今天主要说夏set集合,每天抽出一个小时总结下,生活会更加美好!
--< java.util >-- Set接口:
数据结构:数据的存储方式;
Set接口中的方法和Collection中方法一致的。
|--HashSet:
HashSet类直接实现了Set接口, 其底层其实是包装了一个HashMap去实现的。HashSet采用HashCode算法来存取集合中的元素,因此具有比较好的读取和查找性能。
底层数据结构是哈希表,线程是不同步的。无序,高效;HashSet是线程非安全的,元素值可以为NULL,但只能放入一个null
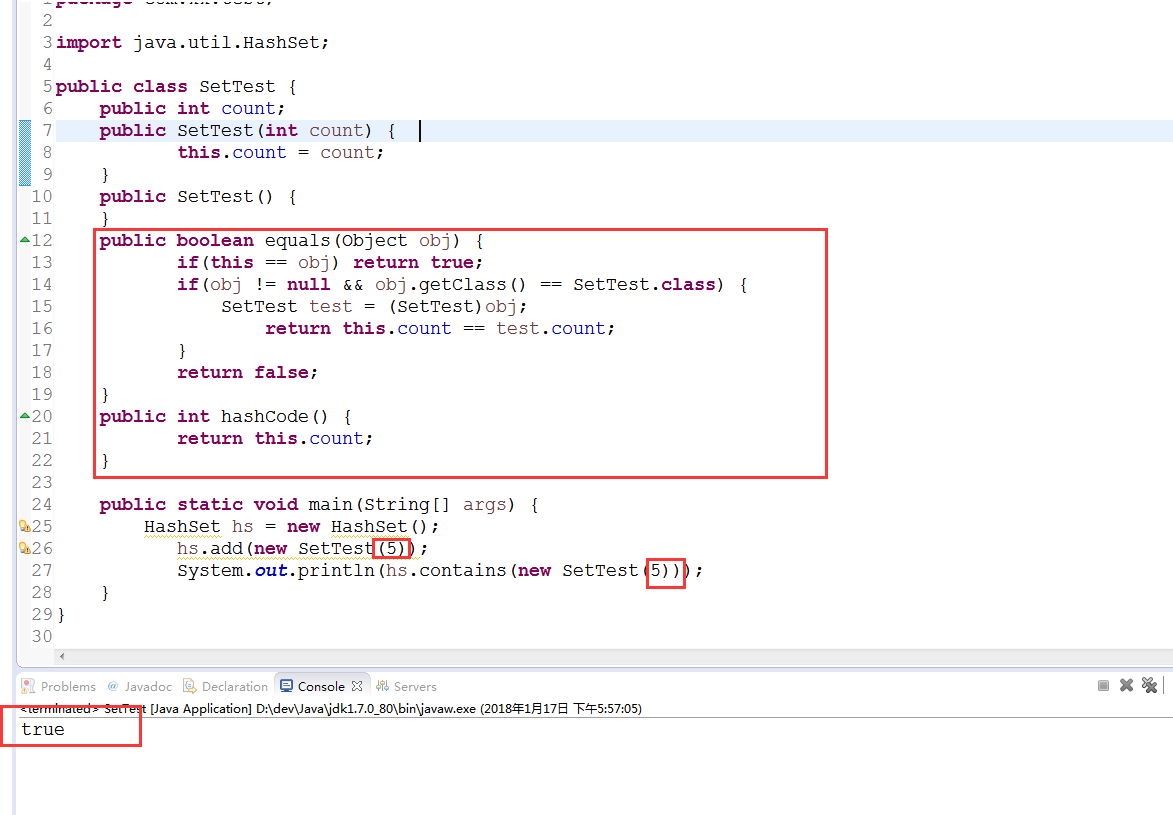
HashSet集合保证元素唯一性:通过元素的hashCode方法,和equals方法完成的。
HashSet需要同时通过equals和HashCode来判断两个元素是否相等,具体规则是,如果两个元素通过equals为true,并且两个元素的hashCode相等,则这两个元素相等(即重复)。
当元素的hashCode值相同时,才继续判断元素的equals是否为true。
如果为true,那么视为相同元素,不存。如果为false,那么存储。
如果hashCode值不同,那么不判断equals,从而提高对象比较的速度。
注掉HashCode方法
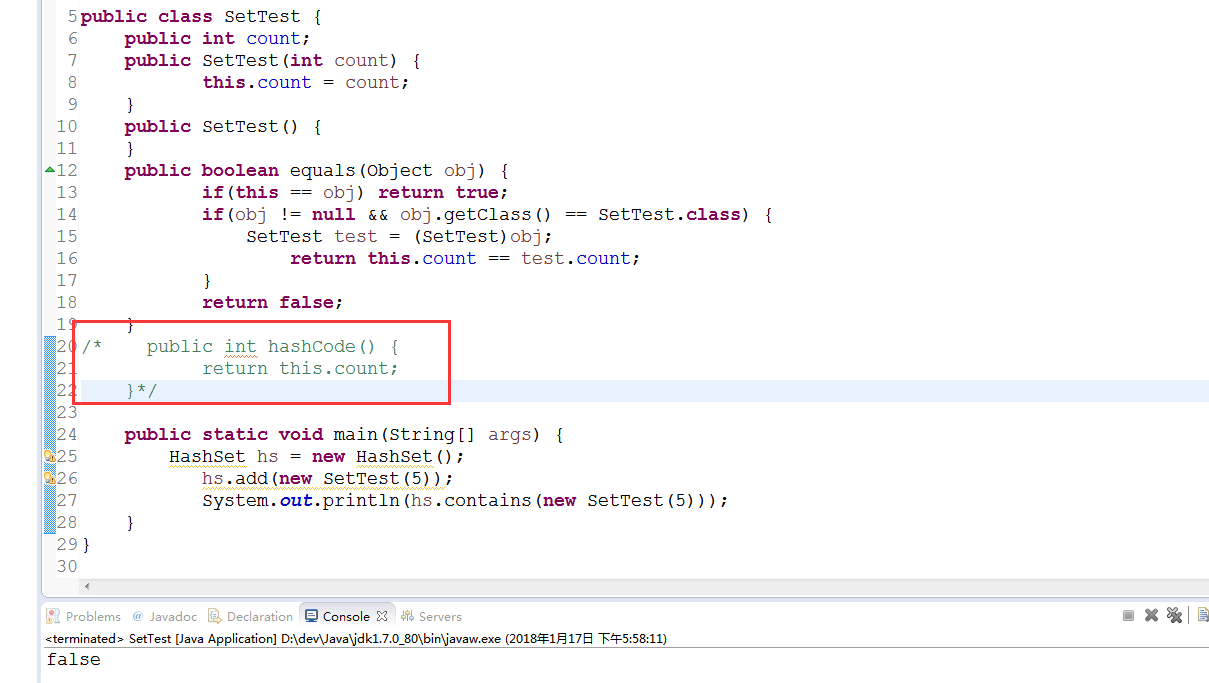
注掉equalse

|--LinkedHashSet:
有序,hashset的子类。
这个相对于HashSet来说有一个很大的不一样是LinkedHashSet是有序的。LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。
Set<String> set = new LinkedHashSet<String>(); for(int i= 0;i<6;i++){ set.add(i+""); } set.add("3"); //重复数据,不会写入 set.add(null); //可以写入空数据 Iterator<String> iter = set.iterator(); while(iter.hasNext()){ System.out.println(iter.next()); //输出是有序的 }
结果如下
0 1 2 3 4 5 null
|--TreeSet:
对Set集合中的元素的进行指定顺序的排序。不同步。TreeSet底层的数据结构就是二叉树。
1.不能写入空数据
2.写入的数据是有序的。
