Github项目地址
https://github.com/ljjy/personal-project
PSP表格
| PSP2.1 | Personal Software Process Stages | 预计耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| ·Estimate | · 估计这个任务需要多少时间 | 600 | 800 |
| Development | 开发 | ||
| ·Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| ·Design Spec | · 生成设计文档 | 20 | 20 |
| ·Design Review | · 设计复审 | 30 | 20 |
| ·Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| ·Design | · 具体设计 | 60 | 40 |
| ·Coding | · 具体编码 | 240 | 360 |
| ·Code Review | · 代码复审 | 60 | 60 |
| ·Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | ||
| ·Test Repor | · 测试报告 | 60 | 60 |
| ·Size Measurement | · 计算工作量 | 20 | 20 |
| ·Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 90 |
| 合计 | 700 | 990 |
解题思路:
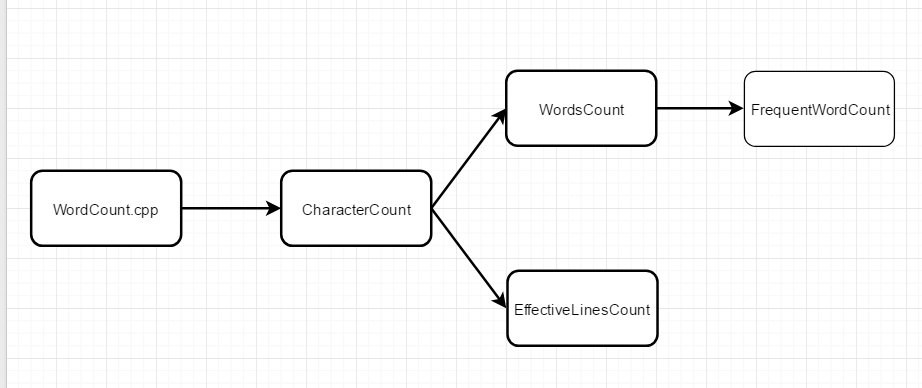
实现基本功能:
- 统计文件的字符数:按行读入字符串,记录每行的字符串长度,最后再加上换行符的个数,得到总字符数。
- 统计文件的有效行数: 因为是按行读入字符串,对每一行进行遍历,如果到行尾还没有遇到非空白字符,就说明该行是非有效行数,反之就是有效行数。
- 统计文件的单词总数: 因为是按行读入字符串,对每一行进行遍历,在确定前四个连续字符是字母的情况下,接着往后遍历字符直到遇到分割符、换行符等,这就找到了一个单词,然后从刚刚遇到的分割符后一个字符开始,继续遍历。
- 统计文件中单词词频: 创建一颗字典树,把每个单词按字典序插入树中,字典树结点包含3个变量,该单词个数,该单词本身,该结点的子结点。然后遍历单词数组,同时维护一个大小为10的优先队列(单词个数小的排在队列前面,单词个数一样的,单词字典树大的排在前面)。
具体实现:
部分代码
trie_node* FrequentWordCount()
{
int flag = 1;
sort(Words,Words+ct);
trie root = create_trie_node();
for(int i=0;i<ct;i++)
{
trie_insert(root,Words[i]); //建立字典树
}
for(int i=0;i<ct;i++) //遍历单词数组
{
int ct = trie_search(root,Words[i]); //搜索该单词
fqtWord.c = ct;
fqtWord.word=Words[i];
if(q.size()<10) //维护优先队列
{
q.push(fqtWord);
}
else
{
q.push(fqtWord);
q.pop();
}
}
while(!q.empty()) //倒序保存优先队列
{
fqtWord = q.top();
str[d] = fqtWord.word;
ans[d] = fqtWord.c;
d++;
q.pop();
}
return root;
}
性能测试:
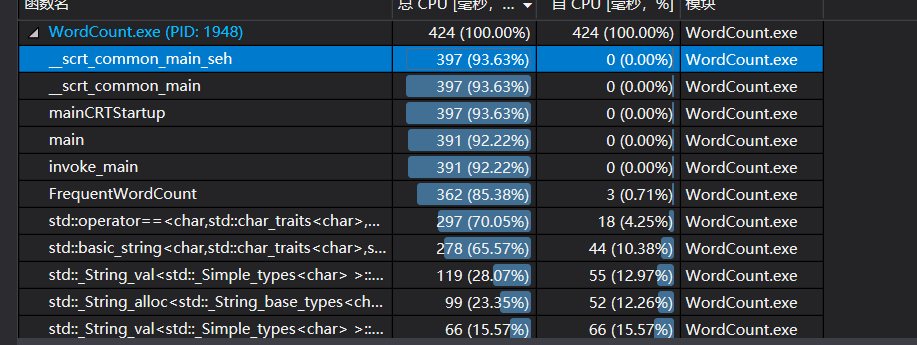
- 我感觉是因为在FrequentWordCount中是通过遍历单词数组的方式通过查找字典树来确认词频,导致多次查找相同的单词。
- 解决方法:通过遍历字典树来确认词频,减少不必要的重复。同时利用字典树的先序遍历即是字典序的特点,可以很容易地做到按字典序排列的要求。
单元测试:
TEST_CLASS(Up_low_wordEuqalText)
{
public:
TEST_METHOD(TestMethod1)
{
// TODO: 在此输入测试代码
int count_up = CharacterCount("test1.txt"); //全小写文件
int count_low = CharacterCount("test2.txt"); //大小写混杂文件
Assert::IsTrue(count_up == count_low); // 两个返回值应该相等,测试通过
}
};
异常处理:
-
文件打不开
if (!file.is_open()) { cout << "文件无法打开" << endl; //return 0; }
总结与感悟
- 虽然作业完成的很糟糕,但是暴露出许多的问题值得自己警惕,懒散拖延,遇到难题不爱问人,自己的学习之路还有很长,接下来的日子继续努力吧!