今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门。不过不要慌,小编在网上找到了第三方工具,它可以将朋友圈进行导出,之后便可以像我们正常爬虫网页一样进行抓取信息了。
【出书啦】就提供了这样一种服务,支持朋友圈导出,并排版生成微信书。本文的主要参考资料来源于这篇博文:https://www.cnblogs.com/sheng-jie/p/7776495.html ,感谢大佬提供的接口和思路。具体的教程如下。
一、获取朋友圈数据入口
1、关注公众号【出书啦】

2、之后在主页中点击【创作书籍】-->【微信书】。
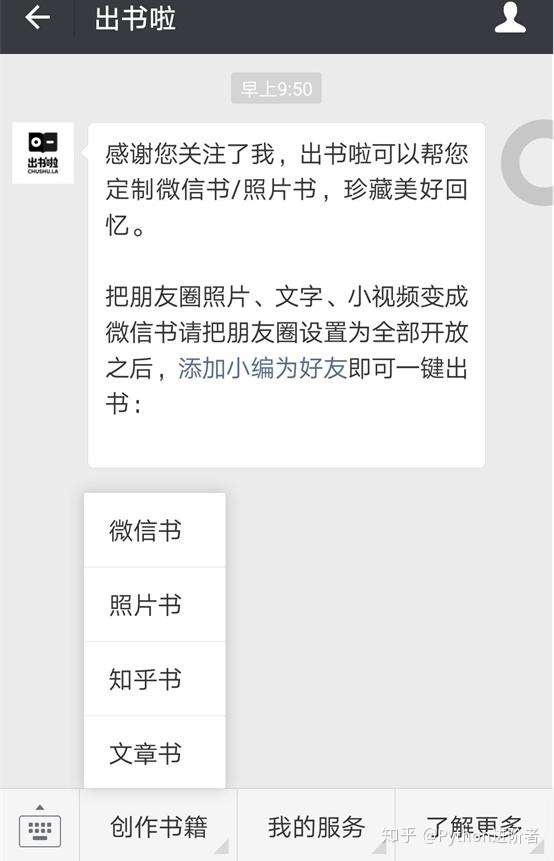
3、点击【开始制作】-->【添加随机分配的出书啦小编为好友即可】,长按二维码之后便可以进行添加好友了。
4、之后耐心等待微信书制作,待完成之后,会收到小编发送的消息提醒,如下图所示。
至此,我们已经将微信朋友圈的数据入口搞定了,并且获取了外链。
确保朋友圈设置为【全部开放】,默认就是全部开放,如果不知道怎么设置的话,请自行百度吧。
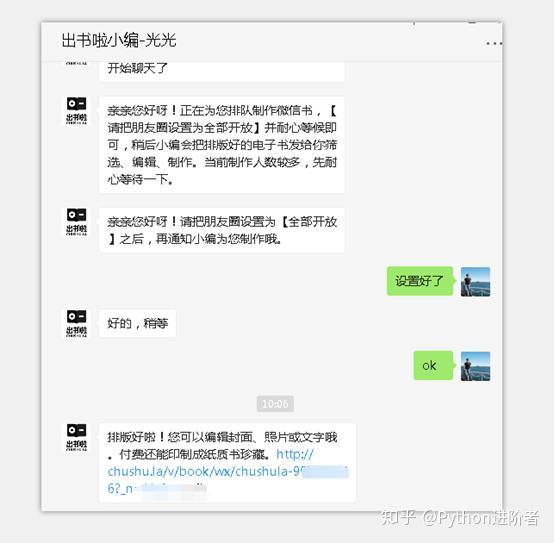
5、点击该外链,之后进入网页,需要使用微信扫码授权登录。
6、扫码授权之后,就可以进入到微信书网页版了,如下图所示。
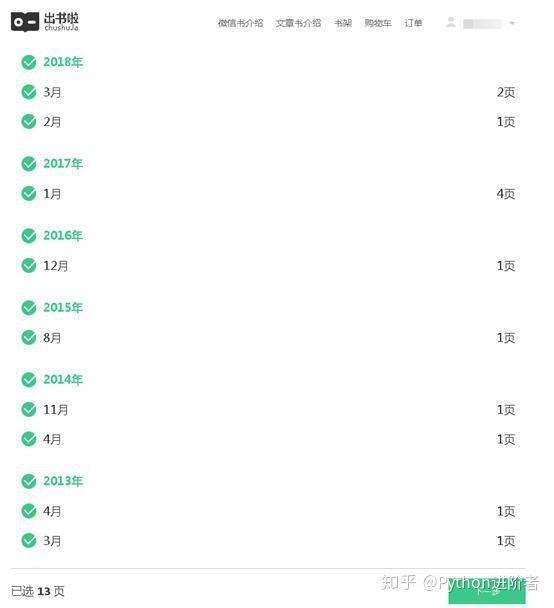
