关于Zookeeper的介绍可以看这篇文章:Zookeeper学习笔记
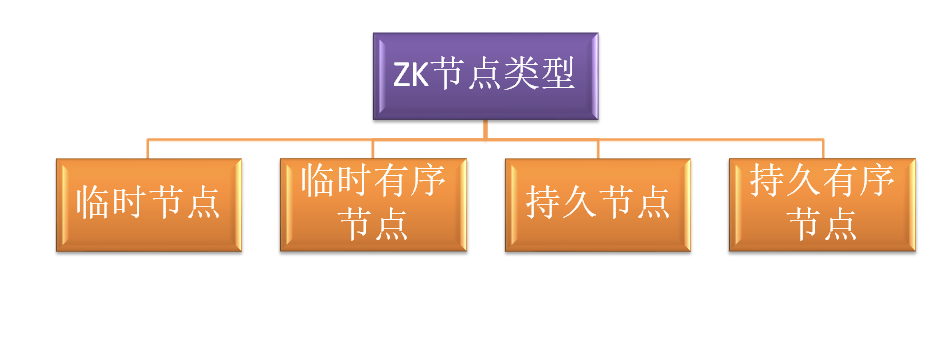
ZNode节点种类
-
临时节点 - 客户端与zookeeper断开连接后,该节点会自动删除
-
临时有序节点 - 客户端与zookeeper断开连接后,该节点会自动删除,但是这些节点都是有序排列的。
-
持久节点 - 客户端与zookeeper断开连接后,该节点依然存在
-
持久节点 - 客户端与zookeeper断开连接后,该节点依然存在,但是这些节点都是有序排列的。
错误的实现分布式锁方式
锁原理
多个客户端同时去创建同一个临时节点,哪个客户端第一个创建成功,就成功的获取锁,其他客户端获取失败。
获取锁的流程
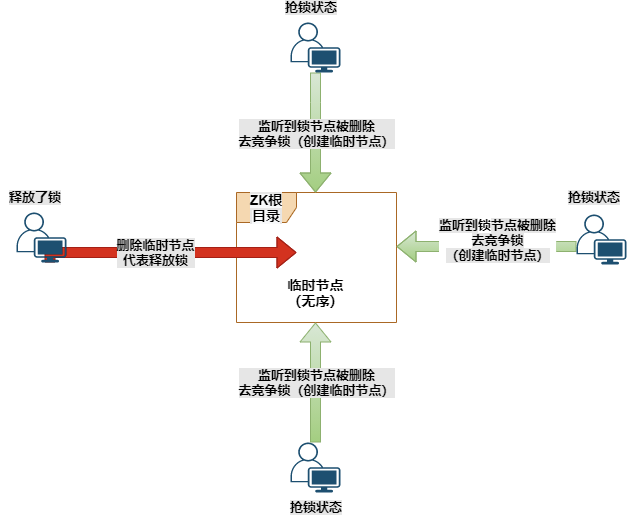
这里我们使用的是临时节点。
-
四个客户端同时创建一个临时节点。
-
谁第一个创建成功临时节点,就代表持有了这个锁(这里临时节点就代表锁)。
-
其他红色的客户端判断已经有人创建成功了,就开始监听这个临时节点的变化。

释放锁的流程
-
红色线的客户端执行任务完毕,与zookeeper断开了连接。
-
这时候临时节点会自动被删除掉,因为他是临时的。
-
其他绿色线的客户端watch监听到临时节点删除了,就会一拥而上去创建临时节点(也就是创建锁)
存在的问题分析
当临时节点被删除的时候,其余3个客户端一拥而上抢着创建节点。3个节点比较少,性能上看不出什么问题。
那如果是一千个客户端在监听节点呢?一旦节点被删除了,会唤醒一千个客户端,一千个客户端同时来创建节点。但是只有一个客户端能创建成功,却要让一千个客户端来竞争。对zookeeper的压力会很大,同时浪费这些客户端的线程资源,其中有999个客户端是白跑一趟的。
这就叫做惊群现象,也叫羊群现象。
一个节点释放删除了,却要惊动一千个客户端,这种做法太傻了吧。
正确的实现分布式锁方式
这里用的是顺序临时节点。
锁原理
多个客户端来竞争锁,各自创建自己的节点,按照顺序创建,谁排在第一个,谁就成功的获取了锁。
就像排队买东西一样,谁排在第一个,谁就先买。
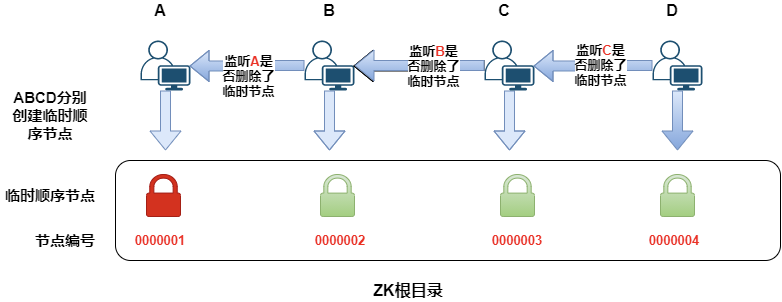
创建锁的过程
-
A、B、C、D 四个客户端来抢锁
-
A先来了,他创建了000001的临时顺序节点,他发现自己是最小的节点,那么就成功的获取到了锁
-
然后B来获取锁,他按照顺序创建了000001的临时顺序节点,发现前面有一个比他小的节点,那么就获取锁失败。他开始监听A客户端,看他什么时候能释放锁
-
同理C和D
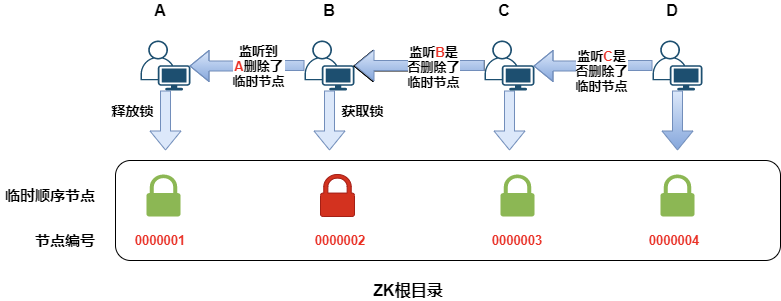
释放锁的过程
-
A客户端执行完任务后,断开了和zookeeper的会话,这时候临时顺序节点自动删除了,也就释放了锁
-
B客户端一直在虎视眈眈的watch监听着A,发现他释放了锁,立马就判断自己是不是最小的节点,如果是就获取锁成功
-
C监听着B,D监听着C
合理性分析
A释放锁会唤醒B,B获取到锁,对C和D是没有影响的,因为B的节点并没有发生变化。
