Task6 基于深度学习的文本分类3
基于深度学习的文本分类
学习目标
- 了解Transformer的原理和基于预训练语言模型(Bert)的词表示
- 学会Bert的使用,具体包括pretrain和finetune
文本表示方法Part4
Transformer原理
Transformer是在"Attention is All You Need"中提出的,模型的编码部分是一组编码器的堆叠(论文中依次堆叠六个编码器),模型的解码部分是由相同数量的解码器的堆叠。
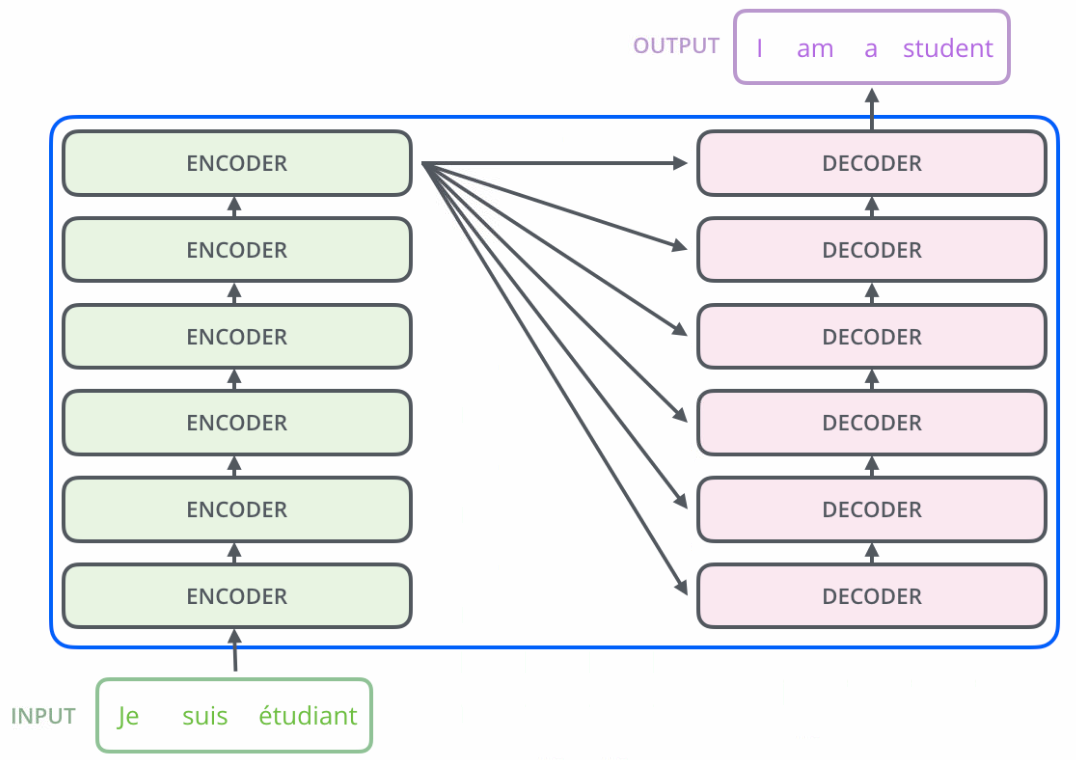
我们重点关注编码部分。他们结构完全相同,但是并不共享参数,每一个编码器都可以拆解成两部分。在对输入序列做词的向量化之后,它们首先流过一个self-attention层,该层帮助编码器在它编码单词的时候能够看到输入序列中的其他单词。self-attention的输出流向一个前向网络(Feed Forward Neural Network),每个输入位置对应的前向网络是独立互不干扰的。最后将输出传入下一个编码器。
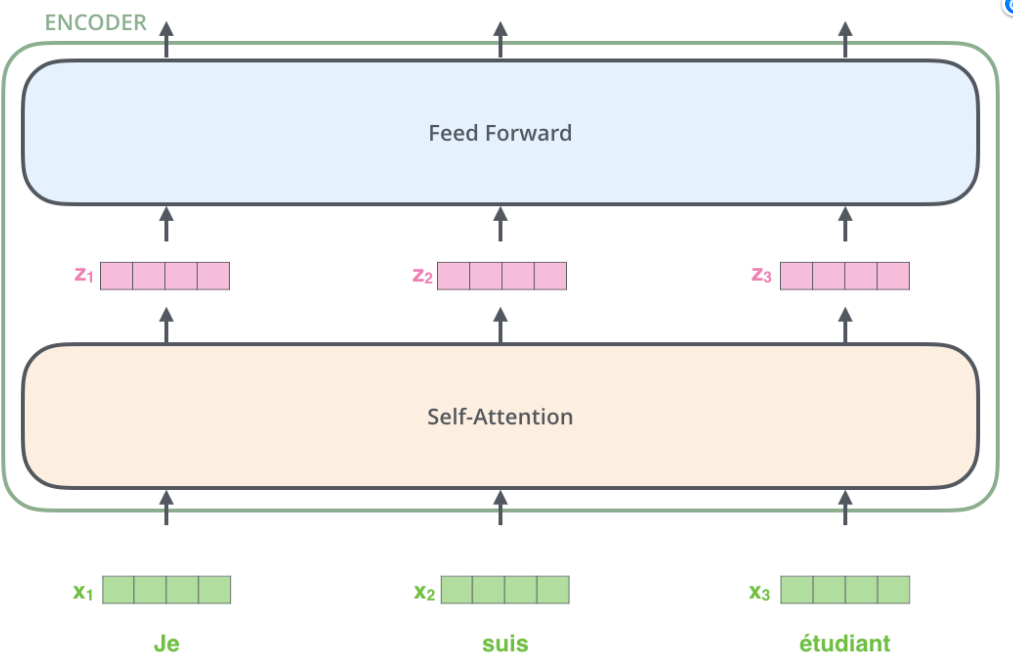
这里能看到Transformer的一个关键特性,每个位置的词仅仅流过它自己的编码器路径。在self-attention层中,这些路径两两之间是相互依赖的。前向网络层则没有这些依赖性,但这些路径在流经前向网络时可以并行执行。
Self-Attention中使用多头机制,使得不同的attention heads所关注的的部分不同。
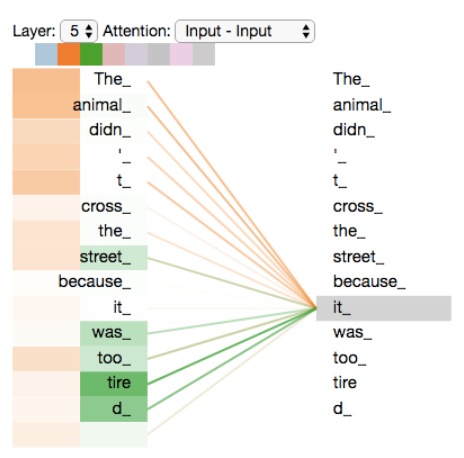
编码"it"时,一个attention head集中于"the animal",另一个head集中于“tired”,某种意义上讲,模型对“it”的表达合成了的“animal”和“tired”两者。
