这节就开始讲述Hadoop的安装吧。在这之前先配置下SSH免密码登录,为什么需要配置这个呢?大家都知道Hadoop集群中可能有几十台机器甚至是上千台机器,而每次启动Hadoop都需要输入密码才能够登录到每台机器的DataNode上的,所以为了避免后期繁琐的操作,一般都会配置SSH免密码登录。
注:笔者使用的远程连接工具是XShell,很好用的一款远程连接工具,推荐大家使用,还可以安装一下xftp文件传输工具,方便于将自己电脑上的软件拷贝到虚拟机中,xftp和Xshell是可以配套使用的。
配置SSH免密码登录,首先需要有SSH的支持,当然,在第一篇中的安装CentOS系统中是会自己安装上SSH的,为了节省时间这里就不说了。不清楚是否有没有安装SSH的可以使用ssh -version进行验证,如果出现与下图相似的信息就代表已经安装了SSH了.
下面开始看看如何配置SSH免密码登录吧。
首先输入ssh localhost,验证在为配置前是无法通过ssh连接本机的
下面在用户目录下(笔者使用的是root用户,所以是/root目录,普通用户的文件夹是在/home,目录下与用户名相同的目录)ls -a ,可以看见有一个隐藏的文件夹.ssh,如果没有的话可以自行创建。然后输入一下命令,出现如下图示:
ssh-keygen -t dsa -P '' -f /root/.ssh/id_dsa

这里解释一下命令的含义(注意区分大小写):ssh-keygen代表生成密钥;-t表示生成密钥的类型;-P提供密语;-f指定生成的文件.这个命令执行完毕后会在.ssh文件夹下生成两个文件,分别是id_dsa、id_dsa.pub,这是SSH的一对私钥和公钥,就像是钥匙和锁。下一步将id_dsa.pub追加到授权的key中,键入一下命令:
cat /root/.ssh/id_dsa.pub >> /root/.ssh/authorized_keys
此时,免密码登录本机就配置完成了,下面再次输入ssh localhost进行验证,出现下图所示信息代表配置成功了
ssh localhost

看上图所示,第一次登录会询问我们是否继续连接,输入yes,第二次就无需询问直接进入了。
以上所述只是本机ssh登录,那么如何让另外三个虚拟机也能无密码访问呢?答案很简单,我们只需要输入一下命令将本机的SSH公钥copy到其他三台虚拟机上并输入相应虚拟机的的密码即可。
ssh-copy-id -i /root/.ssh/id_dsa.pub root@hadoop.slave1 #提示输入hadoop.slave1的密码 ssh-copy-id -i /root/.ssh/id_dsa.pub root@hadoop.slave2 #提示输入hadoop.slave2的密码 ssh-copy-id -i /root/.ssh/id_dsa.pub root@hadoop.slave3 #提示输入hadoop.slave3的密码
再验证一下吧,进入hadoop.slave1,输入ssh hadoop.master,此时会询问是否连接,输入yes后会要求输入hadoop.master的密码,完成后再次输入ssh hadoop.master就可以免密码登录了,剩余的两台虚拟机重复以上步骤就可以了。这样slave1,slave2,slave3就可以免密码登录master了,但是master还不能免密码登录slave1,slave2,slave3,分别进入另外三台虚拟机重复以上步骤就可以了。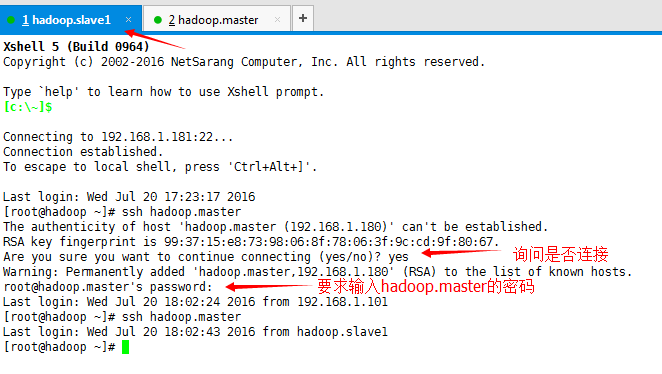
配置完成了,我们开始学习Hadoop的安装吧
Hadoop的安装
1.下载Hadoop安装包,笔者学习使用的是Hadoop1.2.1。提供一下下载地址吧: http://apache.fayea.com/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz。
2.创建/usr/local目录,进入此目录,下载安装包后解压,解压后出出现一个hadoop-1.2.1的文件夹,修改目录名为hadoop,进入该文件夹,目录结构如下图所示
#进入/usr/local cd /usr/local #下载hadoop安装包 wget http://apache.fayea.com/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
#等待下载完毕.....
#解压刚下载好的安装包(解压完后安装包可以删除,但建议备份到其他目录下)
tar -zxvf hadoop-1.2.1.tar.gz
mv hadoop-1.2.1 hadoop
cd hadoop
#查看结构
ll
3.下一步我们配置一下环境变量,在/etc目录下新建一个hadoop目录,后期将hadoop相关配置文件放在该目录下,直接使用该目录下的配置文件,然后编辑/etc/profile文件,追加如下配置并保存,输入source /etc/profile使配置立即生效:
#set hadoop environment export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$PATH
##保存修改后执行
source /etc/profile
4.怎么看是否安装成功呢?现在是单机模式,直接进入/usr/local/hadoop/bin目录中执行start-all.sh命令,过程中会询问是否连接,直接输入yes
cd /usr/local/hadoop/bin
./start-all.sh
5.使用jps命令查看hadoop进程是否启动成功,如下图所示:
6.因为现在是单机模式,NameNode和JobTracker没有启动,现在就使用hadoop fs -ls查看是否安装成功:
hadoop fs -ls

如上图所示,显示的是当前所在目录的目录结构,这样就说明安装成功了.重复以上步骤,为其他三台虚拟机也安装上吧!!
截止以上步骤,Hadoop的安装已经完成了。在下一篇我们在讲如何进行hadoop的集群配置吧!敬请期待哦!
大家支持一下,记得关注!觉得还行的话也可以推荐一下,谢谢!!!