在上篇讲解完常用的RDD算子的具体使用后,我们本节来理解RDD的特性,包括三个方面:
1、RDD 的分区和Shuffle过程
2、RDD 缓存
3、RDD 的 CheckPoint
RDD的Shuffle和分区
分区的作用
(1)RDD经常需要通过读取外部系统的数据来创建,外部存储系统往往是支持分片,RDD需要支持分区,来和外部系统的分片一 一对应
(2)RDD的分区是一个并行计算的实现手段
分区和Shuffle的关系
分区的主要作用是用来实现并行计算,本质上和Shuffle没什么关系,但是往往在进行数据处理的时候,例如reduceByKey 或 groupByKey 等聚合操作,需要把 Key 相同的 Value 拉取到一起进行计算,这个时候因为这些 Key 相同的 Value 可能会坐落于不同的分区,于是理解分区才能理解Shuffle的根本原理。
Spark中Shuffle操作的特点
- 只有Key-Value 型的RDD才会有Shuffle操作,例如 RDD[ (K,V) ],但是有一个特例,就是 repartition 算子可以对任何数据类型进行 Shuffle。
- 早期版本Spark的 Shuffle算法是 Hash base shuffle,后来改为Sort base shuffle,更适合大吞吐量的场景。
1、RDD的分区操作
我们在Spark的bin目录下,执行启动spark的代码:spark-shell --master local[6]

我们观察可得很多有用的信息:
- spark 自动为我们创建一个 web UI界面,端口号4040
- SparkContext对象可用,并表示为sc,所以可以直接使用。
当我们使用Action算子启动一个job进程时,我们可以在4040查看

最后一个实际就是分区数,可以看到与 master 指定的 local 数一致。
还可以通过命令 rdd.partitions.size查看分区数。
通过算子重分区
rdd.coalesce(numPartions, Shuffle) : 两个参数,第一个指定分区数,第二个是否 shuffle (默认为false)
若不指定第二个参数,则coalesce只能减少分区数,不能增加,第二个参数为 true 才可既增加又减少
rdd.repartition(),可增可减,其实该方法就是调用的 shuffle 参数为 true 的 coalesce 函数
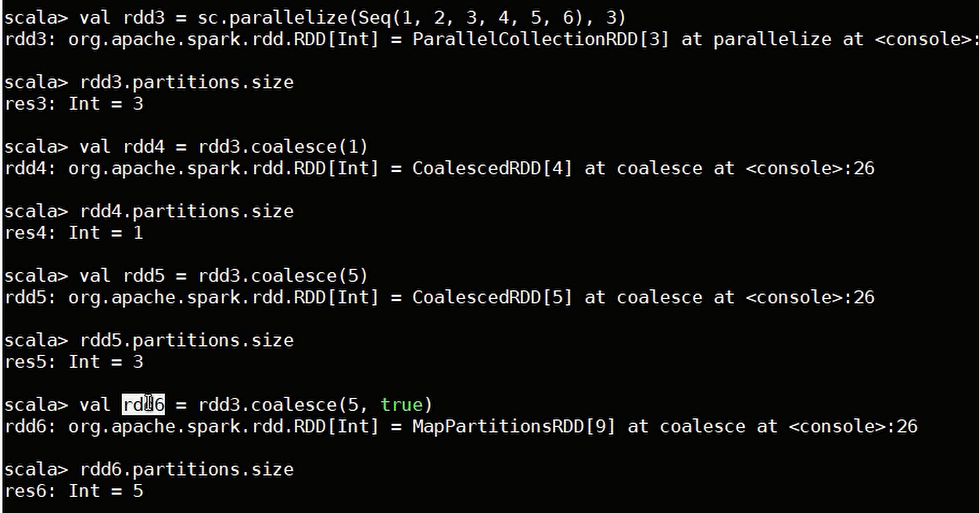
除了这两个指定分区数的函数,spark的 shuffle 函数对分区数也可以操作,主要是之前介绍的 KV 操作的函数等。
2、RDD 的 shuffle
shuffle 分为两端:mapper 和 reducer。
reducer一般通过拉去文件获取数据,mapper 的任务就是把发给 reducer 数据放到文件中。
我们以之前的一个 shuffle 算子 reduceByKey 为例,简单说明。
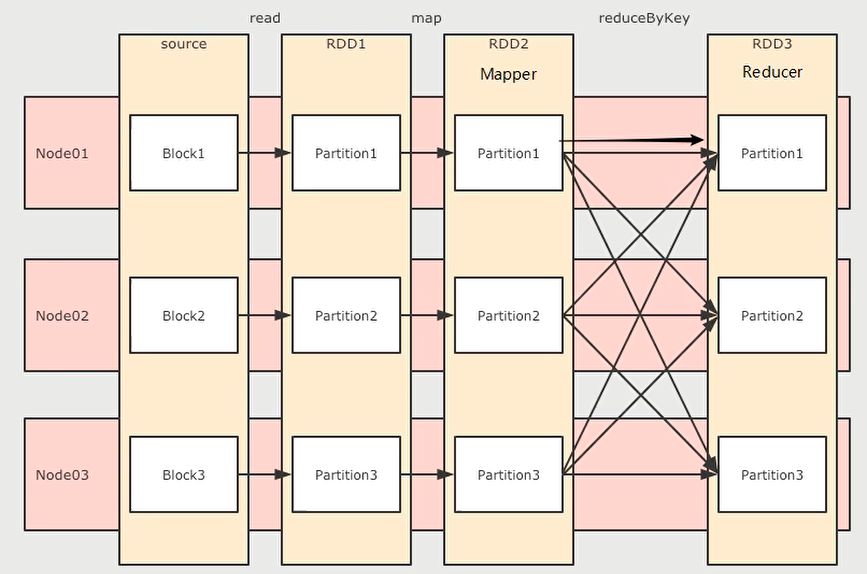
