这篇文章介绍了使用 Logstash 在 Elasticsearch中 对数据进行重复数据删除的方法。 根据你的用例,Elasticsearch中 的重复内容可能不被接受。 例如,如果你要处理指标,则 Elasticsearch中 的重复数据可能会导致错误的聚合和不必要的警报。 即使对于某些搜索用例,重复的数据也可能导致不良的分析和搜索结果。
背景:Elasticsearch 索引
在介绍重复数据删除解决方案之前,让我们简要介绍一下 Elasticsearch 的索引编制过程。 Elasticsearch 提供了一个 REST API 来为你的文档建立索引。你可以选择提供唯一代表您的文档的 ID,也可以让 Elasticsearch 为你生成ID。如果您将 HTTP PUT 与索引API 一起使用,Elasticsearch 希望您提供一个ID。如果已经存在具有相同 ID 的文档,Elasticsearch 将用你刚才提供的文档替换现有内容-最后索引的文档将获胜。如果使用 POST 动词,则即使语料库中已经存在内容,Elasticsearch 也会生成具有新ID的新文档。例如,假设你刚在一秒钟之前为博客文章建立了索引,并使用 POST 动词重新发送了同一篇博客文章,Elasticsearch 创建了另一个具有相同内容但新具有 ID 的文档。你可以参阅我之前的文章 “开始使用Elasticsearch (1)”以了解更多。
虽然 Elasticsearch 提供了一个显式的 _update API,可以将其用作潜在的解决方法,但我们将把本文重点放在索引 API 上。
Logstash 的 Elasticsearch 输出使用索引API,并且默认情况下不希望提供 ID。因此,它将每个单个事件视为单独的文档。但是,有一个选项可让你轻松为 Logstash 中的每个事件设置唯一的 ID。
定义你的 ID
如果你的数据源已经有一个ID,那么在索引到 Elasticsearch 之前很容易将其设置为文档ID。 例如,JDBC 输入的用户可以轻松地将源表中的主键用作 Elasticsearch ID。 使用字段引用语法,可以在输出部分中直接设置文档 ID:
output { elasticsearch { hosts => "example.com" document_id => "%{[upc_code]}" } }
其中 upc_code 是数据中的字段。 该字段可能来自结构化日志格式的字段,也可能是使用 grok 过滤器提取的。
删除重复的相似内容
如前所述,在你的用例中,重复的内容可能是不可接受的。使用称为指纹的概念和 Logstash 指纹过滤器(fingerprint),您可以创建一个称为指纹的新字符串字段,以唯一地标识原始事件。指纹过滤器可以将原始事件中的一个或多个字段(默认为消息字段)作为源来创建一致的哈希值 (hash)。一旦创建了这些指纹,你就可以将其用作下游Elasticsearch输出中的文档ID。这样,Elasticsearch 将仅在比较指纹后更新或覆盖现有文档内容,但绝不会复制它们。如果你想考虑更多字段以进行删除重复数据,则可以使用 concatenate_sources 选项。
指纹过滤器具有多种算法,您可以选择创建此一致的哈希(hash)。请参阅文档,因为每个函数的哈希强度不同,可能需要其他选项。在下面的示例中,我们使用 MURMUR3 方法从消息字段创建哈希并将其设置在元数据字段中。元数据字段不会发送到输出,因此它们提供了一种在处理管道中的事件时临时存储数据的有效方法。
