论文:
引入论文中的一句话来说明对比图像patches的重要性,“Comparing patches across images is probably one of the most fundamental tasks in computer vision and image analysis”.
同一个patch在不同图像中,由于光照、视角、阴影、遮挡、相机设置等因素的影响,这个patch在不同图像中往往呈现出不同的appearance。如何在存在各种外界影响的情况下,还能够准备判断它们是一个patch是一个挑战。传统手工设计的特征,如SIFT等,难以捕获同一个patch因各种因素导致的appearance不同。此时,考虑到CNN具有极强大表达能力(可以理解为,能够模拟任意复杂情形),因此将其引入到patches对比是很自然的一间事情。作者在本文中追求的目标是,直接学习得到一个通用的“similarity function for image patches”,从数据中直接学习一个图像块相似性函数,能隐含学习去除各种图像块表象的变化影响,得到有利于图像块匹配的特征。也就是说,提取到可以适应图像光照、角度等的变化的特征;示意图如下:
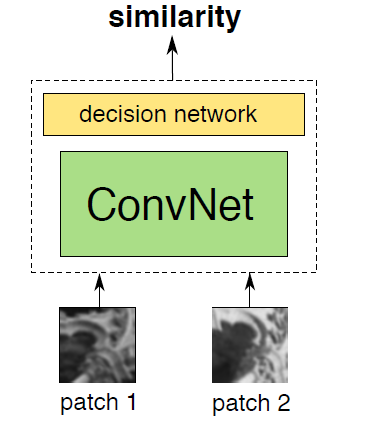
目标确定之后,有以下两个问题需要解决:数据、网络结构(采用CNN一般要解决的两个问题)。
(1) 数据
有标准的benchmark dataset: Yosemite、Notre Dame, and Liberty。此外,我们也可以采用软件生成一些patch对。当然也可以采用深度学习常用的数据增强方式进行数据扩充,本文用到的数据扩充方法:水平、垂直翻转,旋转90、180、270度。
(2)网络结构
我们的输入是两个patch,输出是两个patch的匹配相似度。这是不是很像分类问题呢?作者在本文中就是将这个问题当做分类问题来理解的,他选择Loss函数是(Hinge-based loss term and squared l2-norm regularization)。第一项为正则项,第二项yi是label(匹配为1、不匹配为-1),oi为网络的输出。

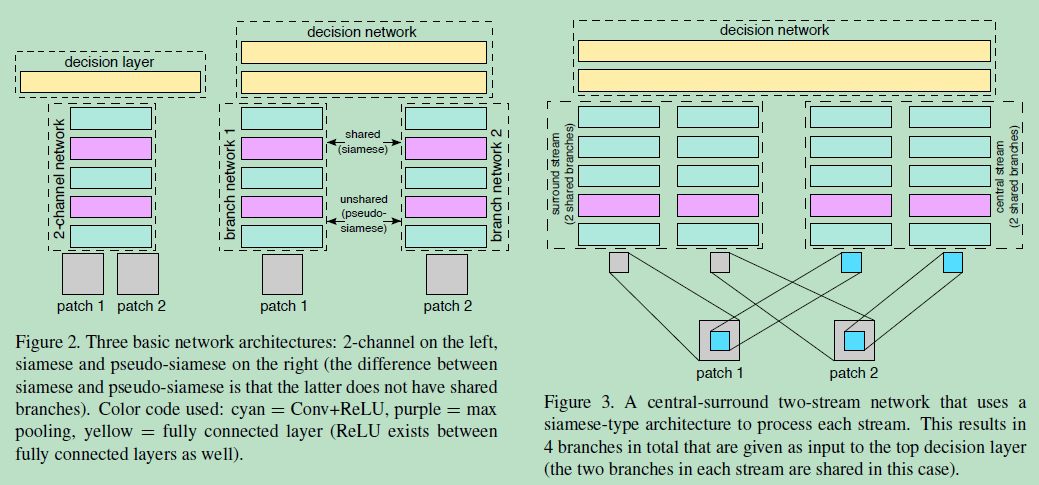
从左到右:2-channel (因为联合处理两个patches,更flexible,训练更快。但是test时间很长,brute-force manner),siamese and pseudo-siamese(孪生网络的可以共享Siamese,也可以不共享pseudo Siamese,不共享参数的训练参数多,训练时间长,但是测试效果和共享参数差不多),
