一般的,我们想抓取一个网站所有的URL,首先通过起始URL,之后通过网络爬虫提取出该网页中所有的URL链接,之后再对提取出来的每个URL进行爬取,提取出各个网页中的新一轮URL,以此类推。整体的感觉就是自上而下进行抓取网页中的链接,理论上来看,可以抓取整站所有的链接。但是问题来了,一个网站中网页的链接是有环路的。
举个栗子,在网站首页中我们可以看到首页这个链接,之后我们在子网页中也有可能会看到有个链接是指向首页的,可能子子网页还会有对应的链接指向首页。按照我们之前的逻辑,抓取每个网页中的所有链接,之后对所有的链接继续抓取。就拿首页来说,我们首先抓取的就是它,尔后子网页中又有个链接指向首页,子子网页还有链接指向首页,如此进行抓取,岂不是会导致网页重复抓取,其他的网页根本就没有机会去抓取了,简直不敢想象~~要解决这个问题并不难,此时就需要用到网络爬虫中了一个重要的知识点,就是网页去重。

首先介绍一个简单的思路,也是经常用的一个通用思路。我们将已经爬取过的网页放到一个列表中去,以首页为例,当首页被抓取之后,将首页放到列表中,之后我们抓取子网页的时候,如果再次碰到了首页,而首页已经被抓取过了,此时就可以跳过首页,继续往下抓取其他的网页,而避开了将首页重复抓取的情况,这样下来,爬取整站就不会出现一个环路。以这个思路为出发点,将访问过的URL保存到数据库中,当获取下一个URL的时候,就去数据库中去查询这个URL是否已经被访问过了。虽然数据库有缓存,但是当每个URL都去数据库中查询的话,会导致效率下降的很快,所以这种策略用的并不多,但不失为最简单的一种方式。

第二种方式是将访问过的URL保存到set中去,通过这样方式获取URL的速度很快,基本上不用做查询。但是这种方法有一个缺点,将URL保存到set中,实际上是保存到内存中,当URL数据量很大的时候(如1亿条),会导致内存的压力越来越大。对于小型的爬虫来说,这个方法十分可取,但是对于大型的网络爬虫,这种方法就难以企及了。

第三种方式是将字符进行md5编码,md5编码可以将字符缩减到固定的长度。一般来说,md5编码的长度约为128bit,约等于16byte。在未缩减之前,假设一个URL占用的内存大小为50个字节,一个字节等于2byte,相当于100byte。由此可见,进行md5编码之后,节约了大量的内存空间。通过md5的方式可以将任意长度的URL压缩到同样长度的md5字符串,而且不会出现重复的情况,达到去重的效果。通过这种方式很大程度上节约了内存,scrapy框架采取的方式同md5方式有些类似,所以说scrapy在正常情况下,即使URL的数量级达到了上亿级别,其占用的内存比起set方式也要少得多。

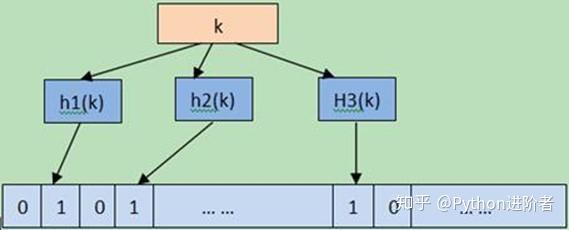
第四种方式是使用bitmap方法将字符进一步压缩。这种方式的意思是在计算机中申请8个bit,即8个位,每个位由0或者1表示,这是计算机中最小的单元。8个位组成1个byte,一个位代表一个URL的话,为什么一个位可以确定一个URL呢?因为我们可以将一个URL进行一个哈希函数,然后将其映射到位上面去。举个栗子,假设我们有8个URL,分别对应8个位,然后通过位上面的0和1的状态,便可以表明这个URL是否存在,通过这种方法便可以进一步的压缩内存。
但是bitmap方法有一个非常大的缺点,就是它的冲突会非常高,因为同用一个哈希函数,极有可能将两个不同的URL或者多个不同的URL映射到一个位置上来。实际上这种哈希的方法,它也是set方式的一种实现原理,它将URL进行一种函数计算,然后映射到bit的位置中去,所以这种方式对内存的压缩是非常大的。简单的来计算一下,还是以一亿条URL来进行计算,相当于一亿个bit,通过计算得到其相当于12500000byte,除以1024之后约为12207KB,大概是12MB的空间。在实际过程中内存的占用可能会比12MB大一些,但是即便是如此,相比于前面三种方法,这种方式以及大大的减少了内存占用的空间了。但是与此同时,该方法产生冲突的可能性是非常大的,所以这种方法也不是太适用的。那么有没有方法将bitmap这种对内存浓重压缩的方法做进一步优化,让冲突的可能性降下来呢?答案是有的,就是第五种方式。

第五种方式是bloomfilter,该方法对bitmap进行改进,它可以通过多个哈希函数减少冲突的可能性。通过这种方式,一方面它既可以达到bitmap方法减少内存的作用,另一方面它又同时起到减少冲突的作用。关于bloomfilter原理及其实现,后期肯定会给大家呈上,今天先让大家有个简单的认识。Bloomfilter适用于大型的网络爬虫,尤其是数量级超级大的时候,采用bloomfilter方法可以起到事半功倍的效果,其也经常和分布式爬虫共同配合,以达到爬取的目的。
关于网络爬虫过程中去重策略的五种方式的介绍就先到这里了,不懂的就当了解一下了,科普一下下,问题不大,希望对小伙伴们的学习有所帮助。