基础知识
分布式系统中,我们广泛运用消息中间件进行系统间的数据交换,便于异步解耦。消息中间件这块在我们前面的学习中,是使用python中的queue模块来提供,但这个模块仅限于在本机的内存中使用,假设这个队列需要其他服务器的程序也访问的话,就需要利用socket了。不过,现成的方案很多,轮子已经有了,我们没有必要反复造轮子。直接拿来用就可以了。
消息中间件解决方案
流行的消息队列解决方案很多:
ZeroMQ,号称最快的消息队列,由于支持的模式特别多: TCP、IPC、inproc、Multicas,基本已经打到替代Socket的地步了。站点地址:http://zeromq.org/
Kafka,是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache定级项目。 一个消息发布订阅系统,现在常用于日志团队使用的工具,如程序将操作日志批量异步的发送到Kafka集群中,而不是保存在本地或者DB中。Kafka可以提供批量提交消息/压缩等,对Producer而言,几乎感觉不到性能的开销。Consumer可以使用Hadoop等其他系统化的存储和数据分析等。站点:http://kafka.apache.org/
RocketMQ, 阿里开源的一款高性能、高吞吐量的消息中间件, 纯Java开发。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。站点: https://github.com/alibaba/RocketMQ
RabbitMQ, RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现。
等等....
使用消息中间件的理由?
使用消息中间件的10个理由,请参照oschina的这篇博文: http://www.oschina.net/translate/top-10-uses-for-message-queue
RabbitMQ
一. 历史
RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现。AMQP 的出现其实也是应了广大人民群众的需求,虽然在同步消息通讯的世界里有很多公开标准(如 COBAR的 IIOP ,或者是 SOAP 等),但是在异步消息处理中却不是这样,只有大企业有一些商业实现(如微软的 MSMQ ,IBM 的 Websphere MQ 等),因此,在 2006 年的 6 月,Cisco 、Redhat、iMatix 等联合制定了 AMQP 的公开标准。
RabbitMQ是由RabbitMQ Technologies Ltd开发并且提供商业支持的。该公司在2010年4月被SpringSource(VMWare的一个部门)收购。在2013年5月被并入Pivotal。其实VMWare,Pivotal和EMC本质上是一家的。不同的是VMWare是独立上市子公司,而Pivotal是整合了EMC的某些资源,现在并没有上市。
