今天这篇文章源于上周在工作中解决的一个实际问题,它是个比较普遍的问题,无论做什么开发,估计都有遇到过。具体是这样的,我们有一份高校的名单(2657个),需要从海量的文章标题中找到包含这些高校的标题,其实就是模糊查询(关注公众号 渡码, 回复关键词 trie 获取源码)。对应的伪代码如下
selected_titles = []
for 标题 in 海量标题:
for 高校 in 高校名单:
if 标题.contains(高校):
selected_titles.add(标题)
break
如果是大数据开发,对应的SQL的伪代码是这样的
select title
from tb
where
title rlike '清华大学|北京大学|...2657个高校'
上面这两种做法都能实现我们的需求,但它们的共同问题是查询效率太低。如果我们要匹配的高校不是2657个而是几十万甚至上百万,那这种方式耗费时之久是不可想象的。
优化这类问题通常需要在数据结构上做文章,这个问题中我们能优化的数据结构也只有“高校名单”这个了,上面的伪代码中我们存放“高校名单”的数据结构是数组,当我们查找某个title是否包含某个高校的时候,需要从头到尾遍历一遍“高校名单”,并且名单越长,遍历耗时就越长。
清楚了数组这种数据结构的缺点后,接下来我们重点要做的就是寻找一个数据结构可以做到在不遍历整个“高校名单”的情况下就可以完成模糊查询。这个数据结构就是我们今天要介绍的 Trie 树,冷眼一看这个单词有点陌生,又是一个树型结构,感觉会很复杂似的,实际上这个数据结构的设计思想非常简单,一学就会。
下面我们就来学习一下 Trie 树。为了方面讲解,假设“高校名单”里只有下面5个元素
ABC、ABD、BCD、BCE、C、CAB、CDE
对应的两种数据结构如下:
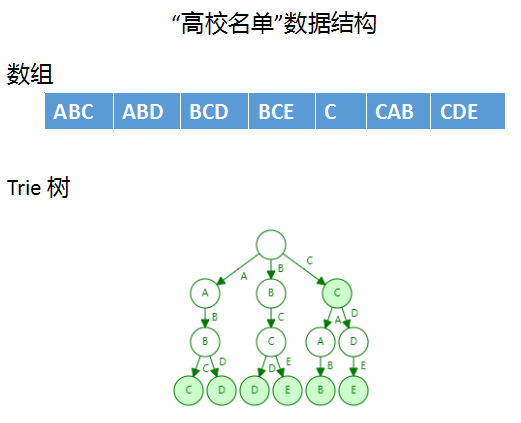
抛开这两种数据结构查找的时间复杂度,我们先从直观上看看为什么 Trie 树的查找效率要比数组高。假设我们要查找,“CDE”这个字符串,在数组结构中,我们要遍历一遍数组,比较7次才能找到结果,做了比较多的“无用功”。而在 Tire 树中只需要比较3次就可以找到,它的优势非常明显,由于树型结构我们根本不用考虑左侧A、B开头的两个分支,这就大大减少了比较的次数,从而减少“无用功”。下面用一个动画来演示一下如何创建 Trie 树,以及在 Trie树上查找字符串(如果视频播放不了可以看源码目录中的gif)

树的建立过程其实就是遍历字符串每个元素并在树上建立相应的节点。字符串查找过程其实就是按照字符串对树进行遍历。Trie 树的建立与字符串查找还是比较简单的。
不知道大家是否注意到上图 Trie 树中的节点有两种颜色——白色和绿色。绿色节点代表从根节点到当前节点的字符串是“高校名单”中的字符串,也就是我们建立 Trie 树用到的字符串。以最左侧的叶子结点“C”为例,它代表“ABC”字符串是“高校名单”中的字符串。同理,字符串“AB”就不是“高校名单”里的元素,因为“B”节点不是绿色的,因此当我们在这棵树上查找字符串“AB”时,是查不到的。这一点需要大家注意,下面编码中我们也有体现。
另外,有朋友可能会有疑问,我们最开始的需求不是模糊查询吗,在 Trie 树讲解这部分怎么都在说字符串全词(精确)匹配。这是因为全词匹配是 Tire 树支持的最基本的查找方式,在此基础上,我们做一些变通就可以很容易实现模糊匹配。
接下来,我们就来看看代码实现(Python版),首先创建两个数组
colleges = utils.read_file_to_list('key_words.txt')
titles = utils.read_file_to_list('titles.txt')
colleges就是我们一直在说的“高校名单”,titles便是“海量标题”,它们都是一维数组,数组每个元素都是一个字符串。
再来编写 Trie 树相关的代码,如果理解了 Trie 树的设计思想,再编写下面的代码其实很容易。首先要定义一个类代表 Trie 树节点
class TrieNode:
def __init__(self):
self.nodes = dict()
# is_end=True 代表从根节点到当前节点构造Trie树的字符串(出现在“高校名单”里)
self.is_end = False
is_end=True就是我们上面说的绿色节点。