filter { fingerprint { source => "message" target => "[@metadata][fingerprint]" method => "MURMUR3" } } output { elasticsearch { hosts => "example.com" document_id => "%{[@metadata][fingerprint]}" } }
如果使用任何加密哈希函数算法(例如SHA1,MD5),则需要提供密钥选项。 密钥可以是用于计算 HMAC 的任意字符串。
filter { fingerprint { source => "message" target => "[@metadata][fingerprint]" method => "SHA1", key => "Log analytics", base64encode => true } } output { elasticsearch { hosts => "example.com" document_id => "%{[@metadata][fingerprint]}" } }
密钥的其他示例可以是 departmentID,组织 ID 等。
意外重复:从 Logstash 生成 UUID
先前的用例涉及内容的有意识地删除重复数据。在某些部署中,尤其是 Logstash 与可确保至少交付一次的持久性队列或其他排队系统一起使用时,Elasticsearch 中可能存在重复项。如果 Logstash 在处理过程中崩溃,则重新启动时将重播队列中的数据-这可能导致重复。为了减少这种情况造成的重复,可以对每个事件使用 UUID。这里的重点是,在将数据序列化到消息队列之前,需要在生产方(即发布到排队系统的 Logstash 实例)上生成UUID。这样,Logstash使用者在从崩溃还原或重新启动时需要重新处理事件时,将保留相同的事件ID。
如果你的源数据没有唯一标识符,则可以使用同一指纹过滤器来生成 UUID。请记住,此方法不考虑事件本身的内容,而是为每个事件生成 version 4 UUID。
filter { fingerprint { target => "%{[@metadata][uuid]}" method => "UUID" } } output { elasticsearch { hosts => "example.com" document_id => "%{[@metadata][uuid]}" } }
如果在 Logstash 生产者和使用者之间使用队列,则必须显式复制@metadata字段,因为它们不会持久化到输出中。 另外,你可以使用以下常规字段:
filter { fingerprint { target => "generated_id" method => "UUID" } } output { kafka { brokers => "example.com" ... } }
从消费者方面,您可以只使用:
input { kafka { brokers => "example.com" } } output { elasticsearch { hosts => "example.com" document_id => "%{[generated_id]}" } }
例子
在下面,我们用一个实际的例子来展示,这个是如工作的。首先让我们先创建一个叫做 logstash_fingerprint.conf 的 Logstash 配置文件:
logstash_fingerprint.conf
