一个只能匹配非常简单的(字母 . + *)共 4 种状态的正则表达式语法的自动机(注意,仅限 DFA,没考虑 NFA):
好久之前写的了,记得有个 bug 一直没解决...
#include <iostream>
//#include <fstream>
#include <vector>
#include <string>
class DFA
{
void construction(std::string regex)
{
std::vector<AM*> worker;
Match = std::make_unique<AM>();
h = std::make_unique<AM>(toRange('H'), nullptr);
AM* h_ptr = h.get();
for (auto iter = regex.begin(); iter != regex.end(); ++iter)
{
AM * temp = new AM(toRange(*iter), h_ptr);
switch (*iter)
{
case '.':
{
h_ptr->next[temp->ch] = temp;
h_ptr = temp;
if (iter + 1 != regex.end() && *(iter + 1) != '*')
{
while (!worker.empty())
{
AM*c_ptr = worker.front();
worker.erase(worker.begin());
c_ptr->next[h_ptr->ch] = h_ptr;
}
}
}
break;
case '*':
{
h_ptr->next[h_ptr->ch] = h_ptr;
for (std::vector<AM*>::iterator i = worker.begin(); i != worker.end(); i++)
(*i)->next[h_ptr->ch] = h_ptr;
if (h_ptr->prev != nullptr)
worker.push_back(h_ptr->prev);
worker.push_back(h_ptr);
delete temp;
temp = nullptr;
}
break;
case '+':
{
h_ptr->next[h_ptr->ch] = h_ptr;
while (!worker.empty())
{
AM*c_ptr = worker.front();
worker.erase(worker.begin());
c_ptr->next[h_ptr->ch] = h_ptr;
}
delete temp;
temp = nullptr;
}
break;
default:
{
h_ptr->next[temp->ch] = temp;
h_ptr = temp;
if (iter + 1 != regex.end() && *(iter + 1) != '*')
{
while (!worker.empty())
{
AM*c_ptr = worker.front();
worker.erase(worker.begin());
c_ptr->next[h_ptr->ch] = h_ptr;
}
}
}
break;
}
}
while (!worker.empty())
{
AM*c_ptr = worker.front();
worker.erase(worker.begin());
if (h_ptr->next[h_ptr->ch] == h_ptr)
c_ptr->next[0] = Match.get();
else
c_ptr->next[h_ptr->ch] = h_ptr;
}
h_ptr->next[0] = Match.get();
}
char toRange(char c) const
{
if (c == '.')
return 27;
return c - 'a' + 1;
}
public:
bool isMatch(std::string s, std::string regex)
{
construction(regex);
AM * am = h.release();
for (auto i:s)
{
char c = toRange(i);
if (am == nullptr)
return false;
if (am->next[c] != nullptr)
am = am->next[c];
else if (am->next[27] != nullptr)
am = am->next[27];
else
am = am->next[c];
}
return am != nullptr && am->next[0] == Match.get();
}
private:
struct AM {
char ch;
AM *prev, *next[28];
AM() : ch(), prev(), next() {}
AM(char v, AM * prev) : ch(v), prev(prev), next() {}
};
std::unique_ptr<AM> Match, h;
};
int main(int argc, char const *argv[])
{
DFA s;
std::cout << (s.isMatch("abc", "aa*b*c+p*") ? "true":"false");
return 0;
}
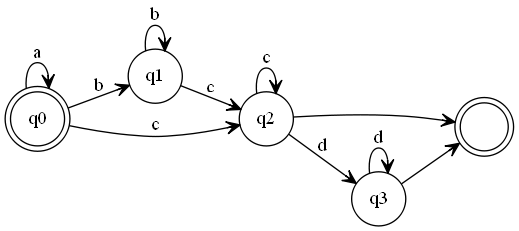
示例1:a*b*c+d*
该正则表达式的DFA如下图
示例2:(a|b)*a
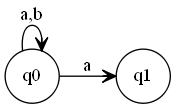
这是一个NFA,我的代码并没有实现NFA转DFA,因而会导致匹配失败。(2020-04-05 21:00:39 补充:所以 leetcode 上 a*a 过不了,因为它也是NFA。虽然可以转换为正则表达式 a+ 来匹配,它的构造图:
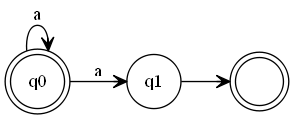
但 a+ 的 DFA 构造图也可以是这样的:
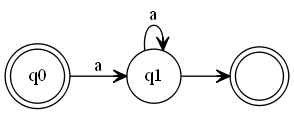
实际上我们写出状态转移表,然后直接查状态表效率会更高,不过我个人觉得模拟匹配的过程更有意思。