再来编写创建 Trie 树的代码,代码在 TrieNode 类中
def insert_many(self, items: [str]):
"""
支持输入字符串数组,直接构造一个 Trie 树
:param items: 字符串数组
:return: None
"""
for word in items:
self.insert(word)
def insert(self, item: str):
"""
向 Trie 树插入一个短语
:param item: 待插入的字符串
:return: None
"""
curr = self
for word in item:
if word not in curr.nodes:
curr.nodes[word] = TrieNode()
curr = curr.nodes[word]
curr.is_end = True
再来编写查找 Trie 树的代码,代码在 TrieNode 类中
def suffix(self, item: str) -> bool:
"""
匹配前缀,也就是判断item字符串是否是以“高校名单”中某个字符串开头
:param item: 待匹配字符串
:return: True or False
"""
curr = self
for word in item:
if word not in curr.nodes:
return False
curr = curr.nodes[word] # 取得子节点
if curr.is_end: # 如果is_end=True说明当前字符串包含了“高校名单”的某个字符串
return True
return False # 未匹配上
这里并不是全词匹配,而是前缀匹配,也就是判断待查找的字符串item是否是以“高校名单”中某个字符串开头。
再来编写模糊匹配,代码在 TrieNode 中
def infix(self, item: str) -> bool:
for i in range(len(item)):
sub_item = item[i:] # 将待查找的字符串分成不同子串
# 如果子串的前缀在 Trie 树中能匹配上
# 说明待查找的字符串item中包含“高校名单”中的元素,
# 即实现了 tile rlike '清华大学|北京大学|...其他大学' 的功能
if self.suffix(sub_item):
return True
return False
这里其实就是把待查找字符串item分成不同子串去做前缀匹配,如果子串匹配上,那就说整个字符串item就包含了“高校名单”里面的某个字符串。
最后,我们运行一下上面的代码,并记录查找时间,与最开始数组结构那一版做个对比。代码如下
# 数组版本
cnt = 0
start_time = int(time.time() * 1000)
for title in titles:
for x in colleges:
if x in title:
cnt += 1
break
end_time = int(time.time() * 1000)
print(cnt)
print('spend: %.2fs' % ((end_time - start_time) / 60.0))
# Trie 树版本
root = TrieNode()
root.insert_many(colleges)
cnt = 0
start_time = int(time.time() * 1000)
for title in titles:
if root.infix(title):
cnt += 1
end_time = int(time.time() * 1000)
print(cnt)
print('spend: %.2fs' % ((end_time - start_time) / 60.0))
输出结果如下:
5314
spend: 9.13s
5314
spend: 0.23s
可以看到,用数组匹配用了9s,而用 Trie 树匹配仅用0.23s!
今天介绍的这种提高海量数据模糊查询性能的方式是通过写代码的方式实现的,对于经常写 SQL 的大数据开发者来说,要把它用起来只是建个 UDF 就可以了,需要在 UDF 的初始化代码中用“高校名单”建立一颗 Trie 树。
今天的内容就分享到这里了,希望对你有帮助。公众号回复关键词 trie 获取完整源代码
欢迎公众号「渡码」,输出别地儿看不到的干货。