官方站点:https://www.rabbitmq.com/
RabbitMQ中文: https://rabbitmq-into-chinese.readthedocs.io/zh_CN/latest/
二. 应用架构
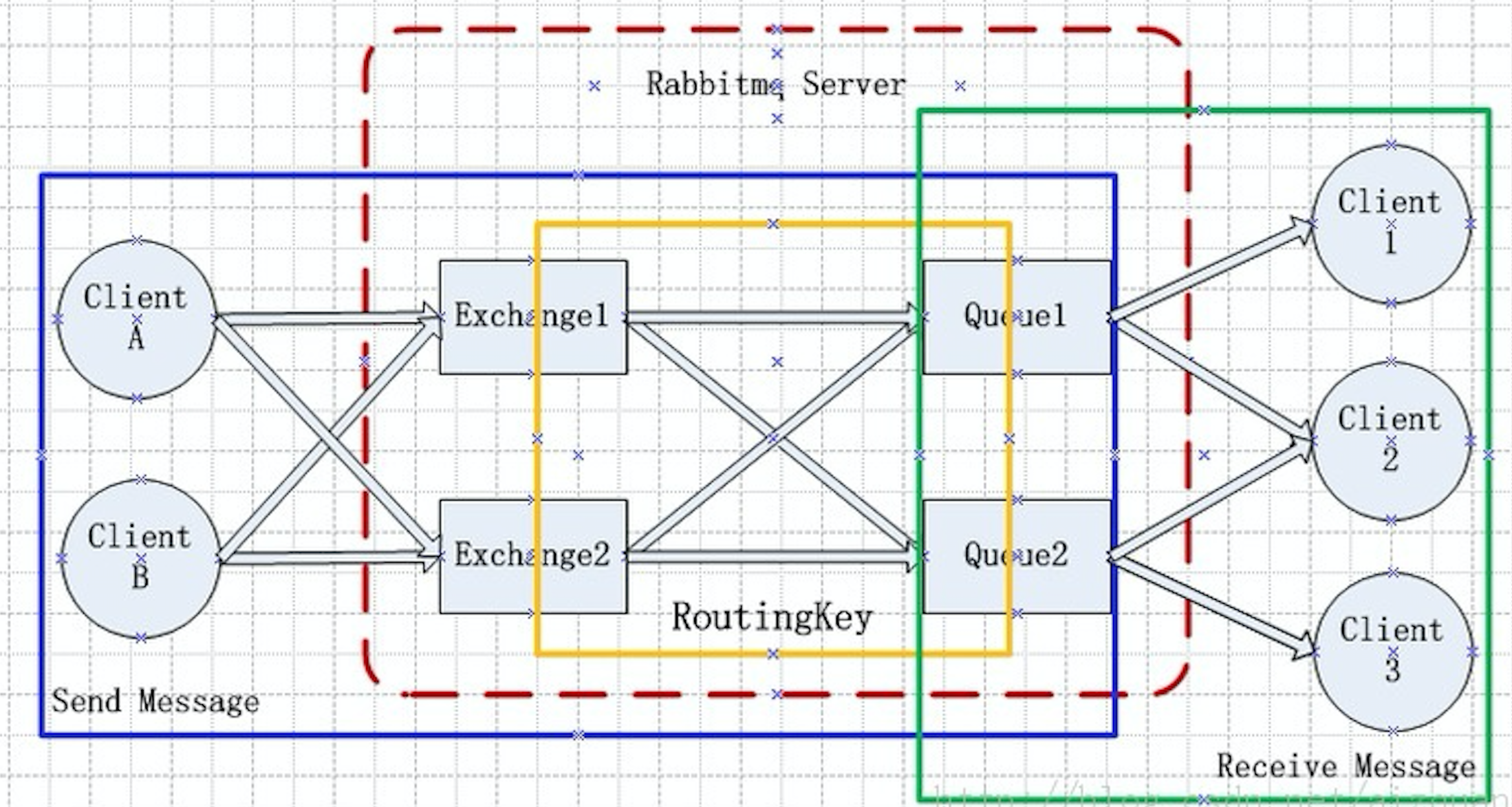
这个系统架构图版权属于sunjun041640。
RabbitMQ Server: 是一种传入服务。 它的角色是维护一条从生产者(Producer) 到 消费者(Consumer)的路线,从而保证数据能够按照指定的方式进行传入。但是也并不是100%的保证,但杜宇普通的应用来说,应该是足够的。当然对于要求可靠性、完整性绝对的场景,可以再走一层数据一致性的guard, 就可以保证了。
Client A 和 Client B:生产者(Producer), 数据的生产者, 发送方。一个消息(Message)有两个部分:有效载荷(payload) 和 标签(label).
- payload: 传入的数据
- lable: exchange的名字或者说是一个tag, payload的描述信息,而且RabbitMQ是通过这个lable来决定把这个消息(Message)发给那个消费者(Consumer).AMQP仅仅描述了lable, 而RabbitMQ决定了如何使用这个lable的规则。
Client1, client2, client3: 消费者(Consumer), 接受消息的应用程序。当有消息(Message)到达某个和Consumer关联的某个队列后,RabbitMQ会把它发送Consumer。当然也可能会发送给多个Consumer。
一个数据从Producer到Consumer,还需要明白三个概念: exchanges, queue 和 bindings
queue:用于消息存储的缓冲
Connection: 一个TCP连接
Channels:虚拟连接。它建立在TCP连接中,数据流动都是channel中进行的。一般情况是起始建立TCP连接,第二部就是建立这个Channel。
三. 安装RabbitMQ
Ubuntu/Debian
apt-get install -y rabbitmq-server
RHEL6:
#安装配置epel源 # rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm #安装erlang # yum -y install erlang #安装RabbitMQ # yum -y install rabbitmq-server
服务启动/停止
#停止服务 #service rabbitmq-server stop #启动服务 #service rabbitmq-server start #重启服务 #service rabbitmq-server restart
安装Python API(Python3)
pip3 install pika #源码安装: https://pypi.python.org/pypi/pika #过程略...
四. 基本操作
基于queue(Python2.7中模块是Queue)实现的生产者消费者模型


#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) import queue import threading message = queue.Queue(10) def producer(i): ''' 生产者 :param i: :return: ''' while True: message.put(i) def consumer(i): ''' 消费者 :param i: :return: ''' while True: msg = message.get() for i in range(12): t = threading.Thread(target=producer, args=(i,)) t.start() for j in range(10): t = threading.Thread(target=consumer, args=(j,)) t.start()
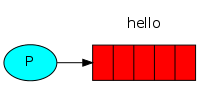
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) import pika #导入模块 ########### 生产者 ################# connection = pika.BlockingConnection( pika.ConnectionParameters(host='172.16.30.162') #端口如果是默认的话,不用谢 ) #建立TCP连接 channel = connection.channel() #虚拟连接,建立在上面的TCP连接基础上 #为什么使用Channel,而不用TCP连接? #因为对于OS来说,建立和关闭TCP连接是有代价的,尤其是频繁的建立和关闭. 而且TCP的连接数默认在系统内核中也有限制, 这也限制了系统处理高并发的能力. #但是,如果在TCP连接中建立 Channel是没有代价的,对于Procuder或者Consumer来讲,可以并发的使用多个channel来进行publish或者receive. channel.queue_declare(queue='hello') #Consumer和Procuder都可以使用 queue_declar创建queue.对某个channel来说,Consumer不能declare一个queue,却可以订阅queue,当然也可以创建私有的queue. #这样就只有APP本身才能使用这个queue. queue也可以自动删除,被标记auto-delete的queue在最后一个Consumer unsubscribe后会被自动删除. #如果创建一个已经存在的queue是不会有任何影响的, 就是说第二次创建如果参数和第一次不一样,那么该操作虽然成功,但是queue的属性并不会被修改. # queue 对 load balance的处理是完美的,对于多个Consumer来说, RabbitMQ使用循环的方式轮训(Round-robin)来均衡发送给不同的Consumer channel.basic_publish( exchange='', #消息是不能直接发送到队列的,它需要发送到交换机(exchange),下面会谈这个,此处使用一个空字符串来标识. routing_key='hello', #必须指定为队列的名称 body='How are you' #消息主体 ) print('Send ok') connection.close() #关闭连接
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) ################################消费者########################################### import pika connection = pika.BlockingConnection( pika.ConnectionParameters(host='172.16.30.162') ) channel = connection.channel() channel.queue_declare('hello') #使用queue_declare创建一个队列——我们可以运行这个命令很多次,但是只有一个队列会被创建。 def callback(ch, method, properties, body): ''' 回调方法,当我们获取到消息的时候,Pika库就会调用此回调函数。这个回调函数会将接收到的消息内容输出到屏幕上。 :param ch: 虚拟通道 :param method: 方法 :param properties: 消息属性 :param body: 消息主体 :return: ''' print('Received: %r' %body) while True: channel.basic_consume( #需要告诉RabbitMQ这个回调函数将会从名为"hello"的队列中接收消息: callback, queue='hello', no_ack=True ) print('Wating for messages. To exit press CTRL+C') channel.start_consuming()
1. 消息确认
为了防止消息丢失,RabbitMQ提供了消息响应(acknowledgments)。消费者会通过一个ack(响应),告诉RabbitMQ已经收到并处理了某条消息,然后RabbitMQ就会释放并删除这条消息。如果消费者(consumer)挂掉了,没有发送响应,RabbitMQ就会认为消息没有被完全处理,然后重新发送给其他消费者(consumer)。这样,及时工作者(workers)偶尔的挂掉,也不会丢失消息。
消息是没有超时这个概念的;当工作者与它断开连的时候,RabbitMQ会重新发送消息。这样在处理一个耗时非常长的消息任务的时候就不会出问题了。
消息响应:默认是开启的 no_ack, 在上面的例子中,我们把标识给置为True(关闭了)。开启后,完成一个任务后,会发送一个响应。
def callback(ch, method, properties, body): print " [x] Received %r" % (body,) time.sleep( body.count('.') ) print " [x] Done" ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue='hello')
PS: 这一来一往的是提高了消息的安全性,但是,开销是难免的,和默认的不加确认消息相比,这种方案性能肯定会有下降,但是这不就是一种妥协么?就看应用场景了.
切记, 不要忘记确认(basic_ack)!消息会在你退出程序之后就重新发送,如果它不能够释放没响应的信息,RabbitMQ就会占用越来越多的内存!
2. 消息持久化
有个参数durable, 默认情况下,如果没有显式告诉RabbitMQ这条消息需要持久化,那么它(rabbitmq)在自己退出或者崩溃的时候,将会丢失所有队列和消息。
为了确保不丢失,需要注意:
必须把队列和消息设置为持久化。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) import pika #导入模块 connection = pika.BlockingConnection( pika.ConnectionParameters(host='172.16.30.162') #端口如果是默认的话,不用谢 ) #建立TCP连接 channel = connection.channel() #虚拟连接,建立在上面的TCP连接基础上 #队列持久化 channel.queue_declare(queue='hello',durable=True) channel.basic_publish( exchange='', #消息是不能直接发送到队列的,它需要发送到交换机(exchange),下面会谈这个,此处使用一个空字符串来标识. routing_key='hello', #必须指定为队列的名称 body='How are you' , #消息主体 properties=pika.BasicProperties(delivery_mode=2) #持久化 ) print(" [x] Sent 'Hello World!'") connection.close() #关闭连接
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) ################################消费者########################################### import pika connection = pika.BlockingConnection( pika.ConnectionParameters(host='172.16.30.162') ) channel = connection.channel() channel.queue_declare('hello') #使用queue_declare创建一个队列——我们可以运行这个命令很多次,但是只有一个队列会被创建。 def callback(ch, method, properties, body): ''' 回调方法,当我们获取到消息的时候,Pika库就会调用此回调函数。这个回调函数会将接收到的消息内容输出到屏幕上。 :param ch: 虚拟通道 :param method: 方法 :param properties: 消息属性 :param body: 消息主体 :return: ''' print('Received: %r' %body) ch.basic_ack(delivery_tag=method.delivery_tag) while True: channel.basic_consume( #需要告诉RabbitMQ这个回调函数将会从名为"hello"的队列中接收消息: callback, queue='hello', no_ack=False #no_ack 置为False ) print('Wating for messages. To exit press CTRL+C') channel.start_consuming()
3. 公平调度
默认消息队列中的数据是按照顺序来消费的。比如有两个workers,处理奇数消息的特别忙,而处理偶数的比较轻松,而RabbitMQ默认的规则还是一如既往的派发消息。它默认才不管你忙不忙!

可以使用basic_qos方法,并设置 prefetch_count=1,告诉RabbitMQ,在同一时刻,不要发送超过一条消息给一个worker,直到它处理了上一条消息并且做出了响应。这样,RabbitMQ就能把消息分给下一个空闲的Worker了。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) ################################消费者########################################### import pika connection = pika.BlockingConnection( pika.ConnectionParameters(host='172.16.30.162') ) channel = connection.channel() channel.queue_declare('hello') #使用queue_declare创建一个队列——我们可以运行这个命令很多次,但是只有一个队列会被创建。 def callback(ch, method, properties, body): ''' 回调方法,当我们获取到消息的时候,Pika库就会调用此回调函数。这个回调函数会将接收到的消息内容输出到屏幕上。 :param ch: 虚拟通道 :param method: 方法 :param properties: 消息属性 :param body: 消息主体 :return: ''' print('Received: %r' %body) ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1) #设置 prefetch_count=1,告诉RabbitMQ,在同一时刻,不要发送超过一条消息给一个worker,直到它处理了上一条消息并且做出了响应。 while True: channel.basic_consume( #需要告诉RabbitMQ这个回调函数将会从名为"hello"的队列中接收消息: callback, queue='hello', no_ack=False ) print('Wating for messages. To exit press CTRL+C') channel.start_consuming()
PS: 如果所有的工作者都处理很繁忙,你的队列就可能会被填满,需要留意这个问题,要么添加更多的Workers,要么使用其他策略!
4. 发布/订阅
分发一个消息给多个消费者(Consumers), 这种模式,称为"发布/订阅"
发布者只需要把消息发送给exchange。exchange一边从发布者放接受消息,一边推送到队列。
exchange必须知道如何处理它接收到的消息,是应该推送到指定的队列还是是多个队列,或者是直接忽略消息。这些规则是通过交换机类型(exchange type)来定义的。
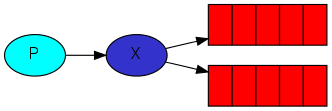
exchange的几个类型:
direct: 直连, 通过binding key的完全匹配来传递消息到相应的队列中
topic:主题交换机,exchange将传入的”路由值“ 和”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
- # 表示可以匹配0个 或者多个单词
- * 表示只能匹配一个单词
#发送者路由值 队列中 www.dbq168.com www.* #不匹配 www.dbq168.com www.# #匹配成功
fanout:扇形交换机, 把消息发送给和他关联的所有的队列
headers: 头交换机
root@test2-ubunut:~# rabbitmqctl list_exchanges Listing exchanges ... direct amq.direct direct amq.fanout fanout amq.headers headers amq.match headers amq.rabbitmq.log topic amq.rabbitmq.trace topic amq.topic topic direct_logs direct logs fanout ...done.
fanout,绑定(binding)

创建一个fanout类型的exchange 和队列, 而后告诉交换机如何发送消息给我们的队列。exchange和queue之间的关系为 绑定(binding)。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) #fanout import pika #导入模块 connection = pika.BlockingConnection( pika.ConnectionParameters(host='172.16.30.162') #端口如果是默认的话,不用谢 ) #建立TCP连接 channel = connection.channel() #虚拟连接,建立在上面的TCP连接基础上 channel.exchange_declare(exchange='logs', type='fanout') #使用fanout类型 message = 'baslkdfk2sdf' channel.basic_publish( exchange='logs', #消息是不能直接发送到队列的,它需要发送到交换机(exchange),exchange值必须为定义好的exchange值 routing_key='', body=message #消息主体 ) print(" [x] Sent %s"%message) connection.close() #关闭连接
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) # fanout ################################消费者########################################### import pika connection = pika.BlockingConnection( pika.ConnectionParameters(host='172.16.30.162') ) channel = connection.channel() channel.exchange_declare( exchange='logs', type='fanout' ) result = channel.queue_declare(exclusive=True) queue_name = result.method.queue channel.queue_bind( exchange='logs', queue=queue_name ) print('Wating for messages. To exit press CTRL+C') def callback(ch, method, properties, body): ''' 回调方法,当我们获取到消息的时候,Pika库就会调用此回调函数。这个回调函数会将接收到的消息内容输出到屏幕上。 :param ch: 虚拟通道 :param method: 方法 :param properties: 消息属性 :param body: 消息主体 :return: ''' print('Received: %r' %body) ch.basic_ack(delivery_tag=method.delivery_tag) while True: channel.basic_consume( #需要告诉RabbitMQ这个回调函数将会从名为"hello"的队列中接收消息: callback, queue=queue_name, no_ack=False ) channel.start_consuming()
direct,多个绑定(Multiple bindings)

多个队列使用相同的绑定键是合法的。上图这个例子中,我们可以添加一个X和Q1之间的绑定,使用black绑定键。这样一来,直连交换机就和扇型交换机的行为一样,会将消息广播到所有匹配的队列。带有black路由键的消息会同时发送到Q1和Q2。

#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) #fanout import pika #导入模块 connection = pika.BlockingConnection( pika.ConnectionParameters(host='172.16.30.162') #端口如果是默认的话,不用写 ) #建立TCP连接 channel = connection.channel() #虚拟连接,建立在上面的TCP连接基础上 channel.exchange_declare(exchange='direct_logs', type='direct') #使用direct类型 message = 'info message' facility = 'info' #如果生产者发送一个info消息的话,两个消费者都能收到; 如果发送一个error级别的消息,只有 error级别的能收到.. channel.basic_publish( exchange='direct_logs', #消息是不能直接发送到队列的,它需要发送到交换机(exchange),exchange值必须为定义好的exchange值 routing_key=facility, body=message #消息主体 ) print(" [x] Sent %s"%message) connection.close() #关闭连接