7、接下来我们就可以正常的写爬虫程序进行抓取信息了。在这里,小编采用的是Scrapy爬虫框架,Python用的是3版本,集成开发环境用的是Pycharm。下图是微信书的首页,图片是小编自己自定义的。

二、创建爬虫项目
1、确保您的电脑上已经安装好了Scrapy。之后选定一个文件夹,在该文件夹下进入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
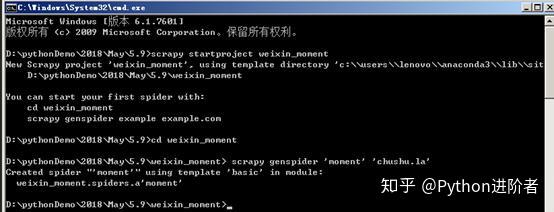
2、在命令行中输入cd weixin_moment,进入创建的weixin_moment目录。之后输入命令:
scrapy genspider 'moment' 'chushu.la'
,创建朋友圈爬虫,如下图所示。
3、执行以上两步后的文件夹结构如下:
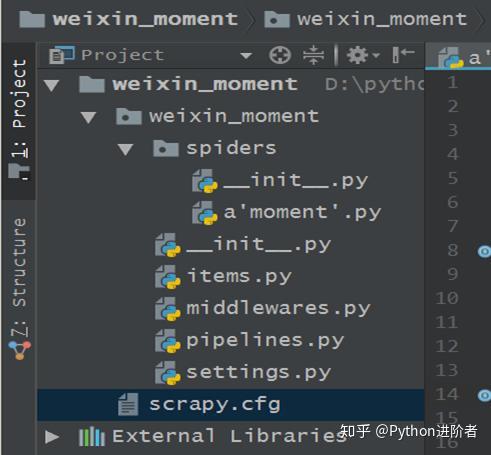
三、分析网页数据
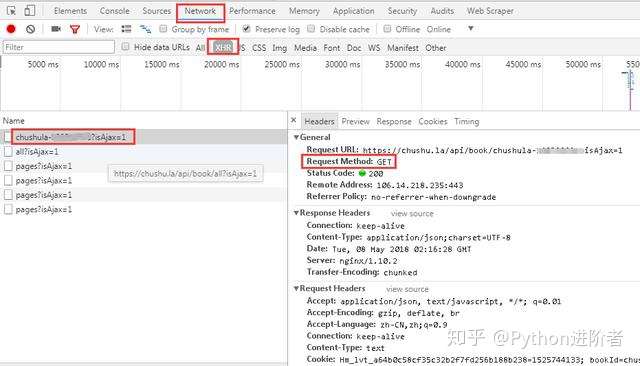
1、进入微信书首页,按下F12,建议使用谷歌浏览器,审查元素,点击“Network”选项卡,然后勾选“Preserve log”,表示保存日志,如下图所示。可以看到主页的请求方式是get,返回的状态码是200,代表请求成功。
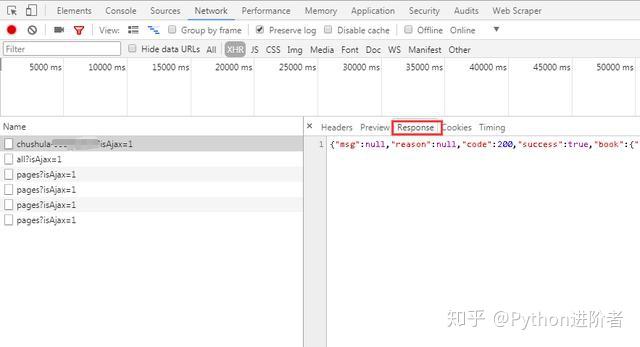
