1,首先确保hadoop和spark已经运行。(如果是基于yarn,hdfs的需要启动hadoop,否则hadoop不需要启动)。
2.打开idea,创建maven工程。编辑pom.xml文件。增加dependency.
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
3.编写SimpleApp.java
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; /** * TODO * * @ClassName: SimpleApp * @author: DingH * @since: 2019/3/26 11:30 */ public class SimpleApp { public static void main(String[] args) { String textfile = "file:///usr/local/spark/README.md"; SparkConf conf1 = new SparkConf().setAppName("SimpleApp"); JavaSparkContext sc = new JavaSparkContext(conf1); JavaRDD<String> data = sc.textFile(textfile).cache(); long numAs = data.filter(new Function<String, Boolean>() { public Boolean call(String s) throws Exception { return s.contains("a"); } }).count(); long numBs = data.filter(new Function<String, Boolean>() { public Boolean call(String s) throws Exception { return s.contains("b"); } }).count(); System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs); } }
4.执行程序(肯定会有错,因为这个路径是ubuntu上spark的readme文件路径,如果想要在本地实验,修改本地文件系统中的一个文件路径就行,这个同时还有conf.setmaster("local")),打包。
5.将目标路径下的target文件夹拷贝到服务器端。
6.如果是client模式,直接执行:
ubuntu@master:/usr/local/spark$ ./bin/spark-submit --class "SimpleApp" --deploy-mode client --master spark://172.19.57.221:7077 ~/target/SimpleApp-1.0-SNAPSHOT.jar

7.如果是cluster上,则需要把target上传到slave01的用户目录下。然后执行:
ubuntu@master:/usr/local/spark$ ./bin/spark-submit --class "SimpleApp" --deploy-mode cluster --master spark://172.19.57.221:7077 ~/target/SimpleApp-1.0-SNAPSHOT.jar
这个方式执行的结果只能在webUI上看。
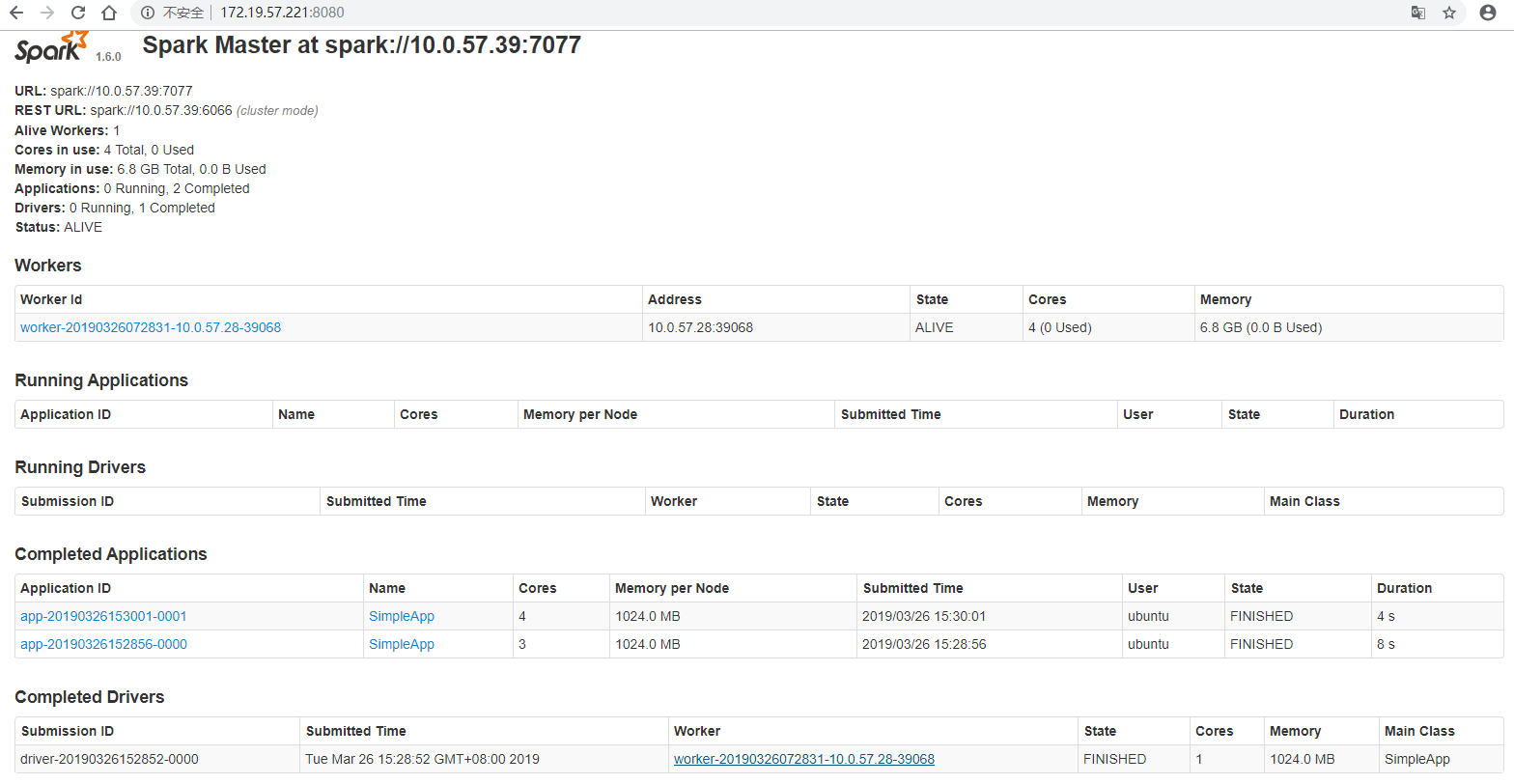
在http://172.19.57.221:8080/上,可以看到spark master。
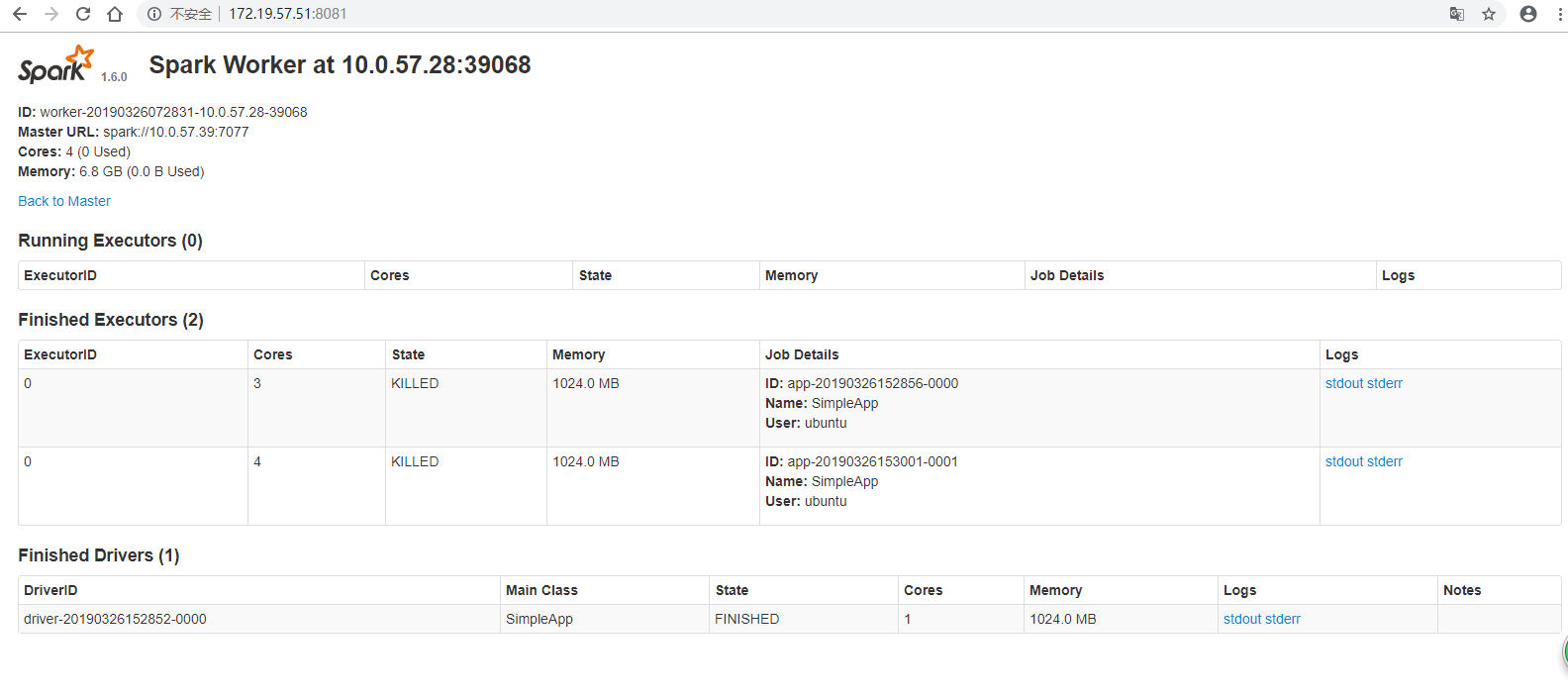
在http://172.19.57.51:8081/上,可以看到spark worker。
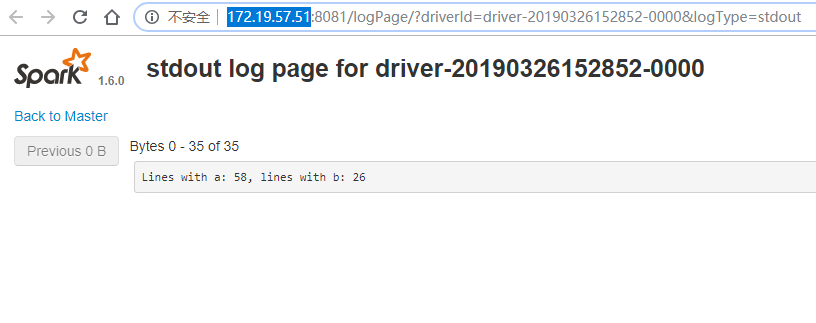
点击Finished Drivers里面的stdout就可以查看执行的结果。
完结~