3.不写入重复数据
哈希表的原理:
1,对对象元素中的关键字(对象中的特有数据),进行哈希算法的运算,并得出一个具体的算法值,这个值 称为哈希值。
2,哈希值就是这个元素的位置。
3,如果哈希值出现冲突,再次判断这个关键字对应的对象是否相同。如果对象相同,就不存储,因为元素重复。如果对象不同,就存储,在原来对象的哈希值基础 +1顺延。
4,存储哈希值的结构,我们称为哈希表。
5,既然哈希表是根据哈希值存储的,为了提高效率,最好保证对象的关键字是唯一的。
这样可以尽量少的判断关键字对应的对象是否相同,提高了哈希表的操作效率。
对于ArrayList集合,判断元素是否存在,或者删元素底层依据都是equals方法。
对于HashSet集合,判断元素是否存在,或者删除元素,底层依据的是hashCode方法和equals方法。
TreeSet:
用于对Set集合进行元素的指定顺序排序,排序需要依据元素自身具备的比较性。
如果元素不具备比较性,在运行时会发生ClassCastException异常。
所以需要元素实现Comparable接口,强制让元素具备比较性,复写compareTo方法。
依据compareTo方法的返回值,确定元素在TreeSet数据结构中的位置。
TreeSet方法保证元素唯一性的方式:就是参考比较方法的结果是否为0,如果return 0,视为两个对象重复,不存。
注意:在进行比较时,如果判断元素不唯一,比如,同姓名,同年龄,才视为同一个人。
在判断时,需要分主要条件和次要条件,当主要条件相同时,再判断次要条件,按照次要条件排序。
TreeSet集合排序有两种方式,Comparable和Comparator区别:
1:让元素自身具备比较性,需要元素对象实现Comparable接口,覆盖compareTo方法。
2:让集合自身具备比较性,需要定义一个实现了Comparator接口的比较器,并覆盖compare方法,并将该类对象作为实际参数传递给TreeSet集合的构造函数。
第二种方式较为灵活。
遍历Set
1.迭代遍历: Set<String> set = new HashSet<String>(); Iterator<String> it = set.iterator(); while (it.hasNext()) { String str = it.next(); System.out.println(str); } 2.for循环遍历: for (String str : set) { System.out.println(str); }