1.map reduce 计算模型
介绍:https://blog.csdn.net/v_july_v/article/details/6637014
关键流程图示意:
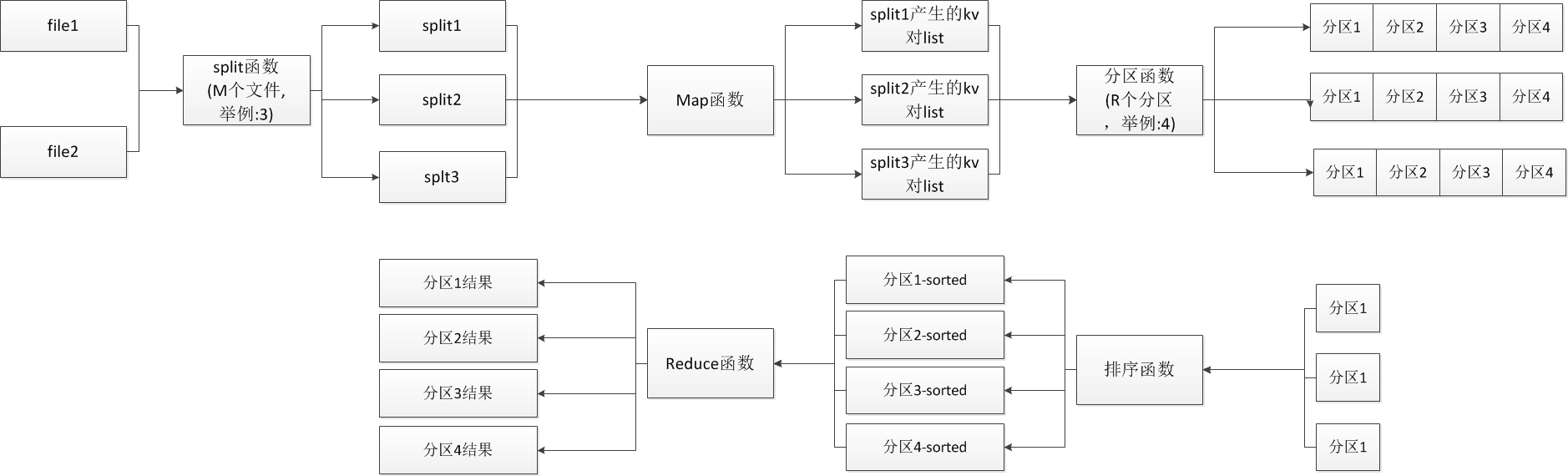
2.shuffle过程
介绍:https://www.zhihu.com/question/27593027
简单流程图:
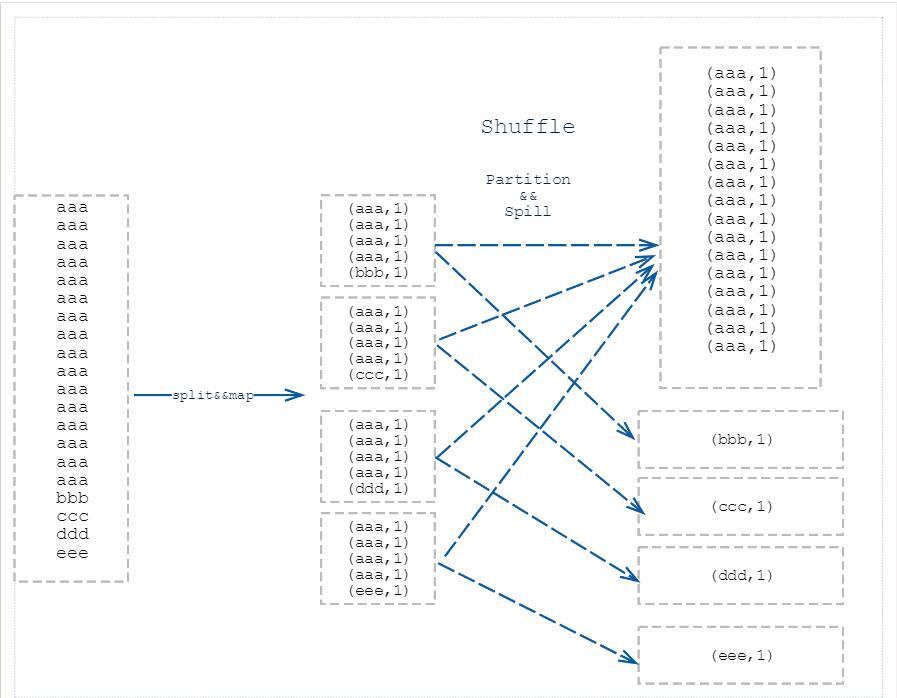
2.spark使用感想
spark 用yarn安装参考:
https://blog.csdn.net/u010638969/article/details/51283216
spark编程感想--理解spark的RDD编程
快速的实现spark应用,可以从数据流入手,首先写一下输入和预期输出的数据格式,根据
算法一步一步推导从输入到输出的过程,上手是很快的,但是要理解分布式计算模型的精髓需要时间去沉淀。
spark编程感想--如何学习分布式计算模型
分布式计算模型和普通开发的本质区别
1.控制粒度不一样,spark是借用别人写好的框架,要自己尝试去以spark的视角来编写应用。
比如计算协同过滤中的相似度,如果是用2个item-id来根据自己的user_list动态的计算相似度,其实并不适合分布式计算
一是因为这样需要额外携带的冗余数据过多,二是计算过程慢。
用公式的角度出发,需要计算2个item-id对应user的交集和并集,交集可以用一个user生成的item-id pair,最后汇总获得。
并集可以用2个item-id对应的user数量之和 - 交集 算出。
2.不要以之前的经验先入为主,而是多想别的思路和方法,优雅的使用。
spark优化
理解spark应用的执行过程、DAG的构建和执行、使用print RDD.toDebugString()(python)来帮助验证。
优化关键点2个
1.减少无用步骤
比如减少reducebykey来达到减少stage的目的。
使用cache来达到减少RDD计算的目的。
2.调整参数来适配spark的最优处理
根据数据大小和分区数目来适配spark的最优处理方式。
Spark对比Flink
https://www.jianshu.com/p/e246e334d339
重要结论:
执行效率Flink比spark高,但是高不多
社区spark比flink要发展的好
3.YARN监控如何看

对应spark-submit命令如下
/usr/lib/spark/bin/spark-submit
--master yarn
--deploy-mode client
--name "dodng-xxx"
--queue default
--num-executors 6
--driver-memory 4g
--executor-memory 4g
--executor-cores 4
xxx.py `date +\%Y-\%m-\%d -d -39day` `date +\%Y-\%m-\%d -d -3day` `date +\%Y\%m\%d -d -0day`
1.可以根据node address 直接ssh登录上去看情况
ssh ng9a81a2a-core-instance-hz5sqddm-2.novalocal
猜测规律:
containers对应是3 + 2 + 2应该对应上么的1个driver和6个executer
1个executer配置占用4G内存,实际应该分配了12/2=6G内存,应该还有额外的内存要求。
2个executer和1个driver配置内存为4*3=12G内存,实际占用12G内存。
实战 + 优化经验:
1.不使用广播变量而用collect + global
item_freq = user_item.map(lambda x: (x[1][0], 1))
.reduceByKey(lambda x, y: x + y)
.collect()
global g_item_freq_d
2.coalesce减少写文件的并发量
3.使用yield+.repartition 增加并行度,结果提升了40倍以上.