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) # fanout ################################消费者########################################### import pika connection = pika.BlockingConnection( pika.ConnectionParameters(host='172.16.30.162') ) channel = connection.channel() channel.exchange_declare( exchange='direct_logs', type='direct' ) result = channel.queue_declare(exclusive=True) queue_name = result.method.queue facility = ['info'] #日志级别定义为info for severity in facility: #递归绑定到队列 channel.queue_bind( exchange='direct_logs', queue=queue_name, routing_key=severity ) print('Wating for messages. To exit press CTRL+C') def callback(ch, method, properties, body): ''' 回调方法,当我们获取到消息的时候,Pika库就会调用此回调函数。这个回调函数会将接收到的消息内容输出到屏幕上。 :param ch: 虚拟通道 :param method: 方法 :param properties: 消息属性 :param body: 消息主体 :return: ''' print('Received: %r' %body) ch.basic_ack(delivery_tag=method.delivery_tag) while True: channel.basic_consume( #需要告诉RabbitMQ这个回调函数将会从名为"hello"的队列中接收消息: callback, queue=queue_name, no_ack=False ) channel.start_consuming()
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) # fanout ################################消费者########################################### import pika connection = pika.BlockingConnection( pika.ConnectionParameters(host='172.16.30.162') ) channel = connection.channel() channel.exchange_declare( exchange='direct_logs', type='direct' ) result = channel.queue_declare(exclusive=True) queue_name = result.method.queue facility = ['info','warnning','error'] #定义为info, warnning, error的级别 for severity in facility: #递归绑定队列 channel.queue_bind( exchange='direct_logs', queue=queue_name, routing_key=severity ) print('Wating for messages. To exit press CTRL+C') def callback(ch, method, properties, body): ''' 回调方法,当我们获取到消息的时候,Pika库就会调用此回调函数。这个回调函数会将接收到的消息内容输出到屏幕上。 :param ch: 虚拟通道 :param method: 方法 :param properties: 消息属性 :param body: 消息主体 :return: ''' print('Received: %r' %body) ch.basic_ack(delivery_tag=method.delivery_tag) while True: channel.basic_consume( #需要告诉RabbitMQ这个回调函数将会从名为"hello"的队列中接收消息: callback, queue=queue_name, no_ack=False ) channel.start_consuming()
Topic

发送到主题交换机(topic exchange)的消息不可以携带随意什么样子的路由键(routing_key),它的路由键必须是一个由.分隔开的词语列表。这些单词随便是什么都可以,但是最好是跟携带它们的消息有关系的词汇。以下是几个推荐的例子:"stock.usd.nyse", "nyse.vmw", "quick.orange.rabbit"。词语的个数可以随意,但是不要超过255字节。
*(星号) 用来表示一个单词.#(井号) 用来表示任意数量(零个或多个)单词
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) #fanout import pika #导入模块 connection = pika.BlockingConnection( pika.ConnectionParameters(host='172.16.30.162') #端口如果是默认的话,不用谢 ) #建立TCP连接 channel = connection.channel() #虚拟连接,建立在上面的TCP连接基础上 channel.exchange_declare(exchange='topic_logs', type='topic') #使用topic类型 message = 'How are you' routing_key = 'anonymouns.info' channel.basic_publish( exchange='topic_logs', #消息是不能直接发送到队列的,它需要发送到交换机(exchange),exchange值必须为定义好的exchange值 routing_key=routing_key, body=message #消息主体 ) print(" [x] Sent %s"%message) connection.close() #关闭连接
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) # fanout ################################消费者########################################### import pika connection = pika.BlockingConnection( pika.ConnectionParameters(host='172.16.30.162') ) channel = connection.channel() channel.exchange_declare( exchange='topic_logs', type='topic' #topic类型 ) result = channel.queue_declare(exclusive=True) queue_name = result.method.queue binding_key = ['anonymouns.info'] for items in binding_key: channel.queue_bind( exchange='topic_logs', queue=queue_name, routing_key=items ) print('Wating for messages. To exit press CTRL+C') def callback(ch, method, properties, body): ''' 回调方法,当我们获取到消息的时候,Pika库就会调用此回调函数。这个回调函数会将接收到的消息内容输出到屏幕上。 :param ch: 虚拟通道 :param method: 方法 :param properties: 消息属性 :param body: 消息主体 :return: ''' print('Received: %r' %body) ch.basic_ack(delivery_tag=method.delivery_tag) while True: channel.basic_consume( #需要告诉RabbitMQ这个回调函数将会从名为"hello"的队列中接收消息: callback, queue=queue_name, no_ack=False ) channel.start_consuming()
更多,请参照官方文档
参考博客:
- http://www.cnblogs.com/wupeiqi/articles/5132791.html
- http://blog.csdn.net/anzhsoft/article/details/19563091
- http://rabbitmq.mr-ping.com/