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明我们之后在程序中需要对JSON格式的数据进行处理。
3、点击微信书的“导航”窗口,可以看到数据是按月份进行加载的。当点击导航按钮,其加载对应月份的朋友圈数据。
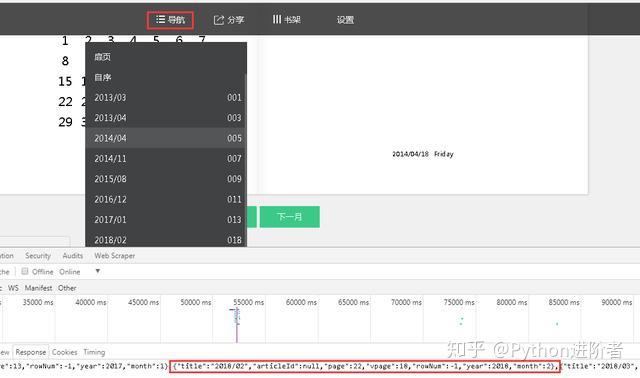
4、当点击【2014/04】月份,之后查看服务器响应数据,可以看到页面上显示的数据和服务器的响应是相对应的。
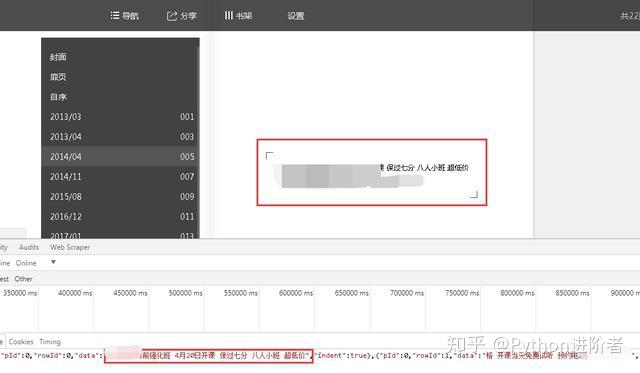
5、查看请求方式,可以看到此时的请求方式变成了POST。细心的伙伴可以看到在点击“下个月”或者其他导航月份的时候,主页的URL是始终没有变化的,说明该网页是动态加载的。之后对比多个网页请求,我们可以看到在“Request Payload”下边的数据包参数不断的发生变化,如下图所示。
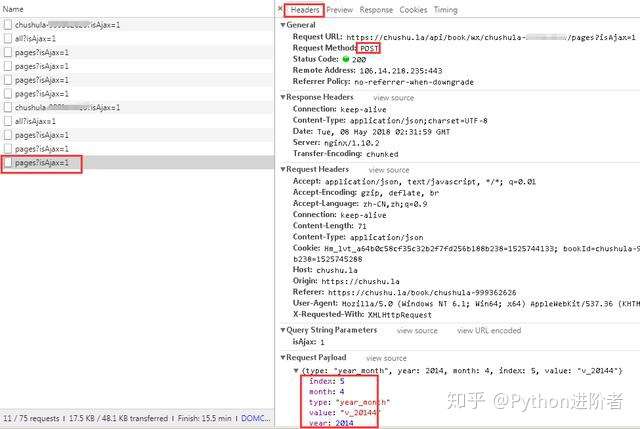
6、展开服务器响应的数据,将数据放到JSON在线解析器里,如下图所示:
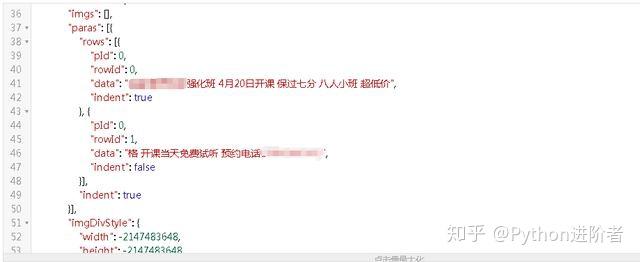
可以看到朋友圈的数据存储在paras /data节点下。
至此,网页分析和数据的来源都已经确定好了,接下来将写程序,进行数据抓取,敬请期待下篇文章~~