说话人识别领域的研究所面临的挑战
背景噪声问题,跨信道问题,多说话人分割聚类,多模态识别,短语音问题,语音的长时变换问题,耳语音以及其他各种实际应用环境下的鲁棒性问题等。
说话人识别技术研究的核心是解决训练与测试之间的失配问题,这种失配也称作会话变异(Session Variability)导致训练和测试之间差异的因素主要分为两大类:说话人差异,如声道差异、发音特点、说话人风格等,这是对说话人识别有用的部分;会话间差异,如不同的采集设备、传输媒介等,这种失配严重影响说话人识别的性能。在进行说话人识别前,导致会话间差异的各种失配信息都应该被去除。一个理想的说话人识别系统,应该在去除失配信息的同时尽量完整地保留说话人本质特征
- 在具体研究中,语音中说话人个性特征的分离与提取以及精准的模型建模是决定系统性能的两个关键环节。
说话人识别的分类和基本组成
(1)说话人识别根据使用的范围可分为三类:
1)说话人辨认(Speaker Identification),即判定待测试说话人的语音属于几个参考说话人其中之一,是一个多选一问题;
2)说话人确认(Speaker Verification),即确定待测说话人的语音与其特定参考说话人是否相符,是二选一的是非问题,即确认(肯定)或拒绝(否定)。
3)说话人分割和聚类(Speaker segmentation and clustering),此时输入的语音信号由两个或多个不同说话人的语音交替出现组成,需要将每一个说话人的语音都挑出来并且聚类成一类。
(2)说话人辨认研究根据待测试语音的特点可以分为两类:
1)闭集(close-set)识别,即待测说话人的语音必然属于候选说话人集合中的某一位,待测语音要与集合中的说话人模型一一匹配,即待识别说话人属于已知的说话人集合。
2)开集(open-set)识别,部分待测说话人不属于已知的说话人集合,这要求开集情况下待测语音在与集合中的说话人模型库一一匹配后,也可能做出拒绝判定。
(3)说话人研究根据识别内容可以分为两类:
1)文本相关(Text-Dependent)识别,该方法在训练时要求用户按规定的文本发音,每个说话人建立精确地模型(如基于音素或词的模型);识别时,也要求用户按照规定的文本发音。这种约束条件下,一般可以达到较好的识别效果,但需要用户主动配合。
2)文本无关(Text-Independent)识别,此时不规定说话人发音的文本内容,对特征提取和模型建立相对困难,但不需要用户配合,使用方便,应用范围也更宽,成为研究的热点。
说话人识别的特征提取
- 说话人之间(Inter-Speaker)的差异,说话人自身(Intra-Speaker)的差异
现在的前端处理方法,都是使用分帧对语音数据进行处理,因为语音信号是一个非平稳信号。逐帧处理数据也能够体现信号中的时序特性,如果逐点对数据进行处理的话,所需要的计算量太大,而且对于信息的分割也太细。
(1)说话人识别特征的特点
语音信号中同时包含语义信息、说话人信息等不同的信号特征。在说话人识别研究中,希望提取具有更好地说话人鉴别性的特征,该特征应该具有以下几个特点:
- 说话人之间的差异大,而说话人本身的差异性小
- 对噪声和传输信道失真具有良好的鲁棒性
- 在语音中的存在的方式频繁而且自然(是一个固有特征,而非偶然出现或者出现概率较小的特征)
- 易于提取,易于计算
- 不易被模仿
- 不易受说话人的健康、情绪等影响
(2)常用人类声音特征分层
- 语言结构层(高级特征):通过对语音信号的分析,可以获取更为全面和结构化的语义信息,包括语义、言语习惯、发音、修辞等。还有说话人的常用词汇,语言结构等语言结构层的特征主要表征了说话人的受教育水平、生活区域、社会经济状况等信息。
- 韵律层特征:通过分析语音信号,还可以抽取独立于发声和声道等因素的超音段特征,这些特征表征了个人的话语韵律特点,如语调、语速、音量、韵律、方言等。
- 声学层特征(低级特征):针对语音帧,在分析短时信号信息的基础上,抽取对通道、时间不敏感的特征参数,包括语音中的声学特性、鼻音、呼吸音、沙哑特征等。声学层特征主要表征了说话人发音机制的解剖学结构。
**超音段特征(如音高、能量等)在语音感知中起到了重要作用,但这些特征很难被应用于说话人识别中。一方面这些特征的提取比较困难,另一方面这些特征难以参数化,还存在特征易变易仿冒,可以由说话人有意地控制等问题
**
(3)音段特征
目前采用的语音特征参数大多利用低层声学特征,例如线性预测的倒谱系数、基于Mel频率的倒谱系数和感知线性预测系数等。听觉试验结果表明人类的听觉对语音频谱中的过渡信息非常敏感,倒谱系数的差分过程就足可以较好地表达过渡信息的语音特征参数。常用的提取方法是在静态的倒谱参数中加入动态信息来强化特征表示,如加入倒谱的差分特征和自回归参数等((Delta, Delta Delta))。有时,一些时域的参数和高层倍息也常被用作辅助特祉参数(包括短时能量及其一阶差分、功率谱稀疏、基音频率、共振峰及共振峰带宽、鼻音联合特征、习惯用语特征和基于单词或音素的N元模型等),以提高系统的性能。
一般认为,高层次语音信息主要包含在基音频率、声音能量及其差分的概率统计分布中。然而,有研究认为,高层次语音信息(包括重音、语调和韵律)主要体现在基音频率和语音能量变换的动态信息中,可以通过把连续语音划分成离散的单元来提取各种高层信息,还验证了高层信息对低层特征的良好补充且对信道效应不敏感。
说话人识别模型
(1)模板匹配法
(2)统计概率模型法
与传统的模板匹配法相比,统计概率模型法具有更强的灵活性,并且从理论上讲,其概率似然得分更有统计意义。与模板匹配所不同的是:第一,它不根据特征矢量(模板)本身来建模,而是根据特征的概率分布规律来建模;第二,它不根据模板的距离关系来进行类别判定,而是根据概率关系或似然度分进行判别。其中典型的就是GMM-UBM算法,但是这一算法在实际应用中存在运算量大的问题。
(3)人工神经网络法
热点的神经网络算法包括时延神经网络(TDNN),决策树神经网络(DTNN)等。
(4)支持向量机法
(5)稀疏表示法
稀疏表示(Sparse Representation,SR)的原理是利用字典的学习,将信号特征表示成少数基本原子的线性组合的过程。稀疏表示算法使能量相对集中于少量原子,该算法任务对应于系数非零的少量原子描述了信号的主要特性与内在结构。
说话人识别系统的性能评价
- 正确识别率:待识别语音样本中能够被正确地确定说话人的比例
- 错误识别率(错误率)是从另一个角度评价说话人辨认系统的指标
说话人确认系统评价
说话人确认系统的性能通常可以用两个主要指标来表示:错误拒识率(False Rejection Rate,FRR)和错误接收率(False Acceptance Rate,FAR)。前者是拒绝真实的说话人造成的差错,后者是将冒名顶替者错认为说话人造成的差错。
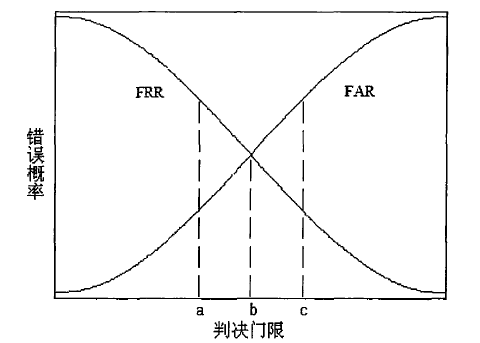
显然,这两个指标是相互矛盾的,在实际应用中需要根据具体任务进行调节。在图中,画出了错误拒绝了-错误接收率曲线。通常情况下,会将判决阈值选择为FRR和FAR相等时的值,该值成为等差错率阈值(Equal Error Rate,EER),并用此时的错误率描述说话人确认系统的整体性能。