substituted for a DataSet.
The drawback of using a typed DataSet is that you have to create and maintain an XML schema to describe the strongly-typed interface. Visual Studio.Net provides a number of tools to assist in this process, but nevertheless you still have to maintain an additional file. Additionally, instantiating and filling a DataSet can be an expensive operation. Serializing and deserializing a DataSet can also be very time consuming.
The differences between using a strongly-typed interface and a generic interface is that the strongly-typed interface is easier to use and understand. It also provides the added benefit of compile-time checking on return types.
(ADO.Net提供了另一个选择:typed DataSet(类型化DataSet),typed DataSet是System.Data.DataSet的子类。Typed DataSet需要创建XML schema来描述strongly-typed接口,其优点是易于使用和理解,而且可以在编译时检测返回类型安全,但缺点时需要创建并维护额外的XML schema文件,并且在速度上比untyped DataSet还有稍慢。)
Let’s make a summary to the above solutions:
(1) Use coarse-grained interface to pass/return parameters data. For example,
public bool CheckSoNumberInfo(string soNumber, out string customerNumber, out DateTime dtSoDate)
(2) Replace many parameters with one object that holds all the data that a remote method requires, that is to say, introduce a parameter class or data entity class to pass/return parameters data.
(3) Use ADO.Net DataSet as the generic container class for holding application data.
(4) Use typed DataSet, a generated subclass of System.Data.DataSet, to pass/return parameters data.
2, Deploy data access tier on remote server
Just as the above figure shown, the data access tier has been deployed on remote server. Maybe you have never seen this application architecture because many technique documents don’t mention it.
I’ve got this idea from a practical project, where I need change a normal application into a distributed system using .Net Remoting technology. The business objects located in business logic tier have been designed with fine-grained interfaces, such as public members with getter/setter accessor. In order to change less existing code, I try to deploy data access tier on remote server, instead of business logic tier.
After a few days later, I confirm that it’s a practical solution because I watch some experts recommend this application architecture from a public presentation.
The main benefit is that developers can design business classes with fine-grained interfaces and develop the application based on their original experiences without any changes, just as developing a stand-alone application. In this case, you only need pass a few parameters to remote objects, such as connection string, SQL script, etc. It’s very simple. Therefore, you don’t have to build parameter classes or DataSet like the above solution.
Additionally, due to only a few data access classes have been deployed on remote server, it’s simple to maintain these remote objects.
However, there are some drawbacks with it. First, it’s not a good way to allow SQL script to be sent from a client to application server or remote server. It’s a security problem. Second, other applications can’t access the business objects because business objects exist on client side, instead of remote server.
***
Which one architectural style do you prefer? It depends on your own.
You are welcome to discuss on this topic. Any questions, please comment below. Thanks.
Reference:
1, David Conger, Remoting with C# and .Net
2, Ingo Rammer, Advanced .Net Remoting – C# Edition
3, Enterprise Solution Patterns using Microsoft .Net, Version 2.0