原文地址:https://blog.csdn.net/antkillerfarm/article/details/77834124
CNN进化史
计算机视觉
6大关键技术:


图像分类:根据图像的主要内容进行分类。数据集:MNIST, CIFAR, ImageNet
物体定位:预测包含主要物体的图像区域,以便识别区域中的物体。数据集:ImageNet
物体识别:定位并分类图像中出现的所有物体。这一过程通常包括:划出区域然后对其中的物体进行分类。数据集:PASCAL, COCO
语义分割:把图像中的每一个像素分到其所属物体类别,在样例中如人类、绵羊和草地。数据集:PASCAL, COCO
实例分割:把图像中的每一个像素分到其所属物体实例。数据集:PASCAL, COCO
关键点检测:检测物体上一组预定义关键点的位置,例如人体上或者人脸上的关键点。数据集:COCO
CNN简史


AlexNet
2012年,ILSVRC比赛冠军的model——Alexnet(以第一作者Alex命名)的结构图如下:
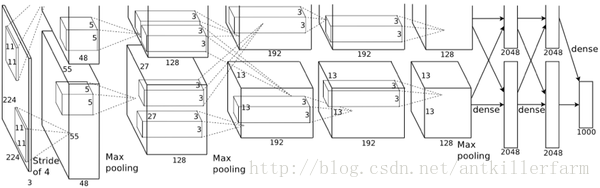
换个视角:
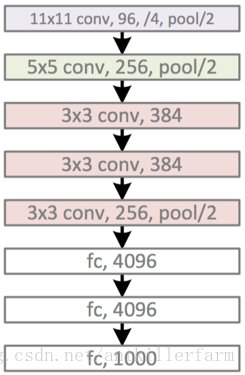
AlexNet的caffe模板:
https://github.com/BVLC/caffe/blob/master/models/bvlc_alexnet/deploy.prototxt
其中的LRN(Local Response Normalization)层也是当年的遗迹,被后来的实践证明,对于最终效果和运算量没有太大帮助,因此也就慢慢废弃了。
虽然,LeNet-5是CNN的开山之作(它不是最早的CNN,但却是奠定了现代CNN理论基础的模型),但是毕竟年代久远,和现代实用的CNN相比,结构实在过于原始。
AlexNet作为第一个现代意义上的CNN,它的意义主要包括:
1.Data Augmentation。包括水平翻转、随机裁剪、平移变换、颜色、光照变换等。
2.Dropout。
3.ReLU激活函数。
4.多GPU并行计算。
5.当然最应该感谢的是李飞飞团队搞出来的标注数据集合ImageNet。
注:ILSVRC(Large Scale Visual Recognition Challenge)大赛,在2016年以前,一直是CV界的顶级赛事。但随着技术的成熟,目前的科研重点已经从物体识别转移到了物体理解领域。2017年将是该赛事的最后一届。WebVision有望接替该赛事,成为下一个目标。
VGG
Visual Geometry Group是牛津大学的一个科研团队。他们推出的一系列深度模型,被称作VGG模型。
VGG的结构图如下:
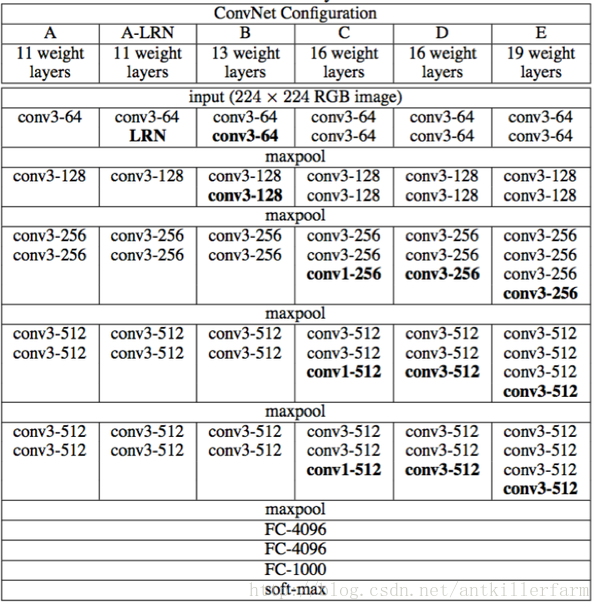
该系列包括A/A-LRN/B/C/D/E等6个不同的型号。其中的D/E,根据其神经网络的层数,也被称为VGG16/VGG19。
从原理角度,VGG相比AlexNet并没有太多的改进。其最主要的意义就是实践了“神经网络越深越好”的理念。也是自那时起,神经网络逐渐有了“深度学习”这个别名。
GoogleNet
GoogleNet的进化道路和VGG有所不同。VGG实际上就是“大力出奇迹”的暴力模型,其他地方不足称道。
而GoogleNet不仅继承了VGG“越深越好”的理念,对于网络结构本身也作了大胆的创新。可以对比的是,AlexNet有60M个参数,而GoogleNet只有4M个参数。
因此,在ILSVRC 2014大赛中,GoogleNet获得第一名,而VGG屈居第二。
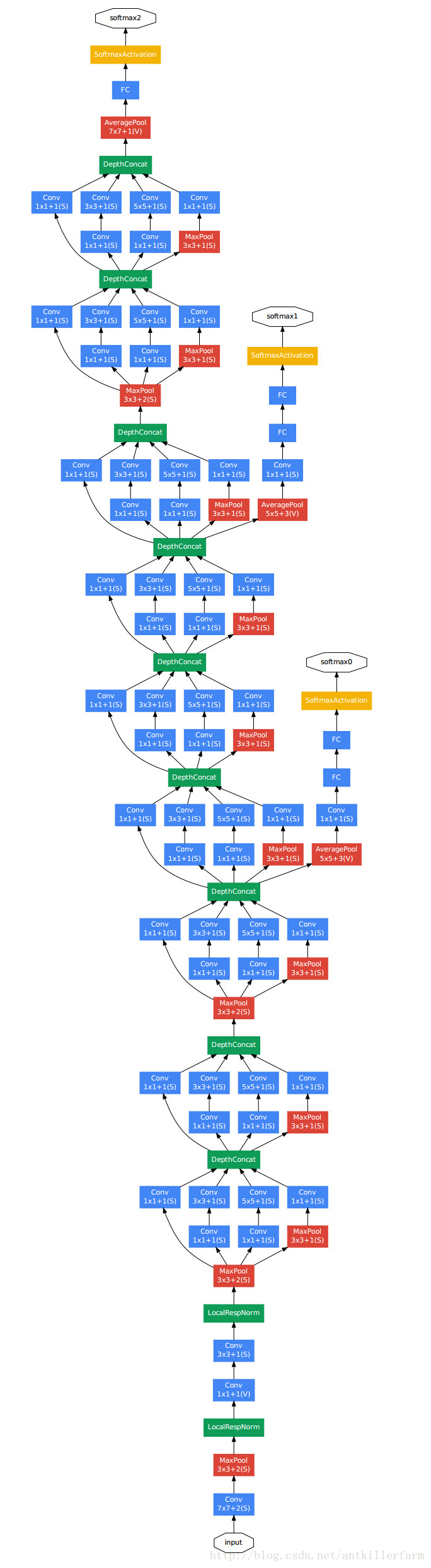
上图是GoogleNet的结构图。从中可以看出,GoogleNet除了AlexNet的基本要素之外,还有被称作Inception的结构。
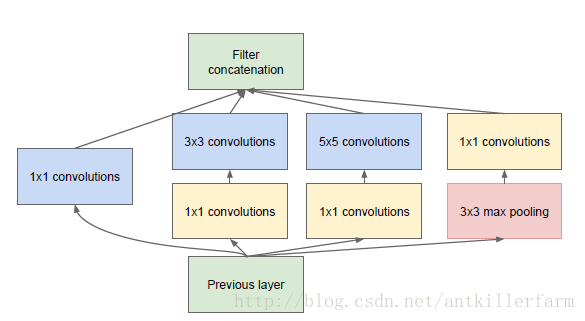
上图是Inception的结构图。它的原理实际上就是将不同尺寸的卷积组合起来,以提供不同尺寸的特征。
原始的GoogleNet也被称作Inception-v1。在后面的几年,GoogleNet还提出了几种改进的版本,最新的一个是Inception-v4(2016.8)。
论文:
《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》
Inception系列的改进方向基本都集中在构建不同的Inception模型上。
GoogleNet的另一个改进是减少了全连接层(Full Connection, FC),这是减少模型参数的一个重要改进。事实上,在稍后的实践中,人们发现去掉VGG的第一个FC层,对于效果几乎没有任何影响。
SqueezeNet
GoogleNet之后,最有名的CNN模型当属何恺明的Deep Residual Network。DRN在《深度学习(五)》中已有提及,这里不再赘述。
DRN之后,学界的研究重点,由如何提升精度,转变为如何用更少的参数和计算量来达到同样的精度。SqueezeNet就是其中的代表。
论文:
《SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size》
代码:
https://github.com/DeepScale/SqueezeNet
Caffe版本
https://github.com/vonclites/squeezenet
TensorFlow版本
SqueezeNet最大的创新点在于使用Fire Module替换大尺寸的卷积层。
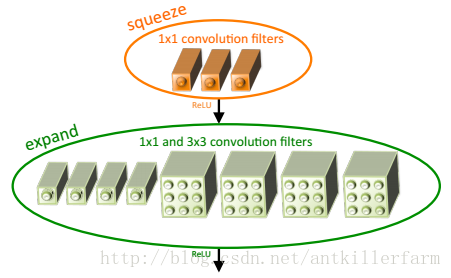
上图是Fire Module的结构示意图。它采用squeeze层+expand层两个小卷积层,替换了AlexNet的大尺寸卷积层。其中,Nsqueeze<NexpandNsqueeze<Nexpand,N表示每层的卷积个数。
这里需要特别指出的是:expand层采用了2种不同尺寸的卷积,这也是当前设计的一个趋势。
这个趋势在GoogleNet中已经有所体现,在ResNet中也间接隐含。
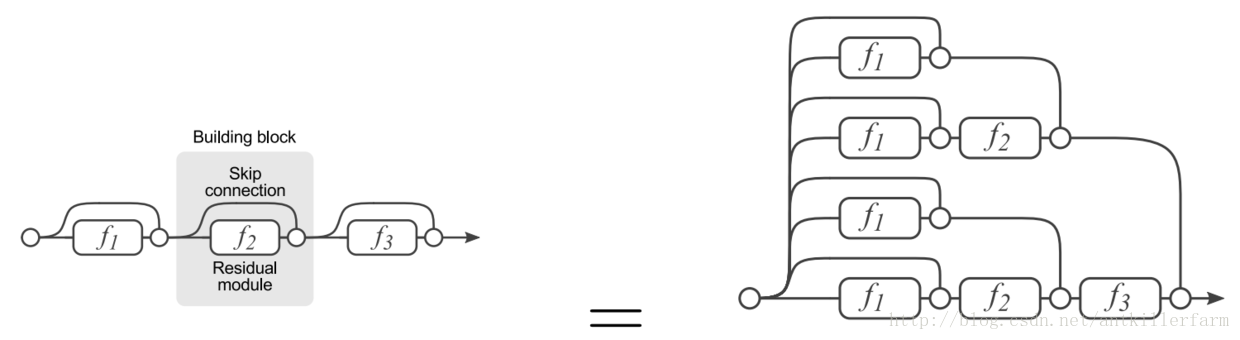
上图是ResNet的展开图,可见展开之后的ResNet,实际上等效于一个多尺寸交错混编的复杂卷积网。其思路和GoogleNet实际上是一致的。
参见:
http://blog.csdn.net/xbinworld/article/details/50897870
最新SqueezeNet模型详解,CNN模型参数降低50倍,压缩461倍!
http://www.jianshu.com/p/8e269451795d
神经网络瘦身:SqueezeNet
http://blog.csdn.net/shenxiaolu1984/article/details/51444525
超轻量级网络SqueezeNet算法详解
参考
http://mp.weixin.qq.com/s/ZKMi4gRfDRcTxzKlTQb-Mw
计算机视觉识别简史:从AlexNet、ResNet到Mask RCNN
http://mp.weixin.qq.com/s/kbHzA3h-CfTRcnkViY37MQ
详解CNN五大经典模型:Lenet,Alexnet,Googlenet,VGG,DRL
https://zhuanlan.zhihu.com/p/22094600
Deep Learning回顾之LeNet、AlexNet、GoogLeNet、VGG、ResNet
http://www.leiphone.com/news/201609/303vE8MIwFC7E3DB.html
Google最新开源Inception-ResNet-v2,借助残差网络进一步提升图像分类水准
https://mp.weixin.qq.com/s/x3bSu9ecl3dldCbvS1rT1g
站在巨人的肩膀上,深度学习的9篇开山之作
http://mp.weixin.qq.com/s/2TUw_2d36uFAiJTkvaaqpA
解读Keras在ImageNet中的应用:详解5种主要的图像识别模型
https://zhuanlan.zhihu.com/p/27642620
YJango的卷积神经网络——介绍
https://www.zybuluo.com/coolwyj/note/202469
ImageNet Classification with Deep Convolutional Neural Networks
http://simtalk.cn/2016/09/20/AlexNet/
AlexNet简介
http://simtalk.cn/2016/09/12/CNNs/
CNN简介
http://www.cnblogs.com/Allen-rg/p/5833919.html
GoogLeNet学习心得
https://mp.weixin.qq.com/s/I94gGXXW_eE5hSHIBOsJFQ
无需数学背景,读懂ResNet、Inception和Xception三大变革性架构
https://mp.weixin.qq.com/s/iN2LDAQ2ee-rQnlD3N1yaw
变形卷积核、可分离卷积?CNN中十大拍案叫绝的操作!
https://mp.weixin.qq.com/s/ToogpkDo-DpQaSoRoalnPg
没看过这5个模型,不要说你玩过CNN!
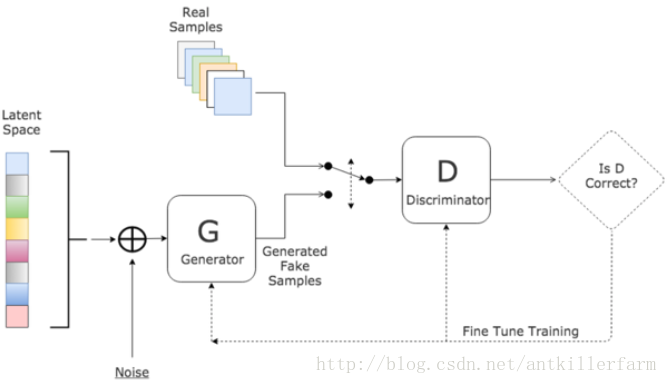
GAN
概况
GAN是“生成对抗网络”(Generative Adversarial Networks)的简称,由2014年还在蒙特利尔读博士的Ian Goodfellow引入深度学习领域。
注:Ian J. Goodfellow,斯坦福大学本硕+蒙特利尔大学博士。导师是Yoshua Bengio。现为Google研究员。
个人主页:
http://www.iangoodfellow.com/
论文:
《Generative Adversarial Nets》
教程:
http://www.iangoodfellow.com/slides/2016-12-04-NIPS.pdf
通俗解释
对于GAN来说,最通俗的解释就是“伪造者-鉴别者”的解释,如艺术画的伪造者和鉴别者。一开始伪造者和鉴别者的水平都不高,但是鉴别者还是比较容易鉴别出伪造者伪造出来的艺术画。但随着伪造者对伪造技术的学习后,其伪造的艺术画会让鉴别者识别错误;或者随着鉴别者对鉴别技术的学习后,能够很简单的鉴别出伪造者伪造的艺术画。这是一个双方不断学习技术,以达到最高的伪造和鉴别水平的过程。
从上面的解释可以看出,GAN实际上一种零和游戏上的无监督算法。