大致描述
这一篇工作是在Zeng 2014基础上的扩展,从Fully Supervised 到Distant Supervised. 动机
- Distant supervised 会产生有大量噪音或者被错误标注的数据,直接使用supervised的方法进行关系分类,效果很差。
- 原始方法大都是基于词法、句法特征来处理, 无法自动提取特征。而且句法树等特征在句子长度边长的话,正确率很显著下降。
因此文中使用Multi Instance Learning的at least one假设来解决第一个问题; 在Zeng 2014 的CNN基础上修改了Pooling的方式,解决第二个问题。 先介绍改进的CNN: Piece Wise CNN(PCNN). 总体结构如下, 与Zeng 2014 很类似:
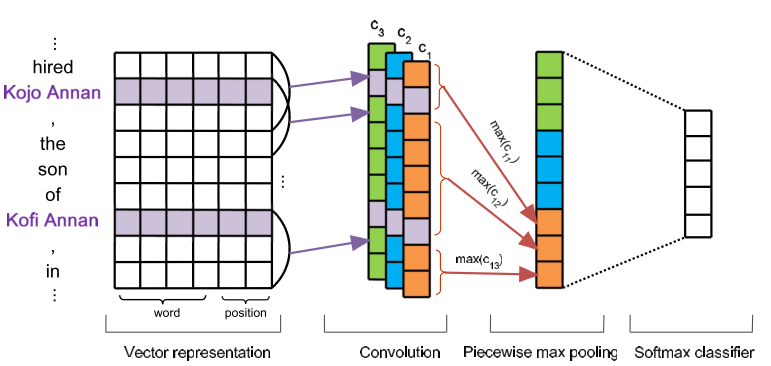
输入仍然是一个sentence,Input Layer依然是word embedding + position embedding, 后面接卷积操作。 之后的Pooling层并没有直接使用全局的Max Pooling, 而是局部的max pooling. 文中把一个句子分为三部分,以两个entity为边界把句子分为三段,然后卷积之后对每一段取max pooling, 这样可以得到三个值,相比传统的max-pooling 每个卷积核只能得到一个值,这样可以更加充分有效的得到句子特征信息。 假设一共有个N个卷积核,最终pooling之后得到的sentence embedding的size为: 3N3N, 后面再加softmax进行分类,最终得到输出向量oo, 上面的示意图很清晰了,其中的c1,c2,c3是不同卷积核的结果,然后都分为3段进行Pooling。 下面可以减弱错误label问题的Multi-Instance Learning。这里面有一个概念, 数据中包含两个entity的所有句子称为一个Bag。先做几个定义:
- M=M1,M2,...,MTM=M1,M2,...,MT 表示训练数据中的T个bags,每个bags都有一个relation标签.
- Mi=m1i,m2i,...,mqiiMi=mi1,mi2,...,miqi 表示第i个bag内有qiqi个instance,也就是句子。
- oo 表示给定mimi的网络模型的输出(未经过softmax),其中oror 表示第rr个relation的score
这样经过softmax 就可以计算每一个类别的概率了
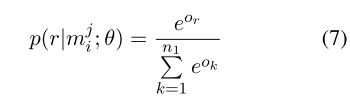
这里需要说明的是,我们的目的得到每个bag的标签,并不关注bag里面instances的。因为每个bag上的label就是两个entity的relation。 而上面的概率是计算的bag里面某一个instance的,所以需要定义基于Bag的损失函数,文中采取的措施是根据At-Least-One的假设,每个Bag都有至少有一个标注正确的句子,这样就可以从每个bag中找一个得分最高的句子来表示整个bag,于是定义如下的目标函数: 假设训练数据为T个bags: <Mi,yi><Mi,yi>:
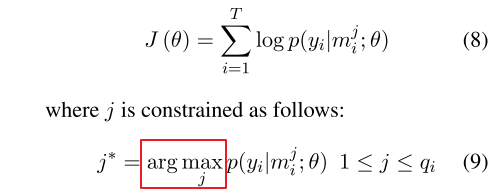
这样到此为止,模型部分完毕
细致描述
(一)论文的贡献
1、用PCNNs的神经网络结构自动学习文本特征,代替复杂的人工构造特征和特征处理流程。
PCNNs全名为Piecewise Convolutional Neural Networks,包含两层含义:Piecewise max pooling layer和Convolutional Neural Networds,对应到最大池化层和卷积层。用卷积神经网络强大的特征提取功能,能自动抽取丰富的特征,并且减少人工设计特征和NLP工具库抽取特征带来的误差。省时省力又能减少误差,何乐不为。
2、设计了分段最大池化层(三段,Piecewise max pooling layer)代替一般的最大池化层,提取更丰富的文本结构特征。
一般的最大池化层直接从多个特征中选出一个最重要的特征,实际上是对卷积层的输出进行降维,但问题是维度降低过快,无法获取实体对在句子中所拥有的结构信息。
如下图,把一个句子按两个实体切分为前、中、后三部分的词语,然后将一般的最大池化层相应地划分为三段最大池化层,从而获取句子的结构信息。