reduceByKey这个算子本质上就是先按照Key分组,后对每一组数据进行reduce,所面临的挑战就是 Key 相同的所有数据可能分布在不同的 Partition 分区中,甚至可能在不同的节点中,但是它们必须被共同计算。
为了让来自相同Key 的所有数据都在 reduceByKey 的同一个 reduce 中处理,需要执行一个all-to-all 的操作,需要在不同的节点(不同的分区)之间拷贝数据,必须跨分区聚集相同 Key 的所有数据,这个过程叫做Shuffle.
RDD 的缓存
先给出一段获取文件中 IP 访问次数最多 和 最少代码。
/** * 创建 sc * 读取文件、取出 IP,赋予初始频率 * 过滤清洗 * 统计 IP 出现的次数,得到IP出现次数最多、最少的IP */ @Test def prepare(): Unit ={ val conf = new SparkConf().setAppName("cache_prepare").setMaster("local[6]") val sc = new SparkContext(conf) val source = sc.textFile("dataset/access_log_sample.txt") val countRDD = source.map( item => (item.split(" ")(0), 1) ) val cleanRDD = countRDD.filter(item => StringUtils.isNotEmpty(item._1)) val aggRDD = cleanRDD.reduceByKey( (curr, agg) => curr + agg ) val lessIP = aggRDD.sortBy(item => item._2, ascending = true).first() val moreIP = aggRDD.sortBy( item => item._2, ascending = false).first() println((lessIP, moreIP)) }
其中reduceByKey就是shuffle操作,会在集群内进行数据拷贝,并且两次调用 aggRDD,读取两次,较消耗资源,使用缓存来解决该问题。
缓存的意义
减少指定算子的执行,缓存算子生成的结果。
缓存API
有两个API,一个是cache(),一个是persist()。
其中persist有两个重载方法,分别是不带参数的,和一个带表示缓存级别的参数的方法。
其实对于不带参数的persist(),和cache()一模一样,调用方法非常简单,在需要缓存的rdd后面跟上方法即可,例如
val aggRDD = aggRDD.cache()
val aggRDD = aggRDD.persist()
对于带参数的persist(newLevel StorageLevel),参数表示缓存级别。
缓存级别
其实如何缓存是一个技术活,有很多细节需要思考,如下
- 是否使用磁盘缓存?