对于自注意力的详细计算,欢迎大家参考Jay Alammar关于Transformer的博客,这里不再展开。
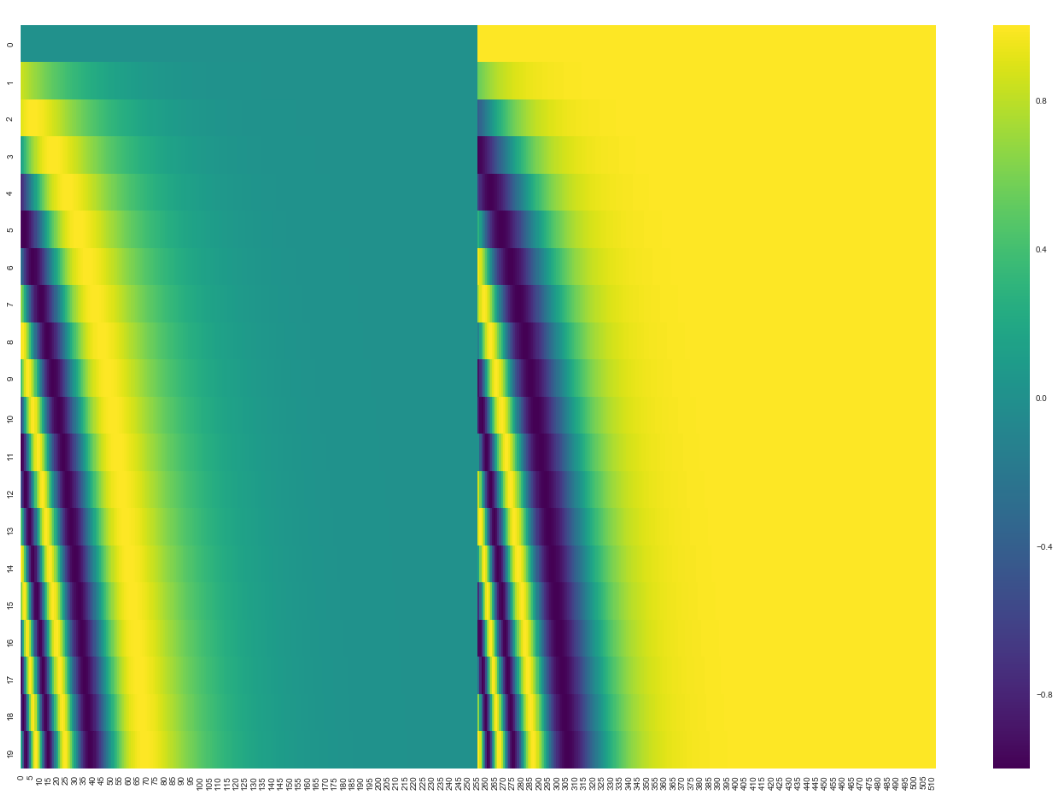
除此之外,为了使模型保持单词的语序,模型中添加了位置编码向量。如下图所示,每行对应一个向量的位置编码。因此,第一行将是我们要添加到输入序列中第一个单词的嵌入的向量。每行包含512个值—每个值都在1到-1之间。因为左侧是用sine函数生成,右侧是用cosine生成,所以可以观察到中间显著的分隔。
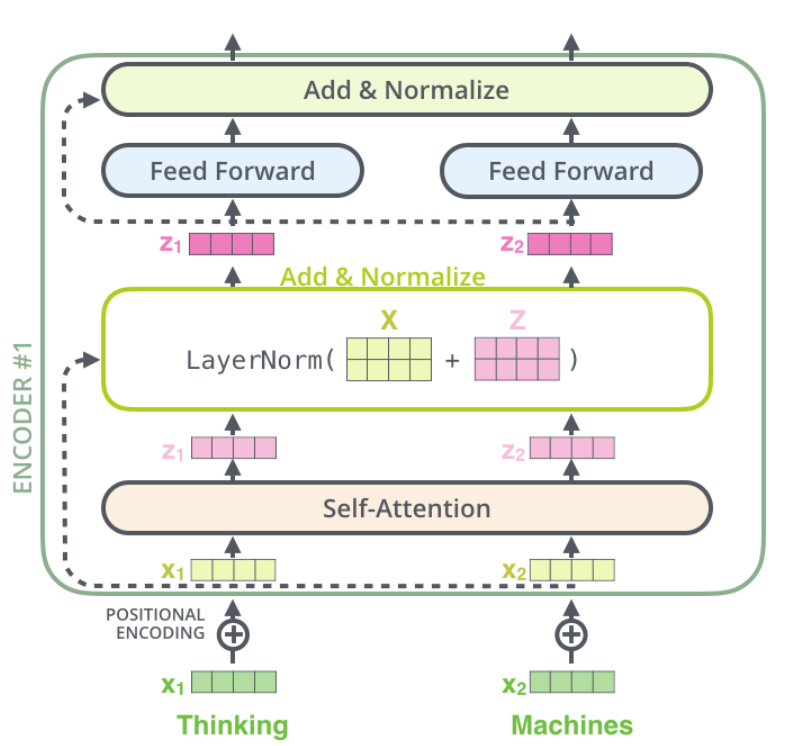
编码器结构中值得提出注意的一个细节是,在每个子层中(Self-attention, FFNN),都有残差连接,并且紧跟着layer-normalization。如果我们可视化向量和LayerNorm操作,将如下所示:
基于预训练语言模型的词表示
基于预训练语言模型的词表示由于可以建模上下文信息,进而解决传统静态词向量不能建模“一词多义”语言现象的问题。最早提出的ELMo基于两个单向LSTM,将从左到右和从右到左两个方向的隐藏层向量表示拼接学习上下文词嵌入。而GPT用Transformer代替LSTM作为编码器,首先进行了语言模型预训练,然后在下游任务微调模型参数。但GPT由于仅使用了单向语言模型,因此难以建模上下文信息。为了解决以上问题,研究者们提出了BERT,BERT模型结构如下图所示,它是一个基于Transformer的多层Encoder,通过执行一系列预训练,进而得到深层的上下文表示。
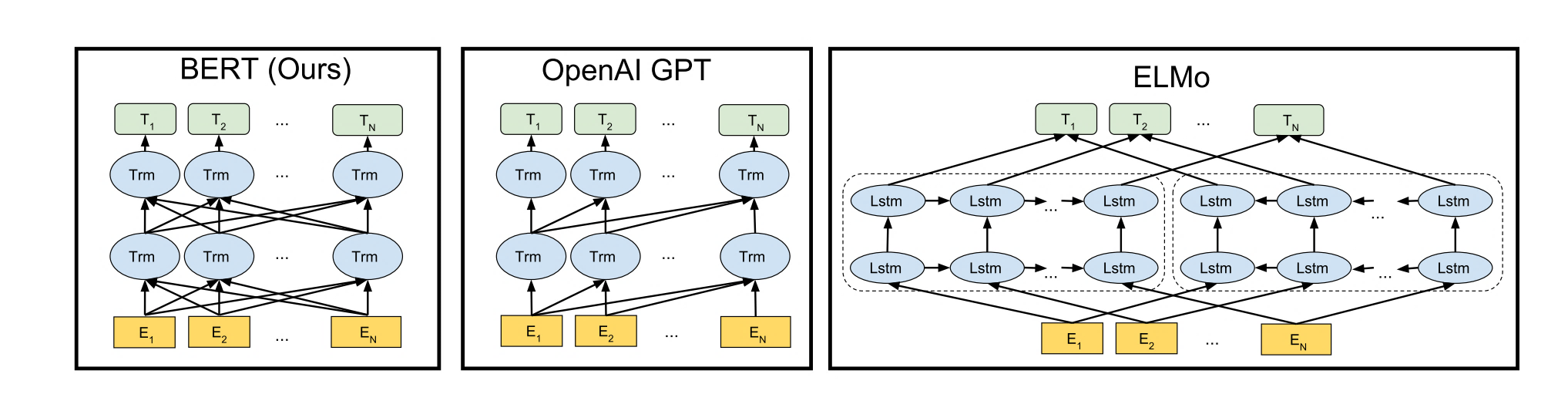