同时B释放锁,唤醒C,C获取锁,对D是没有影响的,因为C的节点没有变化。
同理D。。。。
释放锁的操作,只会唤醒下一个客户端,不会唤醒所有的客户端。所以这种方案不存在惊群现象。
ps:创建临时节点 = 创建锁,删除临时节点 = 释放锁。
代码测试
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>5.1.0</version> </dependency> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>5.1.0</version> </dependency>
@Slf4j public class CuratorTest { private static final String ZK_IP_LIST = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183"; private static final String ZK_LOCK_PATH = "/demo/distributedLockTest"; private static CuratorFramework curatorClient = null; /** * 初始化zk连接 */ @BeforeAll public static void init() { //创建重试策略 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); curatorClient = CuratorFrameworkFactory.newClient(ZK_IP_LIST, retryPolicy); curatorClient.start(); } /** * 分布式锁测试 */ @Test public void distributedLockTest() { log.info("===distributedLockTest====start==============="); for (int i = 0; i < 10; i++) { new Thread(() -> { tryLockTest(); }).start(); } try { Thread.sleep(30000); } catch (InterruptedException e) { e.printStackTrace(); } log.info("===distributedLockTest====end==============="); } private void tryLockTest() { String threadName = Thread.currentThread().getName(); log.info("===Thread=={}===start===", threadName); InterProcessMutex lock = new InterProcessMutex(curatorClient, ZK_LOCK_PATH); // 