一. 列表(list)
1. 列表初始化定义有两种方式:
1.a=[] #空list
2.a=list() #空list
2.列表的下标是从0开始:
#list #列表、数组
stus = ['王志华','乔美玲','段鑫琪','王立文' ]
# 0 1 2 3
列表的长度:len

结果如下:

3.列表的新增:
1.直接加在末尾:append

结果如下:

2.指定位置增加:insert,带下标和要插入的值

结果如下:

4.列表的修改:直接通过下标赋值,下标一定要在列表的长度范围内(可以用正负数,-1代表列表的最后一位),超出则报错
正常赋值:

结果如下:
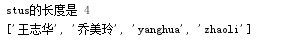
异常赋值:超出列表范围

结果如下:

5.列表的删除:
1.pop:有返回值,是返回删除的那个元素。不带参数为默认删除列表的最后一个元素,也可以指定下标。如果指定一个不存在的下标,则会报错。是对下标指定删除。
正常删除:

结果如下:

异常删除:

结果如下:

2.remove:返回None,通过列表元素值删除,如果传入一个不存在的元素,则会报错。是对元素值指定删除。
技术要点:
1)在列表非尾部增加或删除元素时,该位置后面元素会向后移动或向前移动,保证元素之间没有缝隙,这样的话,这些元素的索引会发生变化。
2)remove()方法删除列表中指定值的首次出现,也就是说,以lst.remove(3)为例,如果列表lst中有多个3,那么只有第一个3被删除,同时该位置后面的所有元素向前移动,索引减1。
正常删除:

结果如下:
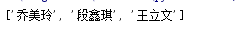
异常删除:

结果如下:

3. del:返回None,是通过列表进行下标检索删除。如果指定不存在则报错。是对一个变量进行指定删除,由于是对列表变量进行删除,则可以删除一个列表区间段和整个列表,del是解除变量的引用,当整个列表引用解除后,列表则不存在。
正常删除:

结果如下:
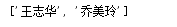
批量删除:

结果如下:
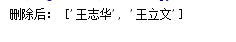
因为参数是变量,则也可以删除整个列表,删除后的列表不可用。
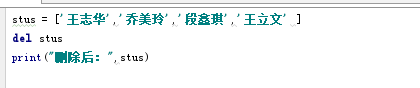

异常删除:

结果如下:

4.清空列表:clear
与del不同,clear只是清空列表数据,不会解除对列表的引用,清空完列表还在。


6.列表的查找:
1.通过指定下标获取某个元素的值:stus[3]
2.查询某个元素在list里面出现的次数:count,如果未出现则为0


3.返回某个元素的下标:index,如果列表里出现多次,则返回第一次出现的下标。如果元素不存在则报错。
正常测试:


异常查询:


7.列表排序:
1.reverse:列表反转,该方法返回None,但是会对列表的元素进行反向排序。

2.sort:函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。


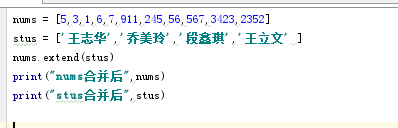
8.两个list合并:extend

9.布尔类型:布尔类型只有Ture,False,常用于真假判断。
判断一个元素在不在list里,可以用in:


10.list循环:
1.普通循环:如果直接循环一个list,那么每次取的就是list里面的每一个元素

2.enumerate:同时取到列表的下标和值


11.多维数组:列表嵌套
需要一层层的定位到要操作的维数,其他所有的方法同一维一样。
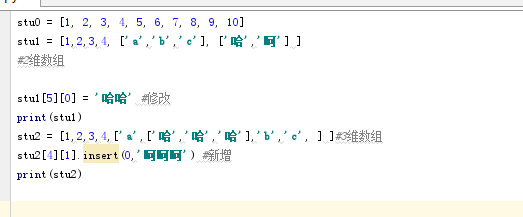

12.切片:list取值的一种方式,它指定范围取值,顾头不顾尾,可以指定步长(以N为整体作为一个跨度),数值可以为负数,但是指定的值都要在list范围内,不然会报错。
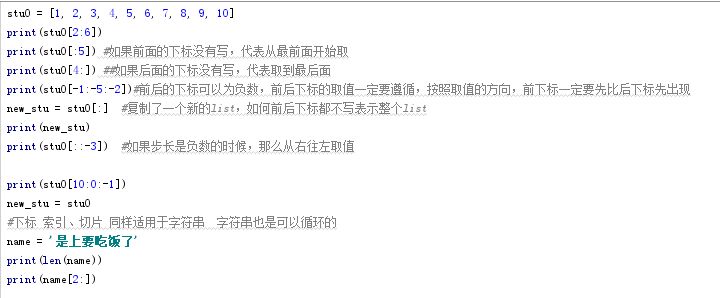
按照取值的方向,前下标一定要先比后下标先出现,否则取不到正确的值:
二.字典(dict):
字典是一个大括号括起来的key-value形式,与list不同的是,dict是无序的,即每次打印可能看到值得顺序都不一样;dict里的key是
唯一的不允许重复,而list里的值是可以重复的。因此dict的查询比list快,因为无序遍历。
1.查询:
直接通过key获取值,和列表取值方式一样,但是如果key的值不存在会报错:
为了防止key不存在产生的报错,使用get查询,如果key不存在,get默认返回None,也可以指定当key不存在时的返回值。
2.修改:
和list一样,通过key直接赋值。
3.新增:
同修改一样,直接用key赋值,由于同修改一样,所以当key如果是已存在的,则会进行修改操作:
为了避免上述的新增变修改,可以使用setdefault,用setdefault新增一个已经存在的key,它不会改变原来key的value。
4.删除:
1.pop:返回删除的value值,与list不同的是必须制定key值。
2.del:无返回值,解除引用,作用整个dict的时候,dict则不再存在,同list。
3.clear():清空,只会清除内容,但是保留变量引用。
4.popitem():随机删除一个非空dict的key-value,且将删除的这个值返回。
5.循环:
1.直接循环:效率高,不需要将dict转换成list,遍历取的是dict里的key值。
2.间接取key循环:dict.keys()效率低,会先从dict将所有的key取出来组成一个list再进行for遍历。