还可以分别提取两个输入patch的中心,降采样后的“patches”作为输入(这样相当于增强了patch中心对最后结果的影响)。优点:多分辨率的信息有助于帮助image matching。在两个分流中都考虑到了patch的中间部分,将更多重心放心central part,减小周边像素的影响,有助于image matching。同时将维度减小一般,有助于提升训练的速度。
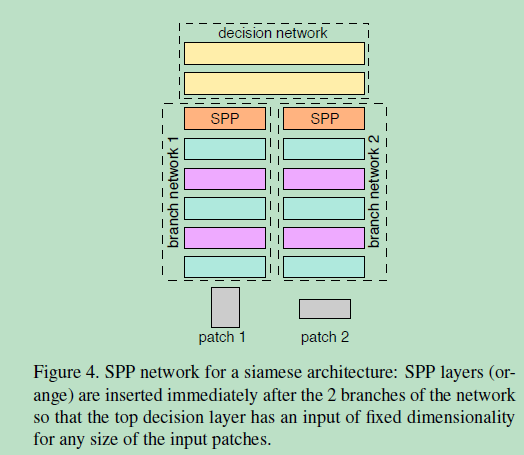
两个patch的sizes不想同怎么办呢?别担心,还有办法,就是通过在cnn的最上层引入SPP(spatial pyramid pooling),SPP网络就是在卷积层和全连接层中插入SPP层,SPP层的池化区域大小取决于输入的大小。这样能够使得即使输入patches的sizes不同,输出的sizes是相同的,解决了深度网络全连接层输入维度必须固定的问题,如下图所示
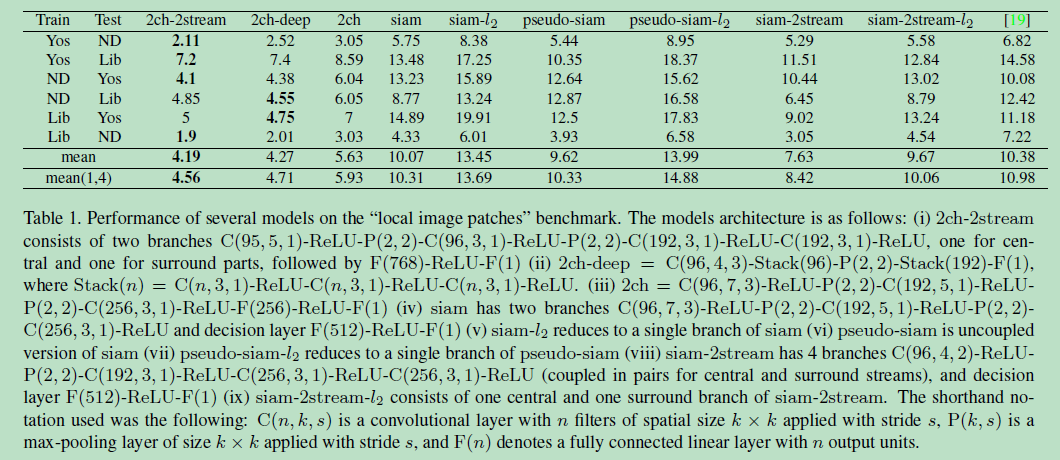
结论:
1) 两个patches作为网络输入的两个通道,这样能够给网络更大的自由度去捕获两个patches相似的本质因素,因此在网络的第一层就开始联合使用both patches的信息是有必要的。它的缺点是,在测试时,如果要判断每一个patch与另外所有patches是否相似(假如有N个patches),则每一对patches都需要经过同样的计算(深度网络计算时间较长,一共要做N^2次计算)。
2)采用孪生网络的形式,虽然网络的灵活性降低了,但是在测试的时候,我们可以先提取所有patch的卷积层输出,然后使用后续全连接进行对比。这样深度网络卷积部分只进行了N次计算。
3)2ch-2stream网络优于2ch-deep优于2ch,因此多分辨率信息及增加网络深度有助于匹配效果; pseudo-siamese网络优于siamese网络。
4)抛开image patches的概念,这篇论文概括了深度网络多输入的两种形式,即输入作为一个整体(多通道形式)、输入分拆(每一输入对应一个单独的网络)。
5)在我们选定框架之后,下面的问题就是选取具体的网络结构、数据增强方式、网络初始化方式以及它们对应参数的选取。
参考文献:
https://www.cnblogs.com/everyday-haoguo/p/Note-PCNN.html
https://blog.csdn.net/u011937018/article/details/79679199