ELMo论文题目中Deep是指双向双层LSTM,而更关键的在于context。传统方法生成的单词映射表的形式,即先为每个单词生成一个静态的词向量,之后这个单词的表示就被固定住了,不会跟着上下文的变化而做出改变。事实上,由于一词多义的语言现象,静态词向量是有很大的弊端的。以bank为例,如果训练语料的足够大,事先学好的词向量中混杂着所有的语义。而当下游应用时,即使在新句子中,bank的上下文里包含money等词,我们基本可以确定bank是“银行”的语义而不是在其他上下文中的“河床”的语义,但是由于静态词向量不能跟随上下文而进行变化,所以bank的表示中还是混杂着多种语义。为了解决这一问题,ELMo首先进行了语言模型预训练,然后在下游任务中动态调整Word Embedding,因此最后输出的词表示能够充分表达单词在上下文中的特定语义,进而解决一词多义的问题。
GPT来自于openai,是一种生成式预训练模型。GPT 除了将ELMo中的LSTM替换为Transformer 的Encoder外,更开创了NLP界基于预训练-微调的新范式。尽管GPT采用的也是和ELMo相同的两阶段模式,但GPT在第一个阶段并没有采取ELMo中使用两个单向双层LSTM拼接的结构,而是采用基于自回归式的单向语言模型。
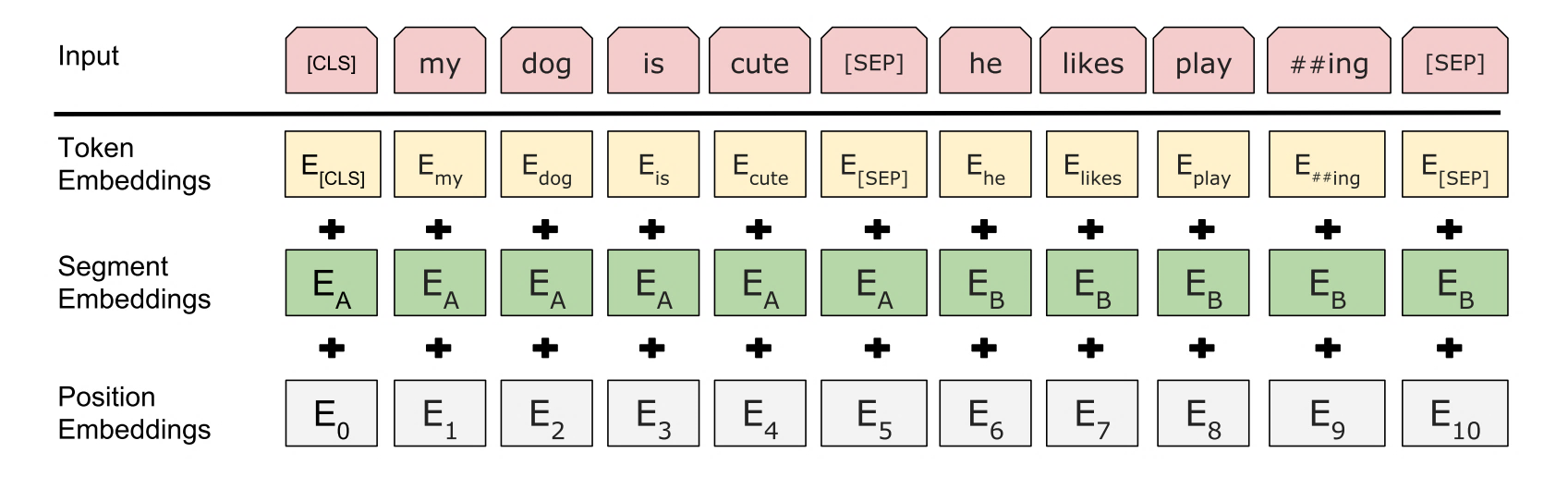
Google在NAACL 2018发表的论文中提出了BERT,与GPT相同,BERT也采用了预训练-微调这一两阶段模式。但在模型结构方面,BERT采用了ELMO的范式,即使用双向语言模型代替GPT中的单向语言模型,但是BERT的作者认为ELMo使用两个单向语言模型拼接的方式太粗暴,因此在第一阶段的预训练过程中,BERT提出掩码语言模型,即类似完形填空的方式,通过上下文来预测单词本身,而不是从右到左或从左到右建模,这允许模型能够自由地编码每个层中来自两个方向的信息。而为了学习句子的词序关系,BERT将Transformer中的三角函数位置表示替换为可学习的参数,其次为了区别单句和双句输入,BERT还引入了句子类型表征。