一、scrapy原理
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
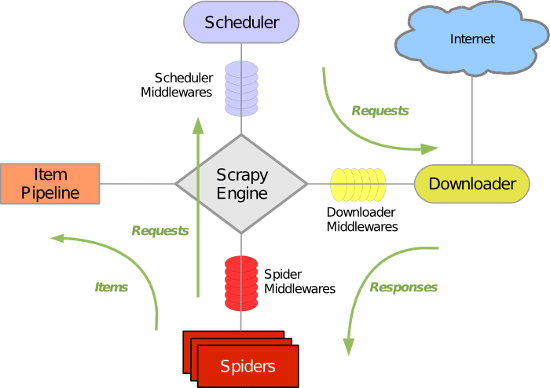
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
二、自定义scrapy框架
所用到的三个对象:
getpage:内封装socket对象,帮下载url的html页面,可自动回调
defer:内包装socket对象,不调用,所以不会自己回调,需手动终止,用于整个爬虫的任务终止
reactor:封装io多路复用,开启循环
通过DeferredList控制所有爬虫任务,结束时stop终止reactor的监听
运行流程大概如下:
1.crawl将spider中的start_requests中返回的的起始url生成器转化为迭代器,将请求添加到调度器。
2.通过reactor调用_next_request方法,即从调度器取出request对象并发送请求
3.页面下载完成,回调get_response_callback,调用用户spider中定义的parse方法,如果parse有yield request对象,将新请求添加到调度器。
如未达到最大并发数,可以再去调度器中获取Request。
4.当调度器的request对象没有了,即是爬虫任务结束,此时可关闭Deferred和reactor。
代码如下:
from twisted.internet import defer
from twisted.internet import reactor
from twisted.web.client import getPage
class Request(object):
def __init__(self, url, callback):
self.url = url
self.callback = callback
class HttpResponse(object):
def __init__(self,content,request):
self.content = content
self.request = request
self.url = request.url
self.text = str(content,encoding='utf-8')
class ChoutiSpider(object):
name = "chouti"
def start_requests(self):
start_urls = ['http://dig.chouti.com']
for url in start_urls:
yield Request(url, callback=self.parse)
def parse(self, response):
# yield Request("http://cn.bing.com",callback=self.parse)
print(response)
import queue
Q = queue.Queue()
class Engine(object):
def __init__(self):
self._close = None
self.max = 5
self.crawling = []
def get_response_callback(self,content,request):
self.crawling.remove(request)
rep = HttpResponse(content, request)
result = request.callback(rep) #调用parse方法 如果parse中有yield 则result是一个生成器
import types
if isinstance(result, types.GeneratorType):
for req in result:
Q.put(req)
def _next_request(self):
#取request对象,并发送请求
if Q.qsize() == 0 and len(self.crawling) == 0:
self._close.callback(None)
return
if len(self.crawling) >= self.max:
return
while len(self.crawling) < self.max:
try:
req = Q.get(block=False)
self.crawling.append(req)
d = getPage(req.url.encode("utf-8"))
# 页面下载完成,get_response_callback,调用用户spider中定义的parse方法,并且将新请求添加到调度器
d.addCallback(self.get_response_callback, req)
# 未达到最大并发数,可以再去调度器中获取Request
d.addCallback(lambda _: reactor.callLater(0, self._next_request))
except Exception as e:
return
@defer.inlineCallbacks
def crawl(self, spider):
start_requests = iter(spider.start_requests())
#将请求添加到调度器
while True:
try:
request = next(start_requests)
Q.put(request)
except StopIteration as e:
break
# 去调度器中取request,并发送请求
# self._next_request()
reactor.callLater(0, self._next_request)
self._close = defer.Deferred()
yield self._close
spider = ChoutiSpider()
_active = set()
engine = Engine()
d = engine.crawl(spider)
_active.add(d)
dd = defer.DeferredList(_active)
dd.addBoth(lambda a:reactor.stop())
reactor.run()