input { http { id => "data_http_input" } } filter { fingerprint { source => [ "sensor_id", "date"] target => "[@metadata][fingerprint]" method => "SHA1" key => "liuxg" concatenate_sources => true base64encode => true } } output { stdout { codec => rubydebug } elasticsearch { manage_template => "false" index => "fingerprint" hosts => "localhost:9200" document_id => "%{[@metadata][fingerprint]}" } }
在这里,我们使用 http input 来收集数据。在这里,我们使用 sensor_id 及 date 这两个字段来生成一个 fingerprint。也就是说,只有这两个字段是一样的,那么无论我们输入多少次数据,那么在 Elasticsearch 中将不会有新的数据生成,因为它们的 ID 都是一样的。 我们启动 Logstash:
sudo ./bin/logstash -f ~/data/fingerprint/logstash_fingerprint.conf
我们可以在另外一个 console 中打入如下的命令:
curl -XPOST --header "Content-Type:application/json"http://localhost:8080/" -d '{"sensor_id":1, "date": "2015-01-01", "reading":16.24}'
这个时候,我们可以在 Logstash 的 console 中查看到:
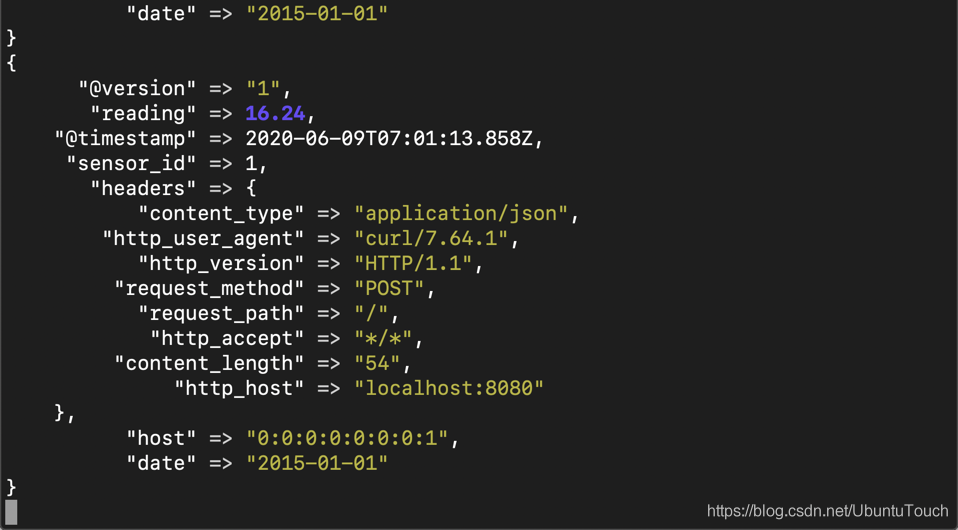
我们在 Kibana 的 Dev Tools 中进行查看:
GET _cat/indices
我们可以看到有一个新的 fingerprint 的索引已经生产了。
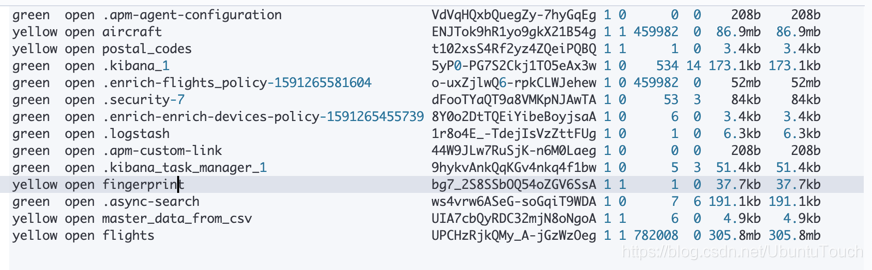
我们查看 fingerprint 的文档数:
GET fingerprint/_count
结果显示:
{ "count" : 1, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 } }
我们在另外一个 console 中打入无数次的如下的命令:
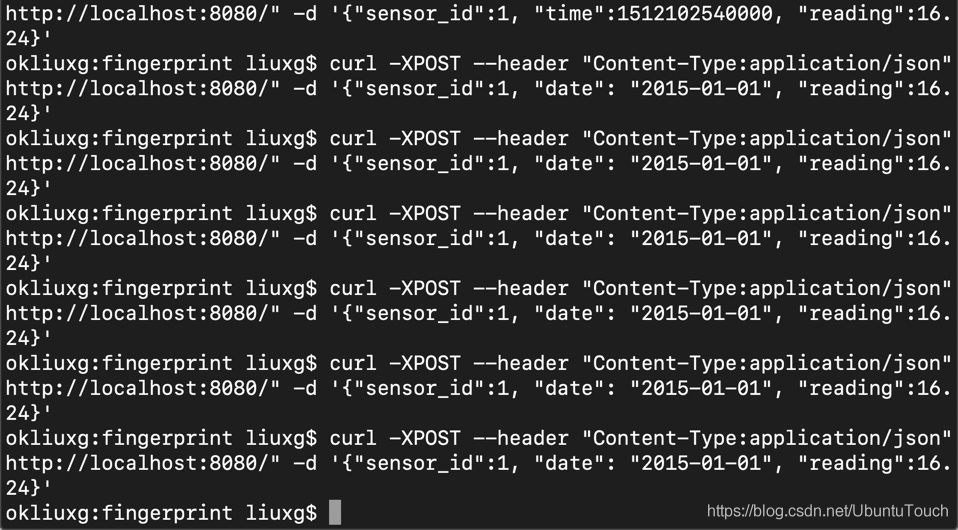
我们发现,只要是 sensor_id 和 date 的值都是一样的,那么 fingerprint 的文档数永远是 1。当然你也可以更新其它字段的值,比如 reading 字段的值为20,那么新的值将会在里面得以体现。这个操作相当于更新的操作。
如果我们改动一下 sensor_id 的值为2,也就是:
curl -XPOST --header "Content-Type:application/json"http://localhost:8080/" -d '{"sensor_id":2, "date": "2015-01-01", "reading":16.24}'
那么我们重新查看 fingerprint 索引的文档数:
GET fingerprint/_count
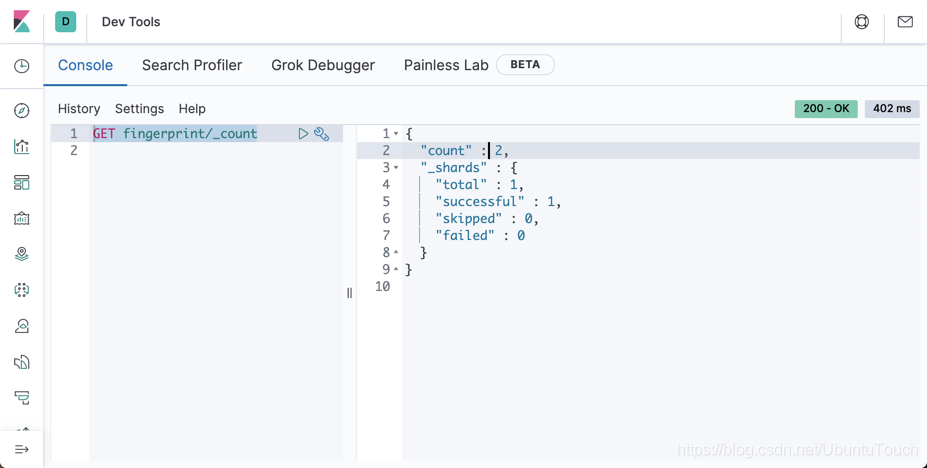
上面显示文档的数值为2。也就是说,在索引 fingerprint 中,只要是 sensor_id 及 date 的数值是一样的,那么我们将永远只有一个文档,而且是永远不会重复的。
转载自:https://elasticstack.blog.csdn.net/article/details/106639848