hdfs的写入过程和读取过程
hdfs的写入过程
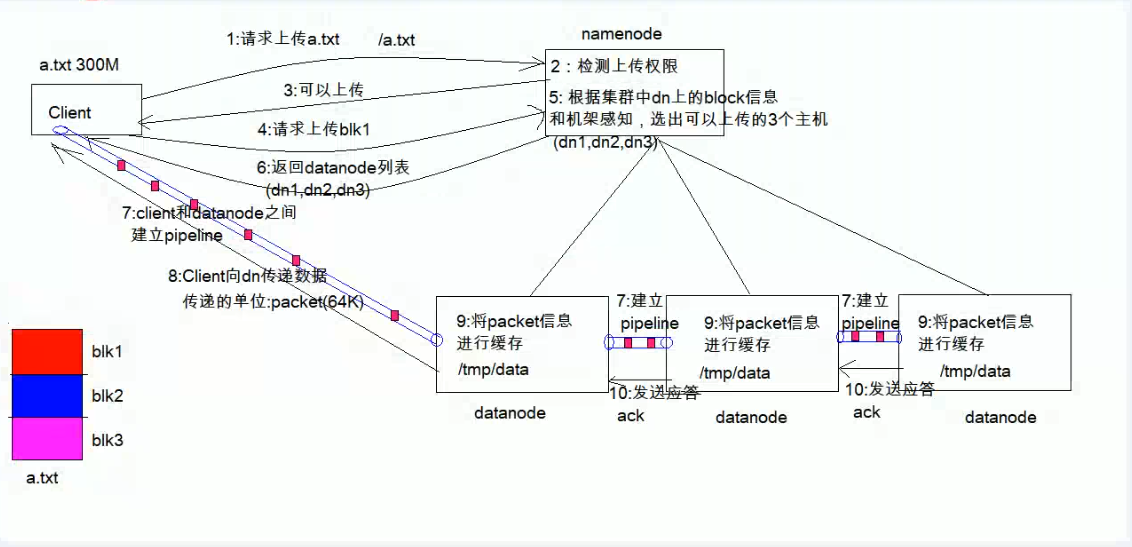
1、客户端(Client)发出请求(将请求发给namenode),要将大小为300M的a.txt文件上传到 根目录下(/a.txt)
2、namenode对收到的请求做出检测;检测1:所上传的路径下是否存在该文件,(即根目录下是否有a.txt),检测2:检测客户端是否有上传权限
3、检测通过,反馈给客户端 可以上传的指令
4、客户端接到反馈,将文件进行预处理(a.txt大小为300M,一个block的大小默认为128M,因此分为3个block(如上图红、蓝、浅紫色三块block),编号为block0,block1,block2,其中block2不满128M),向namenode发出上传block0的请求。
5、namenode根据集群中各个datanode上的block信息和机架感知,选出可以上传的3个主机(a.txt有三个副本),分别是datanode1,datanode2,datanode3
6、将datanode列表(这里有三个)返回给客户端。
7、客户端和datanode1建立输出流pipeline,用于传输文件
datanode1与datanode2之间建立输出流,datanode2与datanode3之间建立输出流。
8、客户端将每个大小为128M的block切分为64KB的数据包(单位为packet,64KB)并传输给datanode1。
9、datanode1接收packet信息并缓存到对应的目录下,再将packet传输给datanode2,同理datanode2接收packet信息并缓存到对应目录下,再传给datanode3,datanode3接收packet,并缓存。
10、 最后一台机器缓存完packet信息后会依次向上一级发送应答,最终第一台机器datanode1向客户端发送缓存完成的应答。
11、跳转到第四步,客户端向namenode发出上传block1的请求,重复4-10,直到第三个block2传输完成后,写入完成。
hdfs的读取过程
