1 介绍
1.1 概念
面向批处理的分布式计算框架
一种编程模型:MapReduce程序被分为Map(映射)阶段和Reduce(化简)阶段
1.2 核心思想
分而治之,并行计算
移动计算,而非移动数据
1.3 特点
计算跟着数据走
良好的扩展性:计算能力随着节点数增加,近似线性递增
高容错
状态监控
适合海量数据的离线批处理
降低了分布式编程的门槛
1.4 适用场景
数据统计,如:网站的PV、UV统计
搜索引擎构建索引
海量数据查询
复杂数据分析算法实现
不适用场景
OLAP——要求毫秒或秒级返回结果
流计算——流计算的输入数据集是动态的,而MapReduce是静态的
DAG计算——多个作业存在依赖关系,后一个的输入是前一个的输出,构成有向无环图DAG;
每个MapReduce作业的输出结果都会落盘,造成大量磁盘IO,导致性能非常低下
2 MR原理
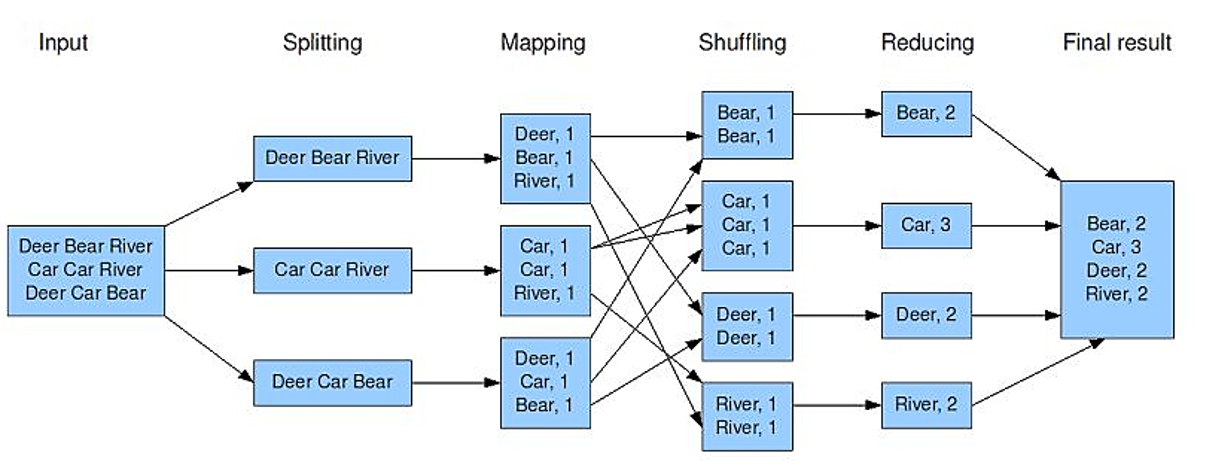
wordcount示例
2.1 基本概念
Job & Task(作业与任务)
作业是客户端请求执行的一个工作单元
包括输入数据、MapReduce程序、配置信息
任务是将作业分解后得到的细分工作单元
分为Map任务和Reduce任务
Split(切片)
输入数据被划分成等长的小数据块,称为输入切片(Input Split),简称切片
Split是逻辑概念,仅包含元数据信息,如:数据的起始位置、长度、所在节点等
每个Split交给一个Map任务处理,Split的数量决定Map任务的数量
Split的划分方式由程序设定,Split与HDFS Block没有严格的对应关系
Split的大小默认等于Block大小
Split越小,负载越均衡,但集群的开销越大
Map阶段(映射)
由若干Map任务组成,任务数量由Split数量决定
输入:Split切片(key-value),输出:中间计算结果(key-value)
Reduce阶段(化简)
由若干Reduce任务组成,任务数量由程序指定
输入:Map阶段输出的中间结果(key-value),输出:最终结果(key-value)
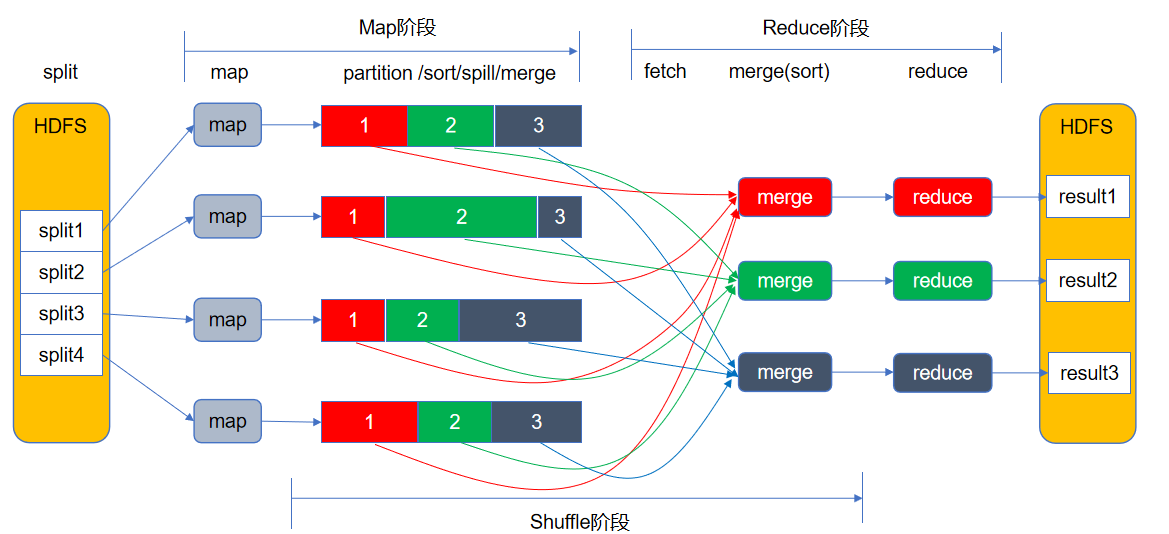
Shuffle阶段(洗牌)
Map、Reduce阶段的中间环节,负责执行Partition(分区)、Sort(排序)、Spill(溢写)、Merge(合并)、抓取(Fetch)等工作
Partition决定了Map任务输出的每条数据放入哪个分区,交给哪个Reduce任务处理
Reduce任务的数量决定了Partition数量
Partition编号 = Reduce任务编号 =“key hashcode % reduce task number”
避免和减少Shuffle是MapReduce程序调优的重点
2.2 程序执行过程
shuffle详解
Spark中的Spark Shuffle详解
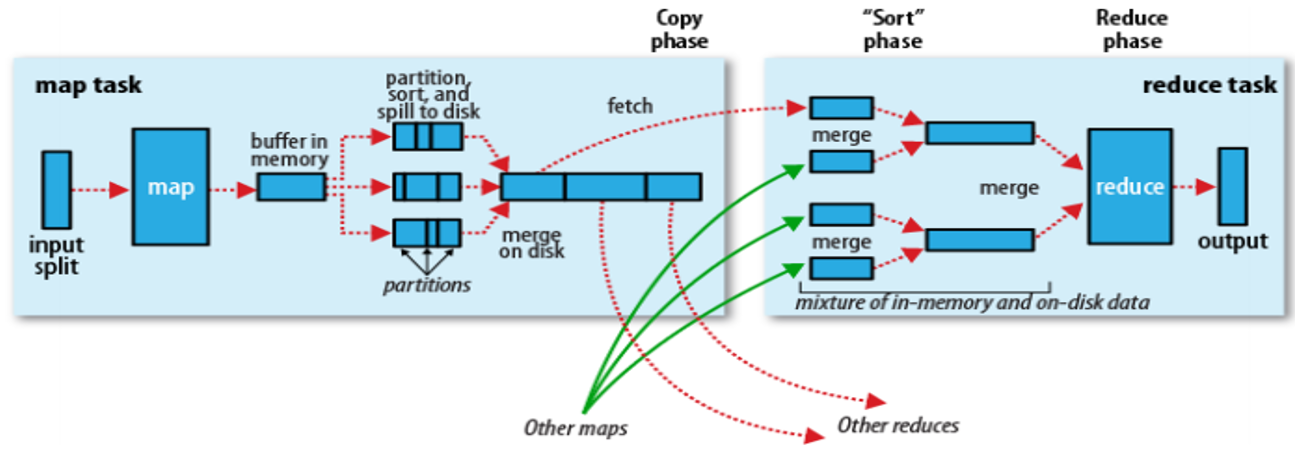
1)Map端
Map任务将中间结果写入专用内存缓冲区Buffer(默认100M),同时进行Partition和Sort(先按“key hashcode % reduce task number”对数据进行分区,分区内再按key排序)
当Buffer的数据量达到阈值(默认80%)时,将数据溢写(Spill)到磁盘的一个临时文件中,文件内数据先分区后排序
Map任务结束前,将多个临时文件合并(Merge)为一个Map输出文件,文件内数据先分区后排序
2)Reduce端
Reduce任务从多个Map输出文件中主动抓取(Fetch)属于自己的分区数据,先写入Buffer,数据量达到阈值后,溢写到磁盘的一个临时文件中
数据抓取完成后,将多个临时文件合并为一个Reduce输入文件,文件内数据按key排序
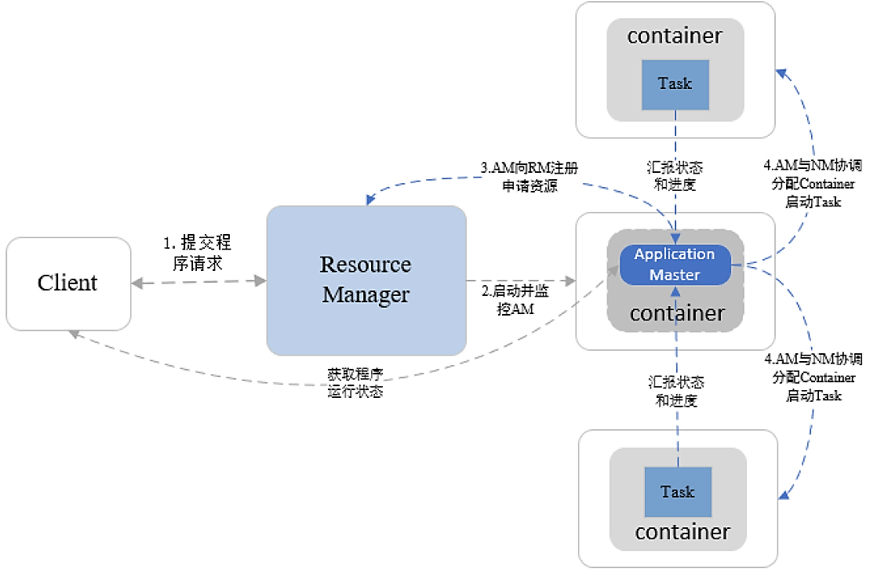
2.3 作业运行模式
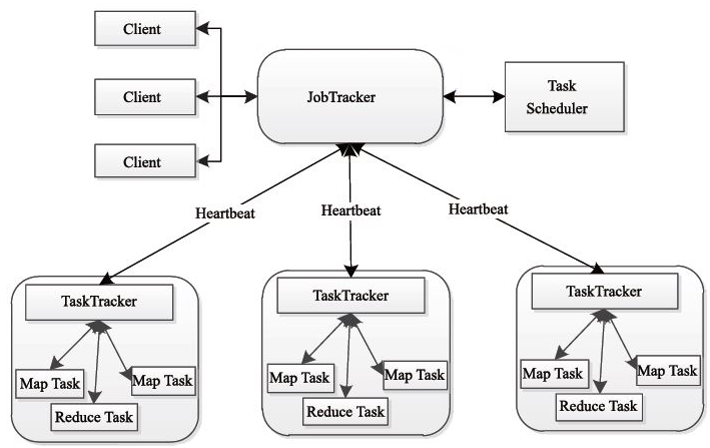
JobTracker/TaskTracker模式(Hadoop 1.X)
1)JobTracker节点(Master)
调度任务在TaskTracker上运行
若任务失败,指定新TaskTracker重新运行
2)TaskTracker节点(Slave)
执行任务,发送进度报告
3)存在的问题
JobTracker存在单点故障
JobTracker负载太重(上限4000节点)
JobTracker缺少对资源的全面管理
TaskTracker对资源的描述过于简单
源码很难理解
YARN模式( Hadoop 2.X )