root@cloud:~# ps -elf | grep nsexec 0 S root 57368 56786 0 80 0 - 420 wait 14:23 pts/0 00:00:00 ./nsexec 0 S root 57387 57371 0 80 0 - 1418 pipe_r 14:23 pts/1 00:00:00 grep --color=auto nsexec root@cloud:~# ps -elf | grep 57368 0 S root 57368 56786 0 80 0 - 420 wait 14:23 pts/0 00:00:00 ./nsexec 0 S root 57369 57368 0 80 0 - 479 wait_w 14:23 pts/0 00:00:00 /bin/sh 0 S root 57389 57371 0 80 0 - 1418 pipe_r 14:23 pts/1 00:00:00 grep --color=auto 57368
cloud:~/nsexec# ./nsexec -u -i -n -p /bin/ls procname: nsexec , ttyname /dev/pts/0 about to unshare with 6c020000 clone.h debian newuidshell nsexec nsexec.c uidmap uidmaplib.c uidmapshift.c usernsexec.c usernsselfmap.c usernstest.c container-userns-convert Makefile newuidshell.c ns_exec.c setuidshell.c uidmap.c uidmapshift usernsexec usernsselfmap usernstest root@cloud:~/nsexec# ./nsexec -u -i -n -p /bin/bash procname: nsexec , ttyname /dev/pts/0 about to unshare with 6c020000 bash: fork: Cannot allocate memory root@cloud:~/nsexec#
root@cloud:~/nsexec# ./nsexec -u -i -n -p /bin/sh bash: fork: Cannot allocate memory root@cloud:~/nsexec# ls bash: fork: Cannot allocate memory root@cloud:~/nsexec# ls bash: fork: Cannot allocate memory root@cloud:~/nsexec# ls bash: fork: Cannot allocate memory root@cloud:~/nsexec#
root@cloud:~/nsexec# ./nsexec -u -i -n -p /bin/sh procname: nsexec , ttyname /dev/pts/0 about to unshare with 6c020000 execve /bin/sh # ls clone.h debian newuidshell nsexec nsexec.c uidmap uidmaplib.c uidmapshift.c usernsexec.c usernsselfmap.c usernstest.c container-userns-convert Makefile newuidshell.c ns_exec.c setuidshell.c uidmap.c uidmapshift usernsexec usernsselfmap usernstest # exit root@cloud:~/nsexec#

Difference between clone and fork+unshare
Somehow it's easier to call fork and then unshare because many arguments are copied via fork that would otherwise be manually wrapped to clone. My question is, what is the difference between (1) calling clone which forks a new process in separate namespaces and (2) fork+unshare which forks a new process and then leaves parent's namespaces. Assume all namespace flags passed to clone and unshare are the same.
auto flag = CLONE_NEWUSER | CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWNET | SIGCHLD;
So, with fork, its very easy for child to reuse data inherited from parents.
int mydata; // this could be even more complicated, class, struct, etc.
auto pid = fork();
if(pid == 0) {
// reuse inherited data in a copy-on-write manner
unshare(flag);
}
For clone, we sometimes have to wrap data into another struct and pass it as void* to the clone system call.
int mydata;
clone(func, stack+stack_size, flag, &wrapper_of_data);
It seems to me in the above example the only difference is the performance hit, where fork can be a bit more expensive. However, the nature of fork saves me many efforts in the way that both can create a process in new namespaces.
root@cloud:/nsexec# ./nsexec -u -i -n -p -m /bin/sh procname: nsexec , ttyname /dev/pts/2 about to unshare with 6c020000 and 20000000 execve /bin/sh / # ls bin dev etc home proc root sys tmp usr var / # ls root/ /bin/sh: can't fork: Cannot allocate memory / #
root@cloud:/nsexec/go_c/test# ./main about to clone with 5c020000 about to unshare with 5c020011 and 0 execve /bin/sh and pid 78993 / $ init in main.go pid 78993 Hello c, welcome to go! pid 78992 and child 78993 / $ / $ / $ / $ / $ ls bin dev etc hello3.txt home proc root sys tmp usr var / $ ls bin dev etc hello3.txt home proc root sys tmp usr var / $ ls bin dev etc hello3.txt home proc root sys tmp usr var / $ ls dev/ console hello.txt hello2.txt input pts shm / $ pwd / / $ exit string: exit status 0 pid: 78993 Parent dies now.
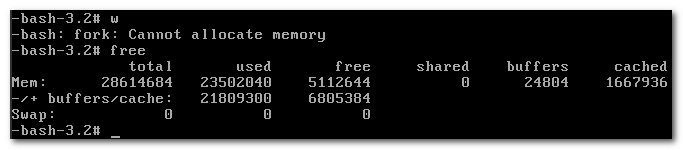
fork: Cannot allocate memory
ree查看内存还有(注意,命令可能要多敲几次才会出来)
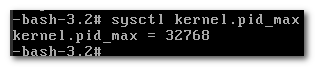
查看最大进程数 sysctl kernel.pid_max
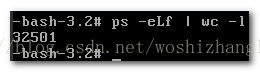
ps -eLf | wc -l查看 进 程数
确认是 进 程数满了
修改最大 进 程数后系统恢复
echo 1000000 > /proc/sys/kernel/pid_max
永久生效
echo "kernel.pid_max=1000000 " >> /etc/sysctl.conf
sysctl -p