BERT的输入如图所示。此外,为了充分学习句子间的关系,BERT提出了下一个句子预测任务。具体来说,在训练时,句子对中的第二个句子有50%来自与原有的连续句子,而其余50%的句子则是通过在其他句子中随机采样。同时,消融实验也证明,这一预训练任务对句间关系判断任务具有很大的贡献。除了模型结构不同之外,BERT在预训练时使用的无标签数据规模要比GPT大的多。
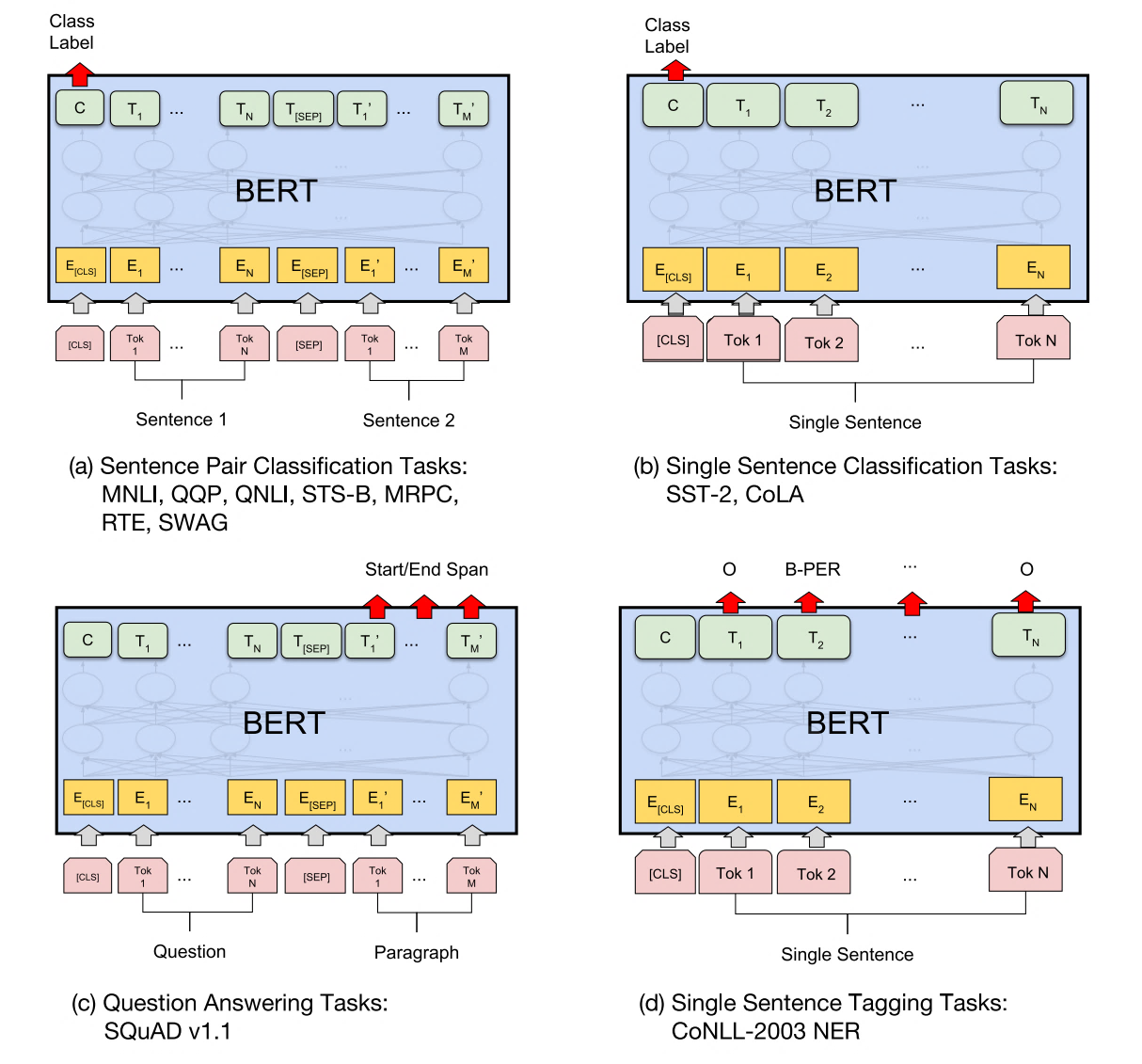
在第二阶段,与GPT相同,BERT也使用Fine-Tuning模式来微调下游任务。如下图所示,BERT与GPT不同,它极大的减少了改造下游任务的要求,只需在BERT模型的基础上,通过额外添加Linear分类器,就可以完成下游任务。具体来说,对于句间关系判断任务,与GPT类似,只需在句子之间加个分隔符,然后在两端分别加上起始和终止符号。在进行输出时,只需把句子的起始符号[CLS]在BERT最后一层中对应的位置接一个Softmax+Linear分类层即可;对于单句分类问题,也与GPT类似,只需要在句子两段分别增加起始和终止符号,输出部分和句间关系判断任务保持一致即可;对于问答任务,由于需要输出答案在给定段落的起始和终止位置,因此需要先将问题和段落按照句间关系判断任务构造输入,输出只需要在BERT最后一层中第二个句子,即段落的每个单词对应的位置上分别接判断起始和终止位置的分类器;最后,对于NLP中的序列标注问题,输入与单句分类任务一致,不同的是在BERT最后一层中每个单词对应的位置上接分类器即可。
更重要的是,BERT开启了NLP领域“预训练-微调”这种两阶段的全新范式。在第一阶段首先在海量无标注文本上预训练一个双向语言模型,这里特别值得注意的是,将Transformer作为特征提取器在解决并行性和长距离依赖问题上都要领先于传统的RNN或者CNN,通过预训练的方式,可以将训练数据中的词法、句法、语法知识以网络参数的形式提炼到模型当中,在第二阶段使用下游任务的数据Fine-tuning不同层数的BERT模型参数,或者把BERT当作特征提取器生成BERT Embedding,作为新特征引入下游任务。这种两阶段的全新范式尽管是来自于计算机视觉领域,但是在自然语言处理领域一直没有得到很好的运用,而BERT作为近些年NLP突破性进展的集大成者,最大的亮点可以说不仅在于模型性能好,并且几乎所有NLP任务都可以很方便地基于BERT进行改造,进而将预训练学到的语言学知识引入下游任务,进一步提升模型的性能。
基于Bert的文本分类
Bert Pretrain
预训练过程使用了Google基于Tensorflow发布的BERT源代码。首先从原始文本中创建训练数据,由于本次比赛的数据都是ID,这里重新建立了词表,并且建立了基于空格的分词器。
class WhitespaceTokenizer(object):
"""WhitespaceTokenizer with vocab."""
def __init__(self, vocab_file):
self.vocab = load_vocab(vocab_file)
self.inv_vocab = {v: k for k, v in self.vocab.items()}
def tokenize(self, text):
split_tokens = whitespace_tokenize(text)
output_tokens = []
for token in split_tokens:
if token in self.vocab:
output_tokens.append(token)
else:
output_tokens.append("[UNK]")
return output_tokens