3、用多实例学习(Multi-Instances Learning)解决远程监督做自动标注的错误标注问题。
远程监督本质上是一种自动标注样本的方法,但是它的假设太强了,会导致错误标注样本的问题。
论文认为远程监督做关系抽取类似于多实例问题(Multi-Instances Problem)。知识图谱中一个实体对(论文中的Bag)的关系是已知的,而外部语料库中包含该实体对的多个句子(Instances of Bag),表达的关系是未知的(自动标注的结果未知真假),那么多实例学习的假设是:这些句子中至少有一个句子表达了已知的关系。于是从多个句子中只挑出最重要的一个句子,作为这个实体对的样本加入到训练中。
本篇论文设计了一个目标函数,在学习过程中,把句子关系标签的不确定性考虑进去,从而缓解错误标注的问题。
总结一下,本文的亮点在于把多实例学习、卷积神经网络和分段最大池化结合起来,用于缓解句子的错误标注问题和人工设计特征的误差问题,提升关系抽取的效果。
(二)研究方法
本文把PCNNs的神经网络结构和多实例学习结合,完成关系抽取的任务。
1、PCNNs网络的处理流程
PCNNs网络结构处理一个句子的流程分为四步:特征表示、卷积、分段最大池化和softmax分类。具体如下图所示。

(1)文本特征表示
使用词嵌入(Word Embeddings)和位置特征嵌入(Position Embeddings),然后把句子中每个词的这两种特征拼接起来。
词嵌入使用的是预训练的Word2Vec词向量,用Skip-Gram模型来训练。
位置特征是某个词与两个实体的相对距离,位置特征嵌入就是把两个相对距离转化为向量,再拼接起来。
比如下面这个句子中,单词son和实体Kojo Annan的相对距离为3,和实体Kofi Annan的相对距离为-2。

假设词嵌入的维度是dw,位置特征嵌入的维度是dp,那么每个词的特征向量的维度就是:d=dw+2*dp。假设句子长度为s,那么神经网络的输入就是s×d维的矩阵。
(2)卷积
假设卷积核的宽为w(滑动窗口),长为d(词的特征向量维度),那么卷积核的大小为W=w * d。步长为1。
输入层为q = s×d维的矩阵,卷积操作就是每滑动一次,就用卷积核W与q的w-gram做点积,得到一个数值。

卷积完成后会得到(s+w-1)个数值,也就是长度为(s+w-1)的向量c。文本的卷积和图像的卷积不同,只能沿着句子的长度方向滑动,所以得到的是一个向量而不是矩阵。
为了得到更丰富的特征,使用了n个卷积核W={W1, W2, ... Wn},第i个卷积核滑动一次得到的数值为:
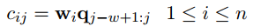
最终,卷积操作完成后会输出一个矩阵C:
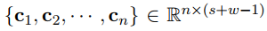
(3)分段最大池化
把每个卷积核得到的向量ci按两个实体划分为三部分{ci1, ci2, ..., ci3},分段最大池化也就是分别取每个部分的最大值:
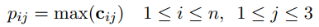
那么对于每个卷积核得到的向量ci,我们都能得到一个3维的向量pi。为了便于下一步输入到softmax层,把n个卷积核经过池化后的向量pi拼接成一个向量p1:n,长度为3n。
最后用tanh激活函数进行非线性处理,得到最终的输出:

(4)softmax多分类
把池化层得到的g输入到softmax层,计算属于每种关系的概率值。论文中使用了Dropout正则化,把池化层的输出g以r的概率随机丢弃,得到的softmax层的输出为:
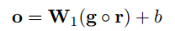

