HashMap存储结构
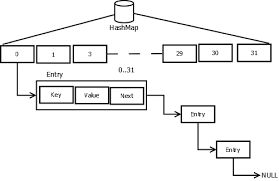
HashMap中数据的存储是由数组与链表一起实现的
数组寻址非常容易,其时间复杂度为O(1),但是当要插入或删除数据时,时间复杂度就会变为O(n)。链表插入和删除操作的内存复杂度为O(1),但是寻址操作的复杂度却是O(n)。HashMap结合两者的优点,即寻址,插入删除都快。
HashMap中定义了一个Entry类的数组table, Entry<K,V>[] table; 数组table中存储的是Entry对象(也是Entry链表的头结点)。
Entry对象中保存的是Key-Value对。
其中数组table被称作buckets,每个数组节点则是一个bucket(可以构成一个链表)
capacity指的是buckets的容量,也即数组的大小,默认capacity大小如下
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 16;
load factor是衡量buckets填满程度的比例,默认load factor大小如下
/** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f;
当buckets中entry数量大于capacity*loadfactor时就要把capacity扩充为原来的两倍。
HashMap中方法
添加键值对put(K key, V value)方法
实现流程如下:
进行key是否为null的判断,如果key==null ,放置在数组table的0号位置,即table[0]。
若key不为null,由key的hashCode计算相应的hash值,进而得到该key对应的数组table的下标i。
判断table[i] 是否为null(不包含任何键值对),若是则创建该键值对的Entry对象,添加至table[i]。
若table[i]不为null,遍历table[i]链表中的每个Entry对象,若该链表中已包含key,则覆盖其value。若该链表中不包含key,则创建该键值对的Entry对象并添加至链表头部。
实现代码如下:
public V put(K key, V value) { // HashMap允许存放null键和null值。 // 当key为null时,调用putForNullKey方法,将value放置在数组table第一个位置。 if (key == null) return putForNullKey(value); // 根据key的hashCode计算hash值。 int hash = hash(key.hashCode()); // 由hash值求得key对应table的下标。 int i = indexFor(hash, table.length); // 如果 i 索引处的 Entry 不为 null,遍历table[i]链表的每一个Entry对象 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; // 如果链表中已有键值key,则新的value覆盖原来的,并返回原来的value // 判断为同一个键值的方法是,hash值相同,且key相同 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; // 若table[i]为null,则创建key,value的Entry对象,并添加至table[i]处 // 若table[i]链表中没有键值key,则创建key,value的Entry对象,并添加至table[i]处 addEntry(hash, key, value, i); return null; }
addEntry()方法
void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); //扩容操作,将数据元素重新计算位置后放入newTable中,链表的顺序与之前的顺序相反 hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); } void createEntry(int hash, K key, V value, int bucketIndex) { // 若table[i]不为null,则e指向table[i]链表的第一个元素 Entry<K,V> e = table[bucketIndex]; // 新的Entry对象添加至table[i]的表头 table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
get()方法
计算hash值,然后调用indexFor()方法得到该key在table中的存储位置,得到该位置的单链表,遍历列表找到key和指定key内容相等的Entry,返回entry.value值
实现代码如下:
public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null; }
HashMap的resize
当hashmap中的元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对hashmap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,所以这是一个通用的操作,很多人对它的性能表示过怀疑,不过想想我们的“均摊”原理,就释然了,而在hashmap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。