def convert_tokens_to_ids(self, tokens):
return convert_by_vocab(self.vocab, tokens)
def convert_ids_to_tokens(self, ids):
return convert_by_vocab(self.inv_vocab, ids)
预训练由于去除了NSP预训练任务,因此将文档处理多个最大长度为256的段,如果最后一个段的长度小于256/2则丢弃。每一个段执行按照BERT原文中执行掩码语言模型,然后处理成tfrecord格式。
def create_segments_from_document(document, max_segment_length):
"""Split single document to segments according to max_segment_length."""
assert len(document) == 1
document = document[0]
document_len = len(document)
index = list(range(0, document_len, max_segment_length))
other_len = document_len % max_segment_length
if other_len > max_segment_length / 2:
index.append(document_len)
segments = []
for i in range(len(index) - 1):
segment = document[index[i]: index[i+1]]
segments.append(segment)
return segments
在预训练过程中,也只执行掩码语言模型任务,因此不再计算下一句预测任务的loss。
(masked_lm_loss, masked_lm_example_loss, masked_lm_log_probs) = get_masked_lm_output(
bert_config, model.get_sequence_output(), model.get_embedding_table(),
masked_lm_positions, masked_lm_ids, masked_lm_weights)
total_loss = masked_lm_loss
为了适配句子的长度,以及减小模型的训练时间,我们采取了BERT-mini模型,详细配置如下。
{
"hidden_size": 256,
"hidden_act": "gelu",
"initializer_range": 0.02,
"vocab_size": 5981,
"hidden_dropout_prob": 0.1,
"num_attention_heads": 4,
"type_vocab_size": 2,
"max_position_embeddings": 256,
"num_hidden_layers": 4,
"intermediate_size": 1024,
"attention_probs_dropout_prob": 0.1
}
由于我们的整体框架使用Pytorch,因此需要将最后一个检查点转换成Pytorch的权重。
def convert_tf_checkpoint_to_pytorch(tf_checkpoint_path, bert_config_file, pytorch_dump_path):
# Initialise PyTorch model
config = BertConfig.from_json_file(bert_config_file)
