1. 本周学习总结
1.1 以你喜欢的方式(思维导图或其他)归纳总结多流与文件相关内容。

2. 书面作业
将Student对象(属性:int id, String name,int age,double grade)写入文件student.data、从文件读出显示。
1. 字符流与文本文件:使用 PrintWriter(写),BufferedReader(读)
1.1 生成的三个学生对象,使用PrintWriter的println方法写入student.txt,每行一个学生,学生的每个属性之间用|作为分隔。使用Scanner或者BufferedReader将student.txt的数据读出。(截图关键代码,出现学号)

运行结果:


1.2 生成文件大小多少?分析该文件大小

生成文件大小为51字节。
| 属性 | 字节数 |
|---|---|
| 总人数n+行末尾 | 1+2=3 |
| num | 1 |
| name | 4 |
| age | 2 |
| score | 4 |
| 分隔符(每行三个) | 3 |
| 行末尾 | 2 |
| 每行学生信息 | 1+4+2+4+3+2=16 |
| 总计 | 3+16*3=48 |
1.3 如果调用PrintWriter的println方法,但在后面不close。文件大小是多少?为什么?
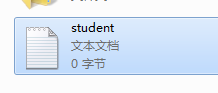
文件大小是0字节,因为数据是写到缓冲区上的,close()会自动调用flush()方法刷新此输出流并强制写出所有缓冲的输出字节,现在不close了,就会使缓冲区的数据没有被传送到指定文件,导致数据丢失;我们可以手动调用flush方法来强制写出缓冲区的字符。
- 参考:本题具体要求见流与文件实验任务书-题目1-2.1
- 参考代码:TextFileTest.java
2. 缓冲流
2.1 使用PrintWriter往文件里写入1千万行(随便什么内容都行),然后对比使用BufferedReader与使用Scanner从该文件中读取数据的速度(只读取,不输出),使用哪种方法快?请详细分析原因?提示:可以使用junit4对比运行时间

使用BufferedReader更快,因为BufferedReader是将数据先写到缓冲区,再写到硬盘,使用缓冲方式可以减少真正的底层I/O操作,效率就比Scanner更高。
2.2 将PrintWriter换成BufferedWriter,观察写入文件的速度是否有提升。记录两者的运行时间。试分析原因。

有提升,因为BufferedWriter也同样是使用了缓冲方式,减少对底层的I/O操作,提高了效率。
- 参考:本题具体要求见流与文件实验任务书-题目1-2.2到2.3
- 参考代码:BufferedReaderTest.java
- JUnit4常用注解
- JUnit4学习
3. 字符编码
3.1 现有EncodeTest.txt 文件,该文件使用UTF-8编码。使用FileReader与BufferedReader将EncodeTest.txt的文本读入并输出。是否有乱码?为什么会有乱码?如何解决?(截图关键代码,出现学号)


出现乱码,因为FileReader只能按系统默认的字符集(如GBK)来解码 ,但是EncodeTest.txt的文本是UTF-8编码的,将UTF-8编码的字符使用GBK编码来解析,就出现乱码了。
解决方案:


3.2 编写一个方法convertGBK2UTF8(String src, String dst),可以将以GBK编码的源文件src转换成以UTF8编码的目的文件dst。

- 参考:InputStreamReaderTest.java与教学PPT
4. 字节流、二进制文件:DataInputStream, DataOutputStream、ObjectInputStream
4.1 参考DataStream目录相关代码,尝试将三个学生对象的数据写入文件,然后从文件读出并显示。(截图关键代码,出现学号)



4.2 生成的文件有多大?分析该文件大小?将该文件大小和题目1生成的文件对比是大了还是小了,为什么?

生成的文件72字节。一个int占4字节,一个UTF编码的汉字占3个字节,一个double占8个字节,行末尾占2个字节,共三个学生,所以是72字节;题目1中都是以字符串的形式存储的,每个字符占一个字节,一个汉字占两个字节,所以文件大小较小。
| 属性 | 字节数 |
|---|---|
| num | 4 |
| name | 6 |
| age | 4 |
| score | 8 |
| 行末尾 | 2 |
| 每行学生信息 | 4+6+4+8+2=24 |
| 总计 | 24*3=72 |
4.3 使用wxMEdit的16进制模式(或者其他文本编辑器的16进制模式)打开student.data,分析数据在文件中是如何存储的。

| 十六进制 | |
|---|---|
| 0000 0001 | 1 |
| 0006 E5BC A0E4 B889 | 张三 |
| 0000 0013 | 19 |
| 4050 4000 0000 00 | 65.0 |
| 0000 0002 | 2 |
| 0006 E69D 8EE5 9B9B | 李四 |
| 0000 0013 | 19 |
| 4052 C000 0000 00 | 75.0 |
| 0000 0003 | 3 |
| 0006 E78E 8BE4 BA94 | 王五 |
| 0000 0014 | 20 |
| 4055 4000 0000 00 | 85.0 |
4.4 使用ObjectInputStream(读), ObjectOutputStream(写)读写学生。(截图关键代码,出现学号) //参考ObjectStreamTest目录

- 参考:本题具体要求见流与文件实验任务书-题目1-1
5. Scanner基本概念组装对象
编写public static List<Student> readStudents(String fileName)从fileName指定的文本文件中读取所有学生,并将其放入到一个List中。应该使用那些IO相关的类?说说你的选择理由。


使用BufferedReader使文件读取更高效;因为要读取UTF-8编码的文件,所以使用InputStreamReader防止乱码;使用FileInputStream从文件中读取。
- 实验文件:Students.txt
- 参考:TextFileTest目录下TextFileTest.java
6. 选做:RandomAccessFile
6.1 使用RandomAccessFile实现题目1.1。(截图关键代码,出现学号)


6.2 分析文件大小**

文件大小为72字节。
| 属性 | 字节数 |
|---|---|
| num | 4 |
| name | 6 |
| age | 4 |
| score | 8 |
| 行末尾 | 2 |
| 每行学生信息 | 4+6+4+8+2=24 |
| 总计 | 24*3=72 |
7. 文件操作
编写一个程序,可以根据指定目录和文件名,搜索该目录及子目录下的所有文件,如果没有找到指定文件名,则显示无匹配,否则将所有找到的文件名与文件夹名显示出来。
7.1 编写public static void findFile(String path,String filename)函数,以path指定的路径为根目录,在其目录与子目录下查找所有和filename相同的文件名,一旦找到就马上输出到控制台。(截图关键代码,出现学号)


7.2 加分点:使用队列、使用图形界面、使用Java NIO.2完成(任选1)

7.3 选做:实现删掉指定目录及其子目录下的所有空文件夹。


- 参考代码:FindDirectories.java
- 参考:本题具体要求见流与文件实验任务书-题目2
7.4 选做:将指定目录及子目录下的所有.java文件,转化成UTF-8编码格式,并测试。
- 参考资料:判断文件的编码格式
8. 正则表达式
8.1 如何判断一个给定的字符串是否是10进制数字格式?尝试编程进行验证。(截图关键代码,出现学号)


8.2 选做:修改HrefMatch.java,尝试匹配网页中的数字字符串、匹配网页中的图片字符串。
- 参考:本题具体要求见流与文件实验任务书-题目3
8.3 选做(较难):进一步改造上面的程序,获得图片的链接,如IMG src="images/mail1.gif",然后经过处理,生成该图片的实际链接地址http://cec.jmu.edu.com/images/mail1.gif。最后将生成的若干地址,放入一个队列。编写方法,可以依照该队列的所有图片地址,一次将图片下载下来。
3. 码云及PTA
3.1. 码云代码提交记录
在码云的项目中,依次选择“统计-Commits历史-设置时间段”, 然后搜索并截图

4.选做:课外阅读
4.1 尝试翻译Lesson: Basic I/O中的Summary
4.2 尝试完成Questions and Exercise
4.3 字符集与编码
4.4 Java正则表达式的语法与示例