学习笔记
排序算法
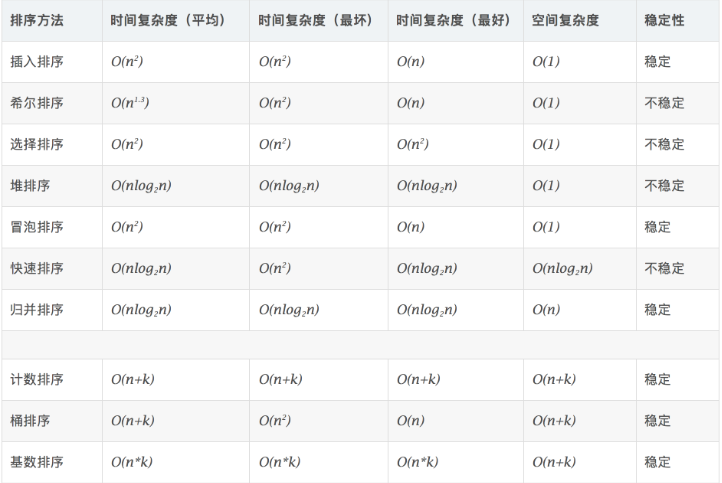
排序分为两类,比较类排序和非比较类排序,比较类排序通过比较来决定元素间的相对次序,其时间复杂度不能突破O(nlogn);非比较类排序可以突破基于比较排序的时间下界,缺点就是一般只能用于整型相关的数据类型,需要辅助的额外空间。
要求能够手写时间复杂度位O(nlogn)的排序算法:快速排序、归并排序、堆排序
1.冒泡排序
思想:相邻的两个数字进行比较,大的向下沉,最后一个元素是最大的。列表右边先有序。
时间复杂度$O(n^2)$,原地排序,稳定的
def bubble_sort(li:list):
for i in range(len(li)-1):
for j in range(i + 1, len(li)):
if li[i] > li[j]:
li[i], li[j] = li[j], li[i]
2.选择排序
思想:首先找到最小元素,放到排序序列的起始位置,然后再从剩余元素中继续寻找最小元素,放到已排序序列的末尾,以此类推,直到所有元素均排序完毕。列表左边先有序。
时间复杂度$O(n^2)$,原地排序,不稳定
def select_sort(nums: list):
for i in range(len(nums) - 1):
min_index = i
for j in range(i + 1, len(nums)):
if nums[j] < nums[i]:
min_index = j
nums[i], nums[min_index] = nums[min_index], nums[i]
3.插入排序
思想:构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。列表左边先有序。
时间复杂度$O(n^2)$,原地排序,稳定
def insert_sort(nums: list):
for i in range(len(nums)):
current = nums[i]
pre_index = i - 1
while pre_index >= 0 and nums[pre_index] > current:
nums[pre_index + 1] = nums[pre_index]
pre_index -= 1
nums[pre_index + 1] = current
4.希尔排序
思想:插入排序的改进版,又称缩小增量排序,将待排序的列表按下标的一定增量分组,每组分别进行直接插入排序,增量逐渐减小,直到为1,排序完成
时间复杂度$O(n^{1.5})$,原地排序,不稳定
def shell_sort(nums: list):
gap = len(nums) >> 1
while gap > 0:
for i in range(gap, len(nums)):
current = nums[i]
pre_index = i - gap
while pre_index >= 0 and nums[pre_index] > current:
nums[pre_index + gap] = nums[pre_index]
pre_index -= gap
nums[pre_index + gap] = current
gap >>= 1
5.快速排序
思想:递归,列表中取出第一个元素,作为标准,把比第一个元素小的都放在左侧,把比第一个元素大的都放在右侧,递归完成时就是排序结束的时候
时间复杂度$O(nlogn)$,空间复杂度$O(logn)$,不稳定
def quick_sort(li:list):
if li == []:
return []
first = li[0]
# 推导式实现
left = quick_sort([l for l in li[1:] if l < first])
right = quick_sort([r for r in li[1:] if r >= first])
return left + [first] + right
6.归并排序
思想:分治算法,拆分成子序列,使用归并排序,将排序好的子序列合并成一个最终的排序序列。关键在于怎么合并:设定两个指针,最初位置分别为两个已经排序序列的起始位置,比较两个指针所指向的元素,选择相对小的元素放到合并空间,并将该指针移到下一位置,直到某一指针超出序列尾,将另一序列所剩下的所有元素直接复制到合并序列尾。
时间复杂度$O(nlogn)$,空间复杂度O(n),不稳定
二路归并
def merge_sort(nums: list):
if len(nums) <= 1:
return nums
mid = len(nums) >> 1
left = merge_sort(nums[:mid]) # 拆分子问题
right = merge_sort(nums[mid:])
def merge(left, right): # 如何归并
res = []
l, r = 0, 0
while l < len(left) and r < len(right):
if left[l] <= right[r]:
res.append(left[l])
l += 1
else:
res.append(right[r])
r += 1
res += left[l:]
res += right[r:]
return res
return merge(left, right)
7.堆排序
思想:根节点最大,大顶堆,对应升序,根节点最小,小顶堆。
- 构建大根堆,完全二叉树结构,初始无序
- 最大堆调整,进行堆排序。将堆顶元素与最后一个元素交换,此时后面有序
时间复杂度$O(nlogn)$,原地排序,稳定
def heap_sort(nums: list):
def heapify(parent_index, length, nums):
temp = nums[parent_index] # 根节点的值
chile_index = 2 * parent_index + 1 # 左节点,再加一为右节点
while chile_index < length:
if chile_index + 1 < length and nums[chile_index + 1] > nums[chile_index]:
chile_index = chile_index + 1
if temp > nums[chile_index]:
break
nums[parent_index] = nums[chile_index] # 使得根节点最大
parent_index = chile_index
chile_index = 2 * parent_index + 1
nums[parent_index] = temp
for i in range((len(nums) - 2) >> 1, -1, -1):
heapify(i, len(nums), nums) # 1.建立大根堆
for j in range(len(nums) - 1, 0, -1):
nums[j], nums[0] = nums[0], nums[j]
heapify(0, j, nums) # 2.堆排序,为升序
if __name__ == '__main__':
nums = [89, 3, 3, 2, 5, 45, 33, 67] # [2, 3, 3, 5, 33, 45, 67, 89]
heap_sort(nums)
print(nums)