- ·是否使用内存缓存?
- 是否使用堆外内存?
- 缓存前是否先序列化?
- 是否需要有副本?
缓存级别表
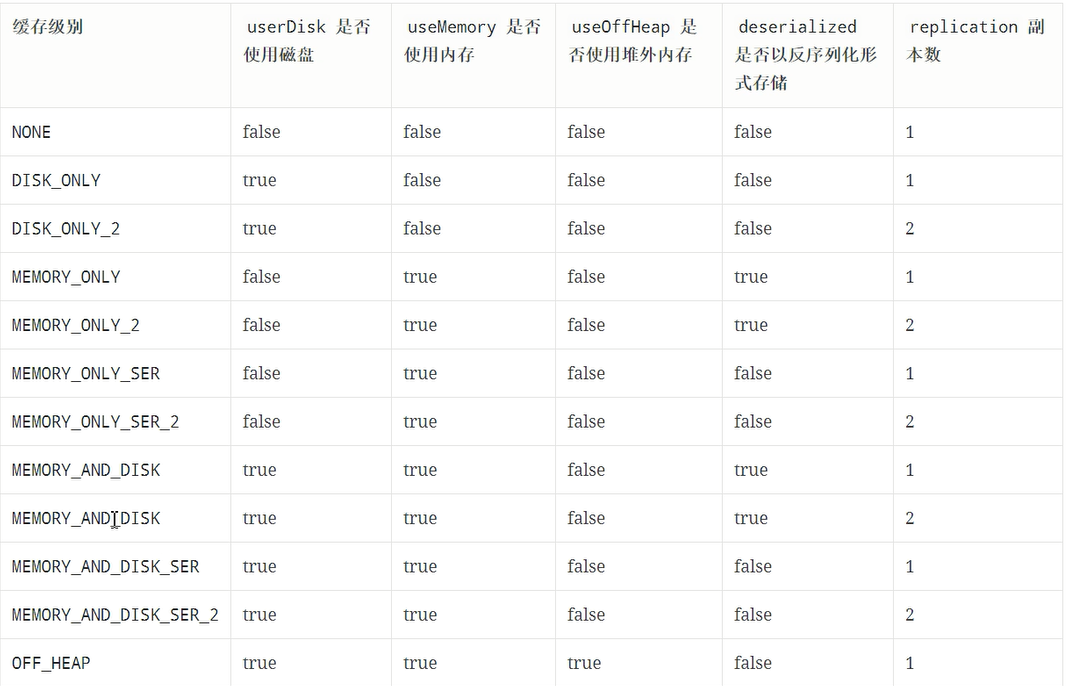
使用举例:
val aggRDD = aggRDD.persist(StorageLevel.MEMORY_ONLY)
如何选择分区级别?
Spark的存储级别的选择,核心问题是在memory内存使用率和CPU效率之间进行权衡。建议按下面的过程进行存储级别的选择:
如果您的RDD适合于默认存储级别(MEMORY_ONLY),leave them that way。这是CPU效率最高的选项,允许RDD 上的操作尽可能快地运行。
如果不是,试着使用MEMORY_ONLY_SER 和 selecting a fast serialization library 以使对象更加节省空间,但仍然能够快速访问。(Java和Scala)
不要溢出到磁盘,除非计算您的数据集的函数是昂贵的,或者它们过滤大量的数据。否则,重新计算分区可能与从磁盘读取分区一样快.
如果需要快速故障恢复,请使用复制的存储级别(例如,如果使用Spark来服务来自网络应用程序的请求)。All存储级别通过重新计算丢失的数据来提供完整的容错能力,但复制的数据可让您继续在RDD上运行任务,而无需等待重新计算一个丢失的分区.
RDD 的CheckPoint
Checkpoint 的作用
Checkpoint 的主要作用是斩断 RDD 的依赖链,并且将数据存储在可靠的存储引擎中,例如支持分布式存储和副本机制的 HDFS
checkpoint的方式
- 可靠的将数据存储在可靠的存储引擎中,例如 HDFS
- 本地的将数据存储在本地
什么是斩断依赖链?
斩断依赖链是一个非常重要的操作,接下来以HDFS的 NameNode 的原理来举例说明
HDFS的 NameNode 中主要职责就是维护两个文件,一个叫做 edits,另外一个叫做 fsimage 。edits中主要存放 EditLog,FsImage 保存了当前系统中所有目录和文件的信息。这个 FsImage其实就是一个Checkpoint 。
HDFS 的 NameNode 维护这两个文件的主要过程是:首先,会由 fsimage文件记录当前系统某个时间点的完整数据,自此之后的数据并不是时刻写入fsimage ,而是将操作记录存储在 edits 文件中。其次,在一定的触发条件下, edits 会将自身合并进入 fsimage。最后生成新的 fsimage 文件, edits重置,重新记录这次 fsimage 以后的操作日志。
如果不合并 edits 进入 fsimage 会怎样?会导致 edits 中记录的日志过长,容易出错。
所以当 Spark 的一个 Job 执行流程过长的时候,也需要这样的一个斩断依赖链的过程,使得接下来的计算轻装上阵。
CheckPoint 和 Cache 的区别
Cache 可以把 RDD 计算出来然后放在内存中,但是 RDD 的依赖链(相当于 NameNode 中的 Edits 日志)是不能丢掉的,因为这种缓存是不可靠的,如果出现了一些错误(例如 Executor 宕机),这个 RDD 的容错就只能通过回溯依赖链,重放计算出来。
但是 Checkpoint 把结果保存在 HDFS 这类存储中,就是可靠的了,所以可以斩断依赖,如果出错了,则通过复制HDFS中的文件来实现容错。
所以他们的区别主要在以下两点
- checkpoint 可以保存数据到 HDFS 这类可靠的存储上, Persist 和 Cache 只能保存在本地的磁盘和内存中。Checkpoint 可以斩断 RDD 的依赖链,而 Persist 和 Cache 不行
- 因为 CheckpointRDD没有向上的依赖链,所以程序结束后依然存在,不会被删除。而 Cache 和 Persist 会在程序结束后立刻被清除。
CheckPioint 的使用
使用方法简单,两行代码搞定。
// 设置 checkpoint的目录,也可以设置为 hdfs 上的目录 sc.setCheckpointDir("checkPoint") // checkpoint 的使用 rdd.checkpoint()
具体案例代码如下:
package rdd import org.apache.commons.lang3.StringUtils import org.apache.spark.{SparkConf, SparkContext} import org.junit.Test class CheckPointOp { val conf = new SparkConf().setAppName("cache_prepare").setMaster("local[6]") val sc = new SparkContext(conf) // 设置 checkpoint的目录,也可以设置为 hdfs 上的目录 sc.setCheckpointDir("checkPoint") @Test def prepare(): Unit ={ val source = sc.textFile("dataset/access_log_sample.txt") val countRDD = source.map( item => (item.split(" ")(0), 1) ) val cleanRDD = countRDD.filter(item => StringUtils.isNotEmpty(item._1)) val aggRDD = cleanRDD.reduceByKey( (curr, agg) => curr + agg ) // checkpoint 的使用,也可以理解为 checkpoint 为 action 操作 // 也就是说,如果调用 checkpoint,则会重新计算RDD,然后存储结果到本地或hdfs // 所以,应该在 checkpoint 之前,进行一次 cache aggRDD.cache() aggRDD.checkpoint() val lessIP = aggRDD.sortBy(item => item._2, ascending = true).first() val moreIP = aggRDD.sortBy( item => item._2, ascending = false).first() println((lessIP, moreIP)) } }