尝试加锁,最多等待10秒,上锁以后30秒自动解锁 boolean lockFlag = false; try { // 尝试去获取锁,10秒没获取到锁,则返回false lockFlag = lock.acquire(10, TimeUnit.SECONDS); if (!lockFlag) { log.info("===Thread=={}==lockFlag={}==没有获取到锁,退出===", threadName, lockFlag); return; } log.info("===Thread=={}============getLock===", threadName); // 模拟业务逻辑 Thread.sleep(2000); } catch (Exception e) { log.error("执行异常,e:{}", ExceptionUtils.getStackTrace(e)); } finally { log.info("===Thread=={}==========isOwnedByCurrentThread={}", threadName, lock.isOwnedByCurrentThread()); // 当前线程是否持有所的判断 if (lock.isOwnedByCurrentThread()) { try { lock.release(); } catch (Exception e) { log.info("===Thread=={}========锁释放异常===e:{}", threadName, ExceptionUtils.getStackTrace(e)); } } } log.info("===Thread=={}==lockFlag={}=end===", threadName, lockFlag); } }
测试结果:

同时观察/demo/distributedLockTest节点下出现了10个临时顺序节点:
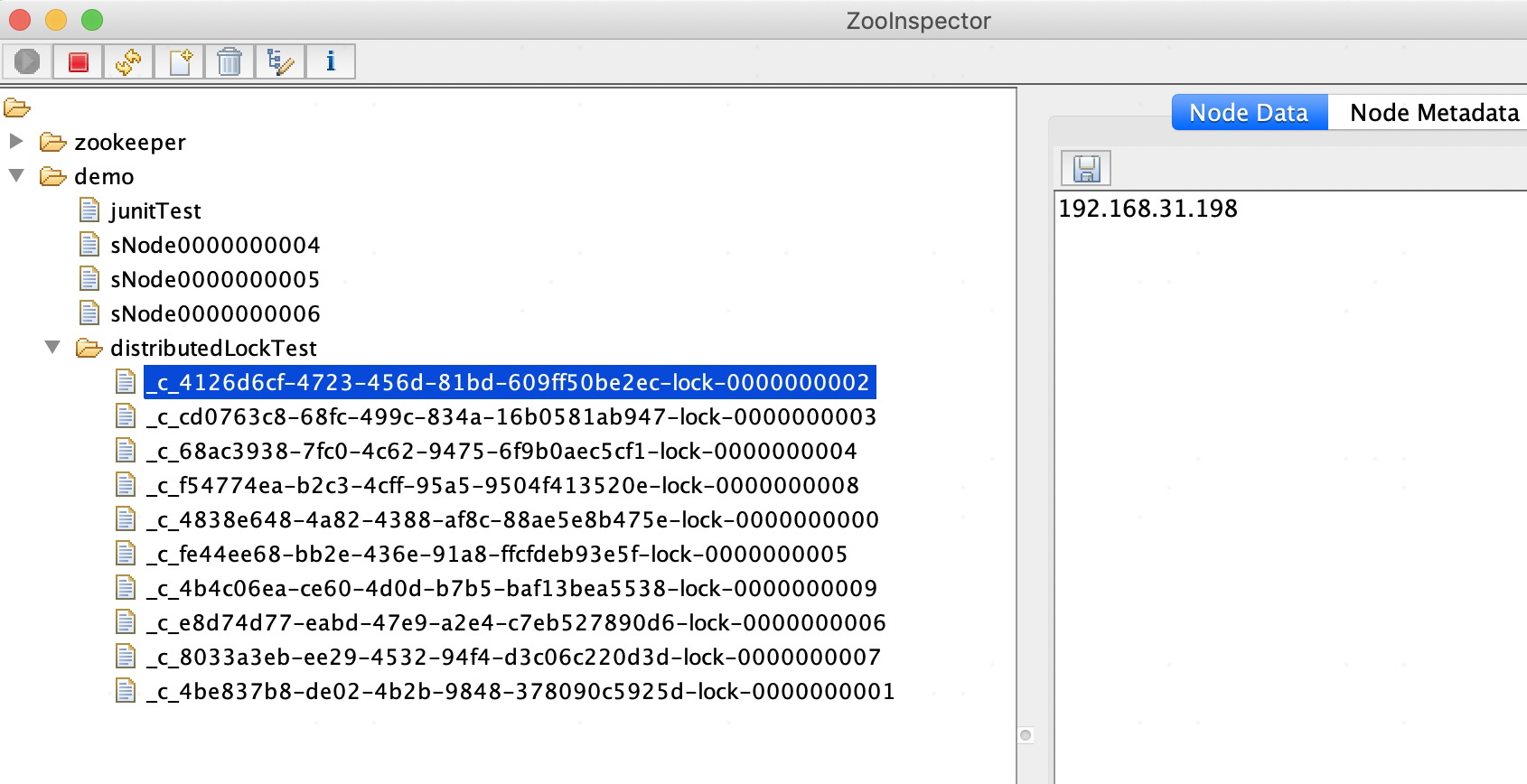
程序结束后,我们在刷新zookeeper客户端,发现/demo/distributedLockTest目录下的临时顺序节点已经被自动删除了。
总结
为什么不采用持久节点呢?
因为持久节点必须要客户端手动删除,否则他会一直存在zookeeper中。如果我们的客户端获取到了锁,还没释放锁就突然宕机了,那么这个锁会一直存在不被释放。导致其他客户端无法获取锁。
zookeeper实现的锁功能是比较健全的,但是性能上稍微差一些。比如zookeeper要维护集群自身信息的一致性,频繁创建和删除节点等原因。
如果仅仅是为了实现分布式锁而维护一套zookeeper集群,有点浪费了。如果公司本来就有zookeeper集群,同时并发不是非常大的情况下,可以考虑zookeeper实现分布式锁。
Redis在分布式锁方面的性能要高于zookeeper。但是reis分布式锁存在节点宕机的问题,可能导致重复获取锁。
Redission分布式锁可以见:Redisson分布式锁以及其底层原理
参考: