言归正传,介绍过hadoop的simple认证和kerberos后,我们在这一章介绍hadoop的kerberos认证
我们还使用hadoop集群的机器。
OS 版本: Centos6.4
Kerberos版本: krb5-1.10.3
环境配置
|
机器名 |
Ip地址 |
功能 |
安装模块 |
|
ganglia.localdomain |
192.168.124.140 |
Kerberos server |
krb5-libs krb5-server krb5-workstation krb5-devel |
|
hadoop1.localdomain |
192.168.124.135 |
Namenode Datanode Jobtracker tasktracker |
krb5-libs krb5-workstation krb5-appl-clients |
|
hadoop2.localdomain |
192.168.124.136 |
Datanode tasktracker |
Krb5-libs Krb5-workstation krb5-appl-servers |
|
hadoop3.localdomain |
192.168.124.137 |
Datanode tasktracker |
Krb5-libs Krb5-workstation krb5-appl-servers |
kerberos的安装,这里就不介绍了,我们创建了一个LOCALDOMAIN域的数据库
我们还是要给出配置文件的信息给大家参考
vi /etc/krb5.conf 主要修改realm
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
default_realm = LOCALDOMAIN
dns_lookup_realm = false
dns_lookup_kdc = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
[realms]
LOCALDOMAIN = {
kdc = ganglia.localdomain
admin_server = ganglia.localdomain
}
[domain_realm]
.example.com = LOCALDOMAIN
example.com = LOCALDOMAIN
vi /var/kerberos/krb5kdc/kdc.conf
[kdcdefaults]
kdc_ports = 88
kdc_tcp_ports = 88
[realms]
LOCALDOMAIN = {
#master_key_type = aes256-cts
acl_file = /var/kerberos/krb5kdc/kadm5.acl
dict_file = /usr/share/dict/words
admin_keytab = /var/kerberos/krb5kdc/kadm5.keytab
max_renewable_life=10d
supported_enctypes = aes256-cts:normal aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal
}
vi /var/kerberos/krb5kdc/kadm5.acl
*/admin@LOCALDOMAIN *
在hadoop中,kerberos需要创建principle和生成keytab文件。
1. 创建principle
hadoop的kerberos认证,需要三种principle: hadoop, host, HTTP
addprinc -randkey hadoop/hadoop1.localdomain@LOCALDOMAIN
addprinc -randkey hadoop/hadoop2.localdomain@LOCALDOMAIN
addprinc -randkey hadoop/hadoop3.localdomain@LOCALDOMAIN
addprinc -randkey host/hadoop1.localdomain@LOCALDOMAIN
addprinc -randkey host/hadoop2.localdomain@LOCALDOMAIN
addprinc -randkey host/hadoop3.localdomain@LOCALDOMAIN
addprinc -randkey HTTP/hadoop1.localdomain@LOCALDOMAIN
addprinc -randkey HTTP/hadoop2.localdomain@LOCALDOMAIN
addprinc -randkey HTTP/hadoop3.localdomain@LOCALDOMAIN
使用listprincs查看一下结果
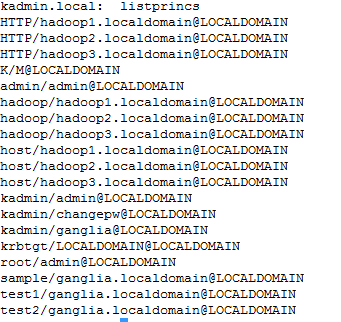
2. 创建keytab文件:hadoop.keytab
ktadd -norandkey -k /root/hadoop.keytab hadoop/hadoop1.localdomain@LOCALDOMAIN
ktadd -norandkey -k /root/hadoop.keytab hadoop/hadoop2.localdomain@LOCALDOMAIN
ktadd -norandkey -k /root/hadoop.keytab hadoop/hadoop3.localdomain@LOCALDOMAIN
ktadd -norandkey -k /root/hadoop.keytab host/hadoop1.localdomain@LOCALDOMAIN
ktadd -norandkey -k /root/hadoop.keytab host/hadoop2.localdomain@LOCALDOMAIN
ktadd -norandkey -k /root/hadoop.keytab host/hadoop3.localdomain@LOCALDOMAIN
ktadd -norandkey -k /root/hadoop.keytab HTTP/hadoop1.localdomain@LOCALDOMAIN
ktadd -norandkey -k /root/hadoop.keytab HTTP/hadoop2.localdomain@LOCALDOMAIN
ktadd -norandkey -k /root/hadoop.keytab HTTP/hadoop3.localdomain@LOCALDOMAIN
查看一下结果
klist -kt /root/hadoop.keytab

将/root/hadoop.keytab 上传到hadoop1,hadoop2和hadoop3上
修改三个bug
- Jdk,需要下载jce(Java Cryptography Extension)1.6.32不需要安装,低一点的版本需要。http://www.oracle.com/technetwork/java/javase/downloads/index.html
- 时间同步问题,kdc和运行hadoop的服务器,时间必须是同步的,如果在虚拟机中运行,如果时间不一致,也会造成credential失效。
- Kdc默认不支持renew功能的,运行kinit 后”valid starting" and "renew until"的值是相同的时间,或者运行kinit –R后出现 kinit: Ticket expired while renewing credentials
有两种方法可以解决此问题,第一种方式就是在创建domain之前,在kdc.conf中增加 max_renewable_life = 7d,然后创建domain。第二种方式使用modprinc修改所有的principle,modprinc -maxrenewlife 7days krbtgt/ganglia.localdoamin/LOCALDOMAIN
modprinc -maxrenewlife 7days K/M/LOCALDOMAIN
modprinc -maxrenewlife 7days hadoop/hadoop1.localdomain/LOCALDOMAIN
modprinc -maxrenewlife 7days hadoop/hadoop2.localdomain/LOCALDOMAIN
modprinc -maxrenewlife 7days hadoop/hadoop3.localdomain/LOCALDOMAIN
modprinc -maxrenewlife 7days host/hadoop1.localdomain/LOCALDOMAIN
modprinc -maxrenewlife 7days host/hadoop2.localdomain/LOCALDOMAIN
modprinc -maxrenewlife 7days host/hadoop3.localdomain/LOCALDOMAIN
modprinc -maxrenewlife 7days HTTP/hadoop1.localdomain/LOCALDOMAIN
modprinc -maxrenewlife 7days HTTP/hadoop2.localdomain/LOCALDOMAIN
modprinc -maxrenewlife 7days HTTP/hadoop3.localdomain/LOCALDOMAIN
配置hadoop
vi conf/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/repo4/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1.localdomain:9000</value>
</property>
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>
</configuration>
修改conf/hadoop-env.sh,增加下面一句
export HADOOP_SECURE_DN_USER=hadoop
启动hdfs
在hadoop1上运行: bin/hadoop namenode
在hadoop1,hadoop2和hadoop3上运行: sudo bin/hadoop datanode
如果按照上面的步骤做,应该是可以能够启动hdfs的。
下面我们再配置一下mapred
vi conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/repo4/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/repo4/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.web.authentication.kerberos.principal</name>
<value>HTTP/_HOST@LOCALDOMAIN</value>
</property>
<property>
<name>dfs.namenode.kerberos.https.principal</name>
<value>host/_HOST@KERBEROS_HADOOP</value>
</property>
<property>
<name>dfs.web.authentication.kerberos.keytab</name>
<value>/home/hadoop/hadoop-1.2.1/conf/hadoop.keytab</value>
</property>
<property>
<name>dfs.namenode.keytab.file</name>
<value>/home/hadoop/hadoop-1.2.1/conf/hadoop.keytab</value>
</property>
<property>
<name>dfs.namenode.kerberos.principal</name>
<value>hadoop/_HOST@LOCALDOMAIN</value>
</property>
<property>
<name>dfs.namenode.kerberos.https.principal</name>
<value>host/_HOST@LOCALDOMAIN</value>
</property>
<property>
<name>dfs.secondary.namenode.keytab.file</name>
<value>/home/hadoop/hadoop-1.2.1/conf/hadoop.keytab</value>
</property>
<property>
<name>dfs.secondary.namenode.kerberos.principal</name>
<value>hadoop/_HOST@LOCALDOMAIN</value>
</property>
<property>
<name>dfs.secondary.namenode.kerberos.https.principal</name>
<value>host/_HOST@LOCALDOMAIN</value>
</property>
<property>
<name>dfs.datanode.keytab.file</name>
<value>/home/hadoop/hadoop-1.2.1/conf/hadoop.keytab</value>
</property>
<property>
<name>dfs.datanode.kerberos.principal</name>
<value>hadoop/_HOST@LOCALDOMAIN</value>
</property>
<property>
<name>dfs.datanode.kerberos.https.principal</name>
<value>host/_HOST@LOCALDOMAIN</value>
</property>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:1004</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:1006</value>
</property>
</configuration>
- 修改conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://hadoop1.localdomain:9001</value>
</property>
<property>
<name>mapreduce.jobtracker.kerberos.principal</name>
<value>mapred/_HOST@LOCALDOMAIN</value>
</property>
<property>
<name>mapreduce.jobtracker.kerberos.https.principal</name>
<value>host/_HOST@LOCALDOMAIN</value>
</property>
<property>
<name>mapreduce.jobtracker.keytab.file</name>
<value>/home/hadoop/hadoop-1.2.1/conf/mapred.keytab</value>
</property>
<property>
<name>mapreduce.tasktracker.kerberos.principal</name>
<value>mapred/_HOST@LOCALDOMAIN</value>
</property>
<property>
<name>mapreduce.tasktracker.kerberos.https.principal</name>
<value>host/_HOST@LOCALDOMAIN</value>
</property>
<property>
<name>mapreduce.tasktracker.keytab.file</name>
<value>/home/hadoop/hadoop-1.2.1/conf/mapred.keytab</value>
</property>
<property>
<name>mapred.task.tracker.task-controller</name>
<value>org.apache.hadoop.mapred.LinuxTaskController</value>
</property>
<property>
<name>mapreduce.tasktracker.group</name>
<value>hadoop</value>
</property>
</configuration>
修改后xml配置文件后,还需要做如下几步
1. 修改tasktracker的配置文件
先修改conf/taskcontroller.cfg
mapred.local.dir=/home/hadoop/repo4/mapred/local
hadoop.log.dir=/home/hadoop/hadoop-1.2.1/logs
mapreduce.tasktracker.group=hadoop
banned.users=hdfs
在创建mapred.local.dir和hadoop.log.dir指定的目录
2. 启动一下tasktracker来看一下 bin/hadoop tasktracker
出现了第一个异常: /etc/hadoop/taskcontroller.cfg not found,原因是bin/tasktracker默认使用etc/hadoop位置的taskcontroller.cfg

我们将taskcontroller.cfg复制到/etc/hadoop
sudo mkdir /etc/hadoop
sudo scp conf/taskcontroller.cfg /etc/hadoop/
3. 启动tasktracer: bin/hadoop tasktracker
可执行文件task-controller的所属者必须是root

我们改变一下文件的所属者
sudo chown root:root bin/task-controller
4. 继续启动tasktracker: bin/hadoop tasktracker
异常继续出现:配置的组必须等于task-controller所属组

我们继续改变一下文件的所属着和所属组
sudo chown root:hadoop bin/task-controller
5. 继续启动tasktracker: bin/hadoop tasktracker
检查其他用户还有异常:task-controller其他用户不能有写和执行权限

运行命令去改变用户权限
sudo chmod o-rx bin/task-controller
6. 继续启动tasktracker: bin/hadoop tasktracker
task-controller还需要被设置setuid标志位

运行命令去设置setuid标志位
sudo chmod u+s bin/task-controller
7. 继续启动tasktracker: bin/hadoop tasktracker
用户的id比1000小

Cat /etc/passwd,查看一下用户id,然后设置参数min.user.id,通常普通用户创建,都是从500开始,因为我们可以修改sudo vi /etc/hadoop/taskcontroller.cfg
min.user.id=500
测试一下mapred程序,我们还是用wordcount作为例子
前面我们已经启动了hdfs,再启动mapred
在hadoop1运行:bin/hadoop jobtracker
在hadoop1,hadoop2和hadoop2上运行: bin/hadoop tasktracker
创建一个输入目录:
bin/hadoop dfs -mkdir /user/hadoop/input
上传一些文件
bin/hadoop dfs -copyFromLocal conf/* /user/hadoop/input/
查看一下结果
bin/hadoop dfs -ls /user/hadoop/input/

启动mapred程序
使用kerberos认证的缺点
- 存在单点失败:它需要KDC中心服务器的服务。当KDC挂掉时,整个系统有可能瘫痪。Hadoop花了很多时间来解决namenode的单点问题。幸亏这个缺陷可以通过使用复合Kerberos服务器和缺陷认证机制弥补
- Kerberos需要时间同步技术,Kerberos要求参与通信的主机的时钟同步,如果主机的时钟与Kerberos服务器的时钟不同步,认证会失败。默认设置要求时钟的时间相差不超过10分钟。通常用网络时间协议后台程序(NTP)来保持主机时钟同步。
- 配置非常繁琐,通常配置好一个100个节点的服务器,需要三天时间。而且还会存在一个大的问题:用户权限的问题,原来系统上的数据不能访问。这一点还需要完善。
- 因为所有用户使用的密钥都存储于中心服务器中,危及服务器的安全的行为将危及所有用户的密钥。
总结
Kerberos是一种性能比较高的认证和授权,并且能够进行数据加密的安全系统,但是并不是特别适合hadoop,原因有三点:1. Hadoop集群节点数多,配置和维护一个使用kerberos系统高性能,稳定的hadoop集群难度非常高。2. Hadoop中的hdfs是一个文件系统,用户的认证和授权比较复杂,难度不低于linux系统的用户和组管理。加上kerberos后,用户和用户组的管理更加复杂,通常一个合适的用户不能访问hdfs上的文件。 3. Hadoop加上kerberos后,通常原来的用户和文件,可能都失效导致数据流失。尤其是一些根目录,往往需要格式化整个系统才能使用。增加一个新用户也是比较难的。因为要考虑各个节点间的访问权限。 我认为可能轻量级的LDAP会适合hadoop系统,后面有时间来实现一下。