print("Building PyTorch model from configuration: {}".format(str(config)))
model = BertForPreTraining(config)
# Load weights from tf checkpoint
load_tf_weights_in_bert(model, config, tf_checkpoint_path)
# Save pytorch-model
print("Save PyTorch model to {}".format(pytorch_dump_path))
torch.save(model.state_dict(), pytorch_dump_path)
预训练消耗的资源较大,硬件条件不允许的情况下建议直接下载开源的模型
Bert Finetune
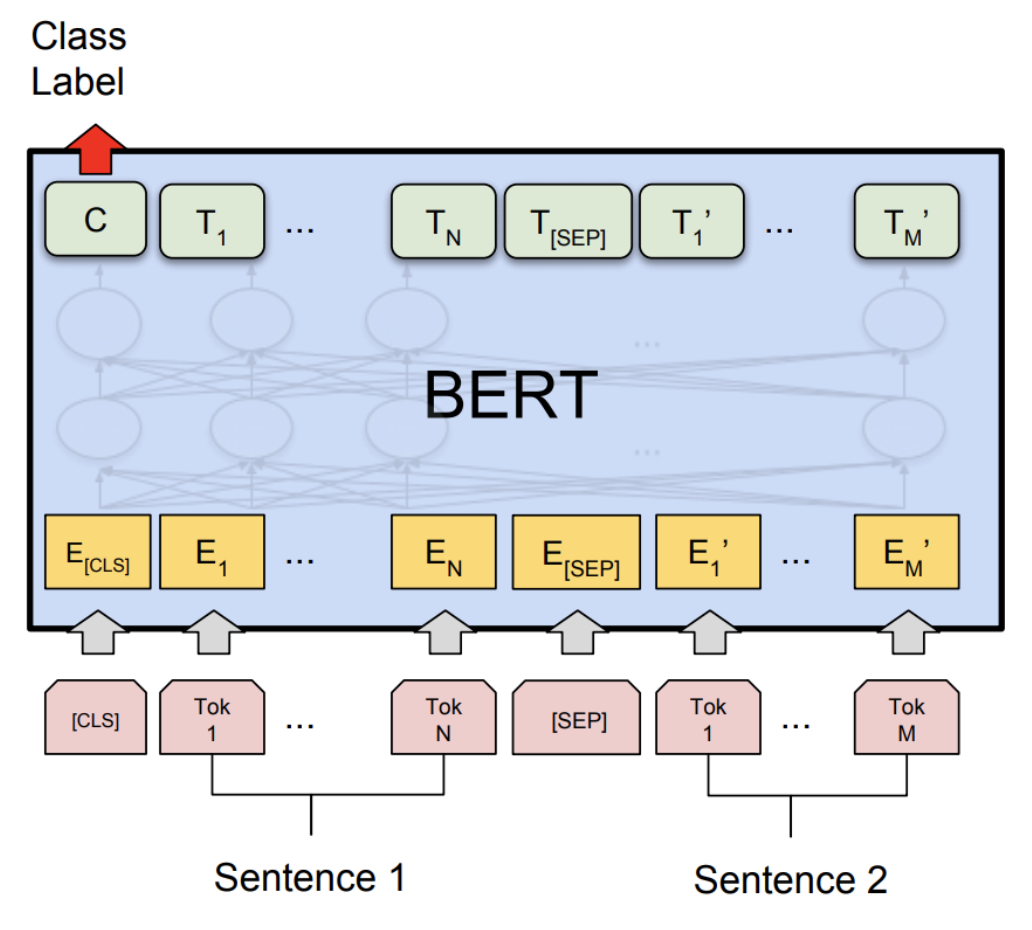
微调将最后一层的第一个token即[CLS]的隐藏向量作为句子的表示,然后输入到softmax层进行分类。
sequence_output, pooled_output =
self.bert(input_ids=input_ids, token_type_ids=token_type_ids)
if self.pooled:
reps = pooled_output
else:
reps = sequence_output[:, 0, :] # sen_num x 256
if self.training:
reps = self.dropout(reps)
本章小结
本章介绍了Bert的原理和使用,具体包括pretrain和finetune两部分。
本章作业
- 完成Bert Pretrain和Finetune的过程
- 阅读Bert官方文档,找到相关参数进行调参