输出的向量是关系的概率分布,长度为关系的种类(n1)。概率值最大的关系就是句子中的实体对被预测的关系。
2、多实例学习的过程
我们知道一般神经网络模型的套路是,batch-size个句子经过神经网络的sotfmax层后,得到batch-size个概率分布,然后与关系标签的one-hot向量相比较,计算交叉熵损失,最后进行反向传播。因此上述PCNNs网络结构的处理流程仅是一次正向传播的过程。
PCNNs结合多实例学习的做法则有些差别,目标函数仍然是交叉熵损失函数,但是基于实体对级别(论文中的bags)去计算损失,而不是基于句子级别(论文中的instances)。这是什么意思呢?
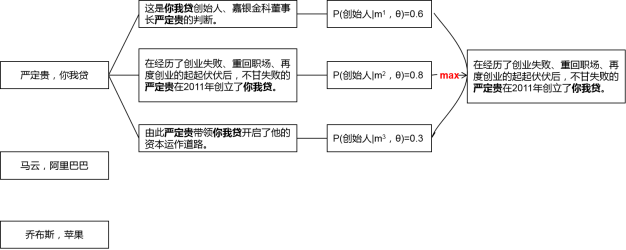
对照上面的图,计算交叉熵损失分为两步:
第一步,对于每个实体对,会有很多包含该实体对的句子(qi个),每个句子经过softmax层都可以得到一个概率分布,进而得到预测的关系标签和概率值。为了消除错误标注样本的影响,从这些句子中仅挑出一个概率值最大的句子和它的预测结果,作为这个实体对的预测结果,用于计算交叉熵损失。比如上面的例子中,挑出了第二个句子。公式为:

第二步,如果一个batch-size有T个实体对,那么用第一步挑选出来的T个句子,计算交叉熵损失:
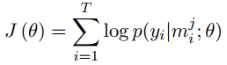
最后用梯度下降法求出梯度,并进行误差反向传播。
如下是算法的伪代码,θ是PCNNs的参数,Eq.(9)是第一步中的公式。

(四)实验细节
1、数据集和评估方法
知识图谱为Freebase,外部文档库为NYT。把NYT文档库中2005-2006年的句子作为训练集,2007年的句子作为测试集。
评估方法沿用第一篇论文中的方法,留出法和人工校验相结合。
2、词嵌入和调参
预训练的词向量方面,本文用Skip-Gram模型和NYT文档库训练了50维的词向量。
位置特征嵌入使用随机初始化的向量,维度为5。
调参方面,PCNNs网络结构中有两个参数比较重要:卷积核的滑动窗口大小和卷积核的个数。本文使用网格搜索,最终确定滑动窗口为3,卷积核个数为230。
模型的其他参数如下:

3、模型评估结果
(1)对留出法和人工校验法的说明
使用留出法和人工校验法来评估模型的效果。这里对这两种评估方法进行补充说明:
留出法的做法是把Freebase中一半的实体对用于训练,一半的实体对用于测试。多分类模型训练好之后,对外部文档库NYT中的测试集进行预测,得到测试集中实体对的关系标签。如果新发现的实体对有N个,其中有n个出现在Freebase的测试集中,那么准确率为n/N,而不在Freebase测试集中的实体对就视为不存在关系。可是由于Freebase中的实体对太少了,新发现的、不在Freebase里的实体对并非真的不存在关系,这就会出现假负例(False Negatives)的问题,低估了准确率。
所以人工校验的方法是对留出法的一个补充,对于那些新发现的、不在Freebase测试集中的实体对(一个实体不在或者两个实体都不在)进行检查,计算查准率。所以留出法和人工校验要评估的两个新实体对集合是没有交集的。具体做法是从这些新实体对中选择概率值最高的前N个,然后人工检查其中关系标签正确的实体对,如果有n个,那么查准率为n/N。
(2)卷积神经网络与人工构造特征的对比
首先把PCNNs结合多实例学习的远程监督模型(记为PCNNs+MIL),与人工构造特征的远程监督算法(记为Mintz)和多实例学习的算法(记为MultiR和MIML)进行比较。
从下面的实验结果中可以看到,无论是查准率还是查全率,PCNNs+MIL模型都显著优于其他模型,这说明用卷积神经网络作为自动特征抽取器,可以有效降低人工构造特征和NLP工具提取特征带来的误差。

(3)分段最大池化和多实例学习的有效性
将分段最大池化和普通的最大池化的效果进行对比(PCNNs VS CNNs),将结合多实例学习的卷积网络与单纯的卷积网络进行对比(PCNNs+MIL VS PCNNs)。
可以看到,分段最大池化比普通的最大池化效果更好,表明分段最大池化可以抽取更丰富的结构特征。把多实例学习加入到卷积网络中,效果也有一定的提升,表明多实例学习可以缓解样本标注错误的问题。

(四)评价
这篇论文中,分段最大池化的奇思妙想来自于传统人工构造特征的思想,而多实例学习的引入缓解了第一篇论文中的样本错误标注问题。这篇论文出来以后是当时的SOTA。
不足之处在于,多实例学习仅从包含某个实体对的多个句子中,挑出一个最可能的句子来训练,这必然会损失大量的信息。所以有学者提出用句子级别的注意力机制来解决这个问题。