一、概述
本文意在跟大家分享一些开发过程中遇到的常见Mysql问题和sql的优化技巧,有兴趣的朋友可以留言一起探讨进步。
二、Mysql常见优化技巧
1.使用联合(union)来代替手动创建的临时表
- MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。
2.优化查询语句方法
- 在建有索引的字段上尽量不要使用函数进行操作,如在一个DATE类型的字段上使用YEAR()函数时会花费更长时间(因为会使索引不生效),如下:
select * from users where YEAR(`created_at`) > 2019; //会进行全表扫描
改成以下命令可以合理使用索引: select * from users where `created_at` > '2019-01-01’;
- explain select * from `order_exts_3` where `attr_name` like “%base_%”; 和
explain select * from `order_exts_3` where `attr_name` > "base_" and `attr_name` < "base_z”; 为什么一样? 因为字符索引是逐个查询
- explain select * from `lfq_config` where `attr` > "sms_action_" and `attr` < "sms_action_9”; 和
explain select * from `lfq_config` where `attr` like "sms_action_%”; 为什么一样?
因为字符索引是逐个查询,但是如果是%sms_action,则该语句没有走索引
3.对于多张大数据量的表JOIN,要先分页再JOIN,否则逻辑读会很高,性能很差
- 如果要用,一般是放到一个搜索引擎里面搜数据(如:opensearch)
4.优化字段设计
- 数字型比字符串型索引更高效、查询更快、占用空间更小
- 优先使用enum或set,(需要注意的是enum一旦确定,最好不要修改,否则当数据量大时,会锁表较久)
- 避免使用null字段、text、blob,不在数据库里面存图片
5.合理使用索引
- 索引个数最好不超过字段数20%
- 不在索引列使用数学运算或者函数运算,如where id+1 = 10; 改成 where id = 10 -1;
- 外键的使用会有额外开销,高并发时容易死锁
6.sql语句设计
- 尽量拆成简单sql,简单sql缓存命中率更高,一条sql只能在一个cpu运算,减少锁表时间
- 保持事务/DB连接短小,即用即连,尽可能少使用存储过程、触发器
- 减少使用sql函数对结果进行处理,多个字段时,将or改成union
- 避免负向查询,如不使用!=、<>、not in
- sql最终都会转化为同数据类型的列值进行比较,因为sql有隐式转换
7.在数据量较大时,需要考虑可能出现的查询条件组合是否会导致慢查询等问题
- 如:订单表,根据updated_at条件进行数据查询,但是根据created_at进行排序,这样当updated_at的顺序跟created_at时间差异较大的话,会导致明显的查询变慢
8.查询缓存
- 定义:查询缓存为sql文本和查询结果的映射,如果第二次查询的sql和第一次查询的sql完全相同且开启了查询缓存,则第二次查询就直接从查询缓存中取结果
- show variables like “%query_cache%”
三、索引专辑
1.原理
- Innodb一般是使用B+树作为查询,索引的值一般是放在叶子节点(如果是非主键索引,则叶子节点的内容还会包括主键的值)
2.索引类型
- 聚簇索引:主键索引,不是单独的索引类型,是一种数据存储方式,在InnoDB中,表数据文件本身就是按B+Tree组织一个索引结构,这棵树的data域保存了完整的数据记录。
- 非聚簇索引:相对于聚簇索引来说,又称为辅助索引或者二级索引,InnoDb的二级索引data域存储的是主键的值,而不是数据
3.回表
- 定义:回表指通过索引查到主键索引后,再次根据主键索引查询数据表的具体记录。
- 主要应用场景:当根据某个非主键索引查询某个非索引字段时,mysql是先根据索引查询出主键索引,然后根据主键索引查处记录所在位置,从而获取到数据。(也就是说会有两次查询,第二次查询就是我们所谓的回表操作)
四、sql专辑
1.having子句
- sql会在分组之前计算where子句,在分组之后计算having子句
- 如:select user_id,count(*) as num from `orders` group by user_id having num > 10;
2.判断子句case when then
- 多条件判断,属于select子句,case函数只返回第一个符合条件的值,剩下的case部分将会被自动忽略
- 如:select case when age > 55 then 老人 when age > 20 then 中年 else 少年 end
3.if 条件语句
- if(expression, true, false)
- 如:select *,if (book_name=‘java’, ‘已卖完’, ‘有货’) as product_status from book where price = 50
4.聚合函数
- select count(case when age > 18 then id end) as num from users;
5.子查询
6.按时间分组
- DATE_FORMAT(date, format)函数
- 如:select count(1) as num,DATE_FORMAT(created_at, "%Y-%m-%d %H:%i:00") as cr_time from orders where `created_at` > '2019-11-01 13:00' and status = 10 group by cr_time order by cr_time desc
7.把查询内容当成一个表进行连表查询
- select * from (select id, count(1) as a from B group by a order by a desc) as temp, article where temp.id = article.b_id;
五、binLog、redoLog和undoLog
1.binLog
- 定义:记录所有数据库表结构变更及数据变更的二进制日志
2.redoLog
- 将事务中操作的数据(记录的是最新的数据),备份到一个地方,通常是物理日志,记录的是数据页的物理修改
3.undoLog
- 在操作任何数据之前,将需要操作的数据备份到一个地方,用于在事务期间别的查询使用, 一般是逻辑日志
PS:redoLog和undoLog都是事务日志(用于保证事务的一致性)
六、基础架构
1.架构流程图
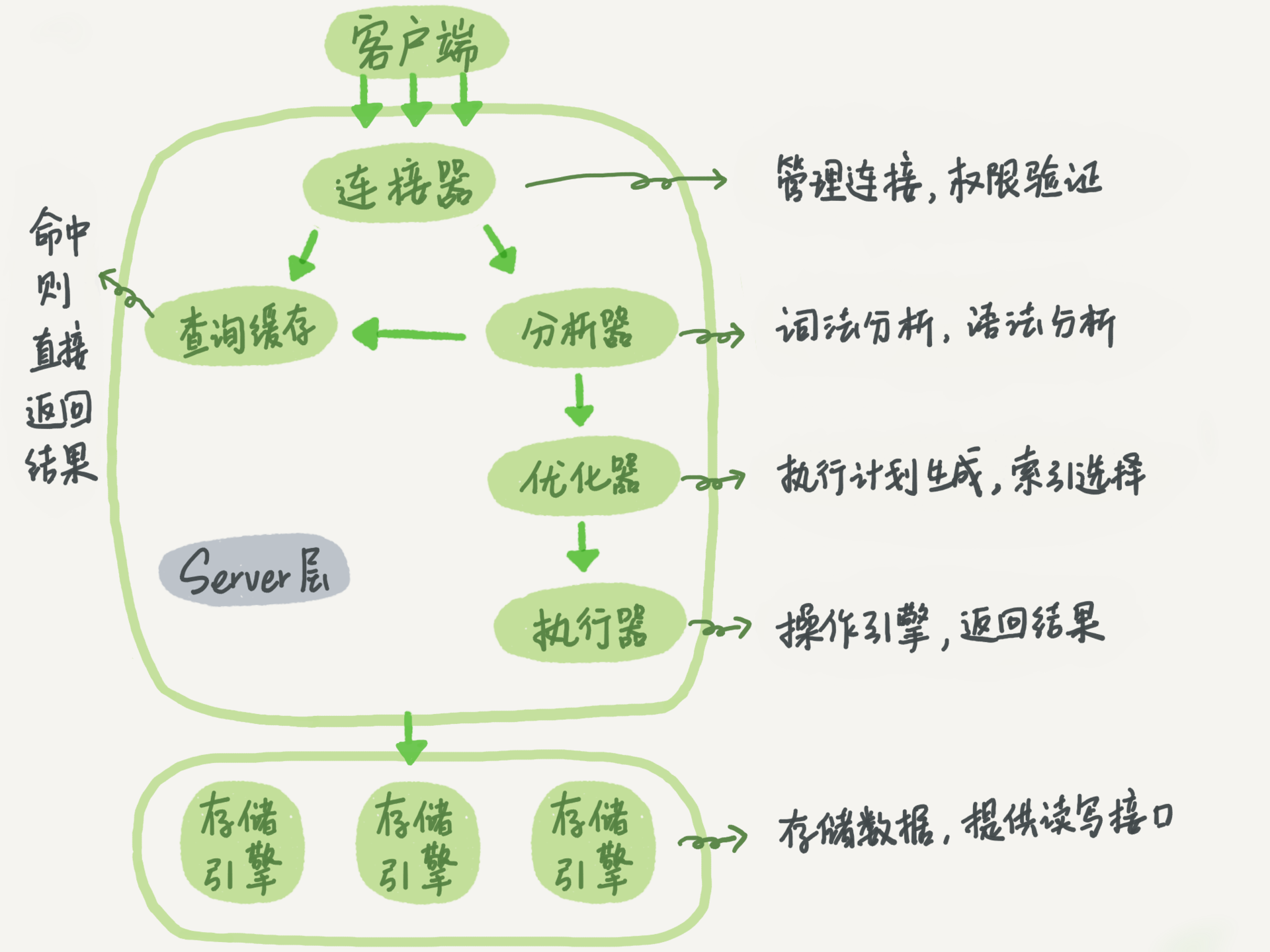
2.流程说明
1)基础架构:
server层:连接器->分析器->优化器->执行器
引擎层:innodb(默认)、mysiam、Memory
2)连接器:负责跟客户端建立连接、获取权限、维持和管理连接
注意点1:修改权限后,只有在新建的连接才会使用新的权限设置
注意点2:如果连接太久没操作连接器就会自动将它断开,wait_timeout 控制的,默认值是 8 小时。一些常驻脚本需要对这种情况做兼容
注意点3:如果全部使用长连接MySQL 占用内存涨得特别快,可能被OOM,MySQL在执行过程中临时使用的内存是管理在连接对象里面的
定期断开长连接,mysql_reset_connection
注意点4:查询缓存往往利大于弊,只要对表有更新,表上的查询缓存都会被清空,
query_cache_type 设置成 DEMAND,指定需要查询缓存是才使用。select SQL_CACHE * from T where id=1;
3)分析器:词法分析、语法分析。You have an error in your SQL syntax
4)优化器:优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序
5)执行器:调用引擎接口,执行计划、binlog
问题讨论
1.count(*) vs count(col) vs count(1)
- count(col),如果col是允许为null,则该命令会搜索全表,然后忽略字段为null的记录
- 执行效率:count(主键) > count(1) > count(col),count(*)mysql有底层优化,所以如果有主键索引的时候,count(*)和count(主键差不多)
参考文章:
1.临时表使用场景:http://www.sohu.com/a/283283740_120047065
2.explain命令详解:https://blog.csdn.net/UFO___/article/details/80951869
3.sql常见优化技巧:https://www.cnblogs.com/ka-bu-qi-nuo/p/7396647.html
4.事物日志介绍: