《实验一:机器是怎样工作的?——实验报告》
姓名:方超
学号:SA*****201
试验目标:请使用Example的c代码分别生成.cpp,.s,.o和ELF可执行文件,并加载运行,分析.s汇编代码在CPU上的执行过程。并通过实验解释单任务计算机是怎样工作的,并在此基础上讨论分析多任务计算机是怎样工作的。
试验环境:Ubuntu 13.04, GCC 4.7.3, GDB 7.5.91.20130417, GDB图形前端: DDD
试验内容:
1.编写example.c代码
1 int g(int x) 2 { 3 return x + 3; 4 } 5 6 int f(int x) 7 { 8 return g(x); 9 } 10 11 int main(void) 12 { 13 return f(8) + 1; 14 }
2.将example.c源文件生成cpp, s, o, ELF可执行程序。
1) 执行"gcc -E example.c -o example.cpp"命令生成.cpp文件。

2) 执行"gcc -S example.cpp -o example.s"命令生成.s文件。

3) 执行"gcc -c example.s -o example.o"命令生成.o文件。

4) 执行"gcc example.o -o example"命令生成elf格式的可执行文件。

至此,文件生成完毕。
3.分析汇编代码的执行过程。
1) 打开DDD程序,将生成的example程序载入(File->Open program),之后可以看到如下画面。

2) 在显示区可以通过插入显示命令来查看所需要的变量,寄存器,表达式,内存等等。本次试验需要查看所有寄存器的值以及栈内存信息。显示命令"`info reg`"来打印所有寄存器的值。`x /12xw 0xbffff160`命令来打印内存,其中0xbffff18c是程序执行时esp的值,也就是当前栈顶指针位置, 由于栈是向下增长的,所以需要以0xbffff160为起点,打印12个。

3) 分析main函数在跳转到f函数之前的活动。
栈活动如下图所示:
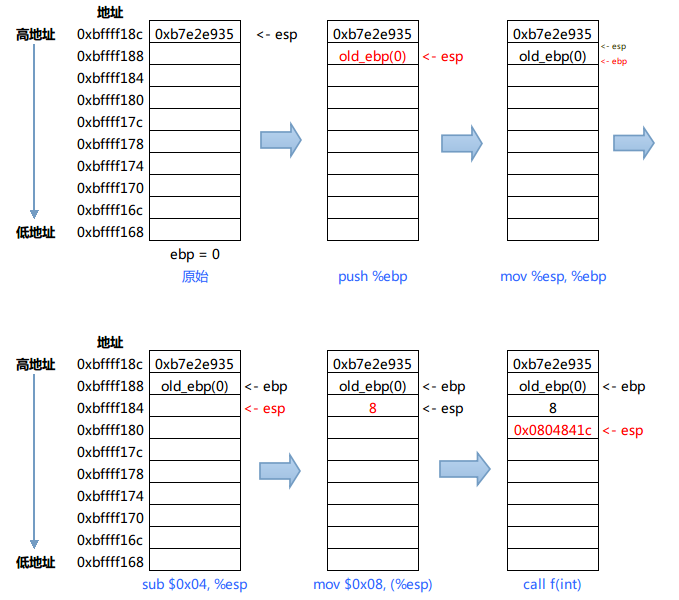
ddd中显示的栈信息也验证了分析的正确性。

4) 分析f函数在跳转到g函数之前的活动。

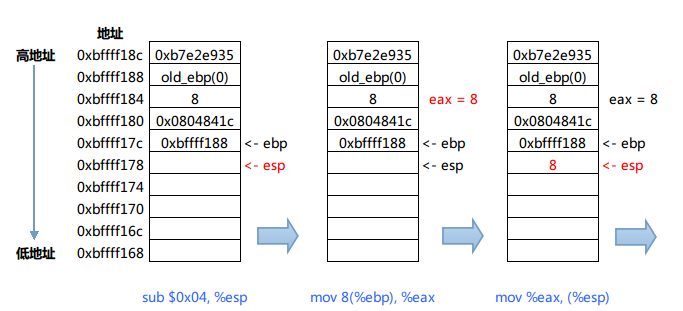

ddd中运行的结果。

5) 分析g函数的执行活动。


ddd运行的结果验证。

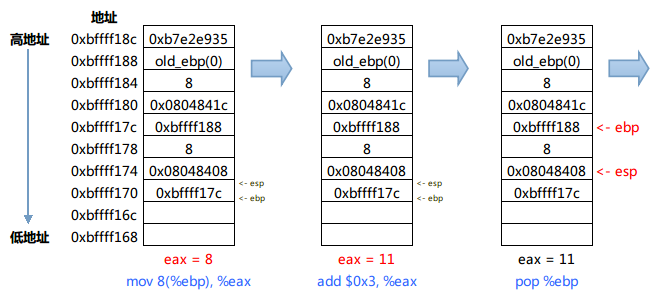
6) 分析f函数调用g函数之后的执行活动

ddd运行的结果。

7) 分析main函数调用f函数之后的执行活动

ddd运行的结果

至此,程序执行完毕,最终的结果保存在eax寄存器中。
4.单任务计算机工作原理。
暂且讨论最基本的单任务计算机,无中断,程序工作在线性地址空间中,不考虑MMU等等。
程序分为代码段,数据段,BSS段等等,其中代码段存放的是机器执行的指令,eip寄存器总是保存下一条即将执行的指令地址。数据段,BSS段存放全局变量,程序运行还需要一个程序栈的支持,该栈的增长方向是从高地址向低地址增长,栈中保存程序的局部变量,以及函数的返回地址等信息。跟踪程序的运行情况最主要的工作就是观察代码段以及程序栈的情况。
程序的运行是以函数为单位,每个函数都有自己的栈,ebp寄存器保存当前函数的栈底指针,esp寄存器保存当前函数的栈顶指针。程序运行的基本流程就是顺序执行当前函数的指令,在栈中操作局部变量,当遇到函数调用时,会执行call指令跳转到其他函数,当被调用的函数执行完毕后返回到当前函数中,并将返回值保存在eax寄存器中,然后机器接着执行函数调用指令之后的的下一条指令,那么机器是如何实现函数跳转以及相应的栈切换的呢?
正如前面example程序执行过程分析的那样,在即将要调用其他函数之前,需要将函数参数压入当前栈中,并且压栈的顺序和函数参数声明的顺序相反,例如函数f(a,b,c),那么压栈的顺序就是c->b->a,接着会有一条call指令,该指令会将紧接着call指令的下一条指令的地址(即返回地址)压入到程序栈中,eip被赋成call的操作数,cpu跳转到被调用函数的首地址处执行。
函数的起始两条指令分别是push %ebp, mov %ebp, %esp。这两条指令就是保存调用函数的栈底指针,同时将本函数的栈底指针设置成栈顶指针相同,这样就实现了函数的栈切换。在函数的最后一般都会有leave和ret这两条指令。leave相当于mov %ebp %esp, pop %ebp,这将调用函数的栈底指针取出并保存到ebp中,也就实现了调用函数栈底指针的恢复工作,这时esp指向的内存单元保存的就是返回地址,也就是调用函数执行call指令压入的地址。执行ret指令,就相当与执行pop %eip。将eip赋成返回地址的值,这样就实现了被调用函数返回到调用函数的功能。
由以上分析我们可以发现,其实各个函数的栈是根据调用顺序严格递减增长的,栈的创建与销毁非常紧凑,提高了内存的利用效率。
5.多任务计算机工作原理。
通过单任务计算机的工作原理的分析,我们可以知道只要内存中有该程序的各个程序段,并且有对应的程序栈支持就可以实现程序的运行,额外的,程序运行的一部分状态也保存在程序状态字寄存器中。类似函数调用之间的状态保存机制(栈底,返回地址等的保存机制)等,我们可以将各个任务想象成一个个被调用的函数,而调用这些函数的程序就是main函数,当调用一个任务时,我们将前一任务相关的执行信息(如栈顶,栈底指针,任务执行的断点,当前的程序状态字寄存器等等)保存起来,将即将调用的任务的执行信息恢复,那么就可以实现任务的切换。
这个main函数就是操作系统,各个被调用函数就是任务。操作系统的一个重要的功能就是进程管理。