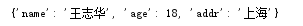



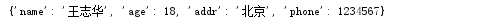

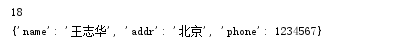

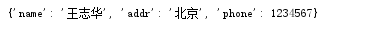








3.value循环:dict.values()该方法也会先从dict将所有的value取出来组成一个list再进行for遍历。


4.key,value循环:dict.items()该方法会将dict的key-value以元组的形式组合成一个一位数组再进行遍历。


6.判断key是否存在:in


7.字典嵌套:
字典嵌套也是层层定位。
如有以下字典:


结果如下:

三.字符串:
下标 索引、切片 同样适用于字符串,字符串也是可以循环的。
以下是字符串的常用方法介绍:
1.strip:以指定方式去掉字符串两边的内容,字符串中间的不可以去除。不带参数默认是去掉空格和换行符。

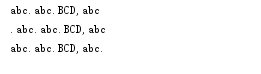
2.count:某个字符串出现的次数。如果没有出现,则次数为0。


3.index:找某个字符串下标,如果有多个,则返回第一次出现的下标。如果查找的字符串不存的话,报错(和list一样)。


4.find:找某个字符串下标,如果有多个,则返回第一次出现的下标。查找的字符串不存在会返回-1。与index的区别在于找不到不会报错。


5.replace:将字符串中的字符指定替换。可以设定替换的个数,默认为全部替换。替换之后不会改变原有的字符串,会返回一个新的字符串。


6.upper:将字符串中的小写字母转为大写字母。替换之后不会改变原有的字符串,会返回一个新的字符串。


7.lower:将字符串中的大写字母转为小写字母。替换之后不会改变原有的字符串,会返回一个新的字符串。


8.capitalize:将字符串中的首字母大写。执行后不会改变原有的字符串,会返回一个新的字符串。


9.startswith:判断是否以某个字符串开头。


10.endswith:判断是否以某个字符串结尾。用于文件后缀名很方便。


11.islower:判断是否都是小写字母。


12.isupper:判断是否都是大写字母。


13.isdigit:判断是否为纯数字。


14.center:将字符串居中显示,长度指定,不足的地方以指定模式补齐,执行后不会改变原有的字符串,会返回一个新的字符串。


15.isalpha:判断是不是为字母、或者汉字,不能有数字和特殊符号。


16.isalnum:字符串里面只要没有特殊字符,就返回true。


17.isidentifier:是不是一个合法的变量名。


18.isspace:检测字符串是否只由空格组成。


19.format:一种格式化字符串的函数,基本语法是通过 {} 和 : 来代替以前的 % 。方便的是当占位符太多时,可以忽略占位符的顺序。SQL语句常用。
例如没有格式化之前,语句:
s='insert into user value (%s,%s,%s,%s,%s,%s)'%(user,paswd,)
格式化的方法为:

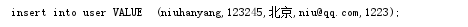
20.format_map:执行字符串格式化操作,替换字段使用{}分隔,同str.format(**mapping), 除了直接使用mapping,而不复制到一个dict。和format相比,需要将要输入的参数以dict的形式直接映射。SQL语句常用。

结果如下:

21.zfill:不够的位数以0补齐。位数如果够了则忽略。


22.split:将字符串以指定形式分隔后以list形式返回。默认以空格符分隔。


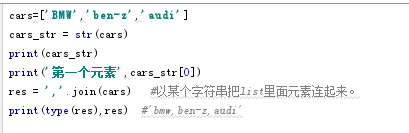
23.join:以某个字符串把list里面元素连起来,以字符串的形式返回。操作对象必须是个list。

四.简单的文件操作:
1.文件的四种操作:
1.open:打开文件,必须存在在才可以读。
2.close:关闭文件。
3.read:读文件。
4.write:写文件。
2.文件的模式:
1.r 打开只读文件,该文件必须存在。
2.r+ 打开可读写的文件,该文件必须存在。从顶部开始写,会覆盖之前此位置的内容
3.w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
4.w+ 打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
5.a 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留。
6.a+ 以附加方式打开可读写的文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾后,即文件原先的内容会被保留。
7.上述的形态字符串都可以再加一个b字符,如rb、w+b或ab+等组合,加入b 字符用来告诉函数库打开的文件为二进制文件,而非纯文字文件。不过在POSIX系统,包含Linux都会忽略该字符。