参考程序:
1 import tensorflow as tf 2 import os 3 import numpy as np 4 import re 5 from PIL import Image 6 import matplotlib.pyplot as plt 7 8 class NodeLookup(object): 9 def __init__(self): 10 label_lookup_path = 'inception_model/imagenet_2012_challenge_label_map_proto.pbtxt' 11 uid_lookup_path = 'inception_model/imagenet_synset_to_human_label_map.txt' 12 self.node_lookup = self.load(label_lookup_path, uid_lookup_path) 13 14 def load(self, label_lookup_path, uid_lookup_path): 15 # 加载分类字符串n********对应分类名称的文件 16 proto_as_ascii_lines = tf.gfile.GFile(uid_lookup_path).readlines() 17 uid_to_human = {} 18 #一行一行读取数据 19 for line in proto_as_ascii_lines : 20 #去掉换行符 21 line=line.strip(' ') 22 #按照' '分割 23 parsed_items = line.split(' ') 24 #获取分类编号 25 uid = parsed_items[0] 26 #获取分类名称 27 human_string = parsed_items[1] 28 #保存编号字符串n********与分类名称映射关系 29 uid_to_human[uid] = human_string 30 31 # 加载分类字符串n********对应分类编号1-1000的文件 32 proto_as_ascii = tf.gfile.GFile(label_lookup_path).readlines() 33 node_id_to_uid = {} 34 for line in proto_as_ascii: 35 if line.startswith(' target_class:'): 36 #获取分类编号1-1000 37 target_class = int(line.split(': ')[1]) 38 if line.startswith(' target_class_string:'): 39 #获取编号字符串n******** 40 target_class_string = line.split(': ')[1] 41 #保存分类编号1-1000与编号字符串n********映射关系 42 node_id_to_uid[target_class] = target_class_string[1:-2] #要将两侧的双引号去掉 43 44 #建立分类编号1-1000对应分类名称的映射关系 45 node_id_to_name = {} 46 for key, val in node_id_to_uid.items(): 47 #获取分类名称 48 name = uid_to_human[val] 49 #建立分类编号1-1000到分类名称的映射关系 50 node_id_to_name[key] = name 51 return node_id_to_name 52 53 #传入分类编号1-1000返回分类名称 54 def id_to_string(self, node_id): 55 if node_id not in self.node_lookup: 56 return '' 57 return self.node_lookup[node_id] 58 59 60 #创建一个图来存放google训练好的模型 61 with tf.gfile.FastGFile('inception_model/classify_image_graph_def.pb', 'rb') as f: 62 graph_def = tf.GraphDef() 63 graph_def.ParseFromString(f.read()) 64 tf.import_graph_def(graph_def, name='') 65 66 67 with tf.Session() as sess: 68 softmax_tensor = sess.graph.get_tensor_by_name('softmax:0') 69 #遍历目录 70 for root,dirs,files in os.walk('images/'): 71 for file in files: 72 #载入图片 73 image_data = tf.gfile.FastGFile(os.path.join(root,file), 'rb').read() 74 predictions = sess.run(softmax_tensor,{'DecodeJpeg/contents:0': image_data})#图片格式是jpg格式 75 predictions = np.squeeze(predictions)#把结果转为1维数据 76 77 #打印图片路径及名称 78 image_path = os.path.join(root,file) 79 print(image_path) 80 #显示图片 81 img=Image.open(image_path) 82 plt.imshow(img) 83 plt.axis('off') 84 plt.show() 85 86 #排序 87 top_k = predictions.argsort()[-5:][::-1] 88 node_lookup = NodeLookup() 89 for node_id in top_k: 90 #获取分类名称 91 human_string = node_lookup.id_to_string(node_id) 92 #获取该分类的置信度 93 score = predictions[node_id] 94 print('%s (score = %.5f)' % (human_string, score)) 95 print()
在inception_model中有这2个文件:

分别长这样:
分类共有1000种结果以及所对应得字符串:
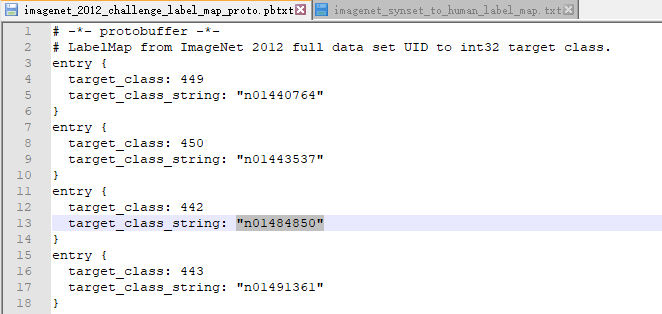
上述字符串及所对应的描述:

程序首先读入这2个文件:
proto_as_ascii_lines = tf.gfile.GFile(uid_lookup_path).readlines() uid_to_human = {} #一行一行读取数据 for line in proto_as_ascii_lines : #去掉换行符 line=line.strip(' ') #按照' '分割 parsed_items = line.split(' ') #获取分类编号 uid = parsed_items[0] #获取分类名称 human_string = parsed_items[1] #保存编号字符串n********与分类名称映射关系 uid_to_human[uid] = human_string
从 uid_lookup_path 中读取的结果存放在 proto_as_ascii_lines中,创建了一个空字典 uid_to_human 用来存储键值对,一行一行的读取数据,并将换行符去掉,以Tab键作为分割,

parsed_items[0]代表分类字符串n********(Tab键之前的内容),parsed_items[1]对应分类的名称(Tab键之后的内容),作为键值对存入字典。
# 加载分类字符串n********对应分类编号1-1000的文件 proto_as_ascii = tf.gfile.GFile(label_lookup_path).readlines() node_id_to_uid = {} for line in proto_as_ascii: if line.startswith(' target_class:'): #获取分类编号1-1000 target_class = int(line.split(': ')[1]) if line.startswith(' target_class_string:'): #获取编号字符串n******** target_class_string = line.split(': ')[1] #保存分类编号1-1000与编号字符串n********映射关系 node_id_to_uid[target_class] = target_class_string[1:-2]
程序同理,以: 分割,获取分类编号以及编号字符串n********,作为键值对存入字典,target_class_string[1:-2]是去掉字符串中的2个双引号: