一、简介
要介绍朴素贝叶斯(naive bayes)分类器,就不得不先介绍贝叶斯决策论的相关理论:
贝叶斯决策论(bayesian decision theory)是概率框架下实施决策的基本方法。对分类任务来说,在所有相关概率都已知的理想情况下,贝叶斯决策论考虑如何基于这些概率和误判损失来选择最优的类别标记结果。
二、贝叶斯决策论的基本原理
我们以多分类任务为例:
假设有N种可能的类别标记,即y={c1,c2,...,cN},λij是将一个真实类别为cj的样本误分类为ci的损失,基于后验概率P(ci|cj)可获得将样本x分类为ci所产生的期望损失(expected loss),即在样本x上的“条件风险”(conditional risk)
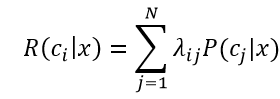
我们的目的是寻得一个判定准则h:X-->Y,以最小化总体风险:
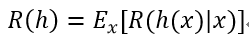
对每一个样本x,若h能最小化条件风险
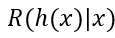
则总体风险R(h)也将被最小化,这就产生了贝叶斯判定准则(Bayes decision rule):为最小化总体风险,只需要在每个样本上选择能使条件风险R(c|x)最小的类别标记,即
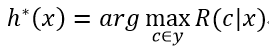
h*被称作贝叶斯最优分类器(Bayes optimal classifier),与之对应的总体风险R(h*)称为贝叶斯风险(Bayes risk)。1-R(h*)反映了分类器所能达到的最佳性能,即通过机器学习所能达到的模型精度的理论上限。
若目标是最小化分类错误率,则误判损失λij可写作
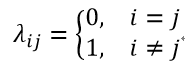
此时的条件风险
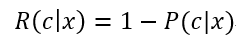
于是,最小化分类错误率的贝叶斯最优分类器为:
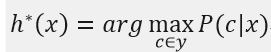
即对每个样本x,选择使得后验概率P(c|x)最大的类别标记,所以利用贝叶斯判定准则来最小化决策风险的首要工作是求得后验概率P(c|x),这在现实任务中通常难以直接获得,而机器学习所要实现的是基于有限的训练样本集来尽可能准确地估计后验概率,主要有两种策略:
1、“判定式模型”(discriminative model)
给定x,通过直接对P(c|x)建模来预测c;
2、“生成式模型”(generative model)
对联合概率分布P(x,c)建模,然后再由此获得P(c|x);
贝叶斯分类器便是一种生成式模型,对生成式模型,考虑条件概率公式:
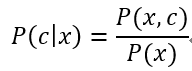
基于贝叶斯定理,P(c|x)可写为:
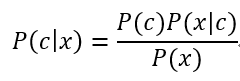
其中,P(c)是类先验概率(prior);P(x|c)是样本x对应类别c的类条件概率(class-condtional probability),或称为“似然”(likelihood);P(x)是用于归一化的“证据”(evidence)因子。对给定样本x,证据因子P(x)与类别无关,因此估计P(c|x)的问题就转化为如何基于训练数据D来估计P(c)和似然P(x|c),类先验概率P(c)表达了样本空间中各类样本所占的比例,根据大数定律,当样本数据规模足够大时,就可以用样本数据的各类别出现的频率来估计P(c)。
上述过程虽然看起来很简单,但是应用到现实任务中就会遇到很多局限,对类条件概率P(x|c),由于它涉及所有关于x的属性的联合概率,直接根据样本出现的频率来估计将会遇到困难,因为实际任务中的训练样本集是有限的,而要估计联合分布就需要获得各种可能状态的样本,这显然无法办到,因为自变量各个维度上的组合方式是指数式增长的,远远大于样本数量,导致很多可能的样本取值从未在训练集中出现过,所以直接用频率来估计P(x|c)不可行,因为这样会直接把未出现过与概率为0画上等号。
为了克服贝叶斯分类器中的局限,我们基于更宽松的理论条件构建出朴素贝叶斯分类器;
三、朴素贝叶斯分类器
为了避开贝叶斯公式的训练障碍,朴素贝叶斯分类器采用了“属性条件独立性假设”(attribute conditional independence assumption),即对已知类别,假设所有属性相互独立,即每个属性各自独立地对分类结果产生影响,则我们前面提到的贝叶斯公式:
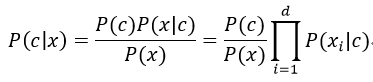
其中d表示属性的个数,xi表示x在第i个属性上的取值,又因为P(x)由样本集唯一确定,即对所有类别P(x)都相同,于是朴素贝叶斯分类器的表达式:
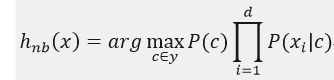
朴素贝叶斯分类器的训练过程就是基于训练集D来估计类先验概率P(c),并为每个属性估计条件概率P(xi|c),用Dc表示训练集D中第c类样本组成的集合,若有充足的独立同分布样本,则可以容易地估计出类先验概率:
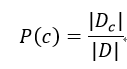
对离散属性而言,令Dc,xi表示Dc中在第i个属性上取值为xi的样本组成的集合,则条件概率P(xi|c)为:
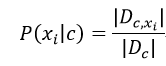
对连续型属性,假定:
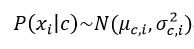
其中μc,i,σ2c,i分别为第c类样本在属性i上的均值与方差(这里要假设对应的连续型变量服从正态分布),则:
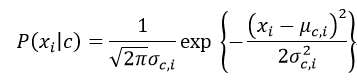
下面以一个简单的例子来详细说明这个过程:
对给定的训练集D,以类别c{c=1/0}作为分类目标,对所有在训练集出现过的属性xi属于X,依此进行下列计算(估计):
1、类先验概率P(c)
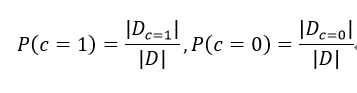
2、各属性的条件概率
以x1为例:
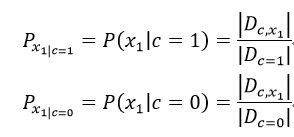
若xi为连续型变量,则利用不同类别中该属性的样本均值与样本方差来估计真实的不同类别中该属性的正态分布对应的参数,求出对应的密度函数;计算出所有属性对所有可能的类别的条件概率;
3、对样本进行分类
针对我们所举的例子,有如下两种情况:
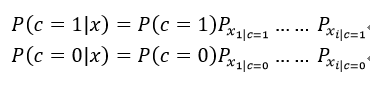
取其中结果较大者对应类别作为最终对样本的分类结果。
修正情况:
有些时候,若某个属性值在训练集中没有与某个类同时出现过,则直接使用上述过程估计后验概率会将整个结果拖累至0,因此这种情况下我们进行如下处理:
平滑(smoothing)
为了避免上面描述的,样本的其他属性携带的信息被训练集中未出现过的属性抹去,则在估计概率值的时候要进行“平滑”处理,常用“拉普拉斯修正”(Laplacian correction),具体操作如下:
我们用N表示训练集D中可能的类别数,Ni表示第i个属性可能的取值个数,则:
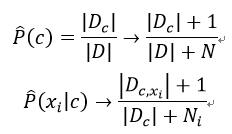
这种修正方法避免了因训练集样本不充分而导致概率估值为0的问题,并且在训练集变大时,修正过程所引入的先验(prior)的影响也会逐渐变得可以忽略,使得估值渐渐趋向于实际概率值。
现实中的使用方式:
1、任务对预测速度要求较高时
可以事先将样本中所有先验概率和类条件概率计算好并储存起来,等到需要预测新样本类别时查表计算对应的后验概率即可;
2、任务数据更替频繁时
可采用“懒惰学习”(lazy learning)的方式,先不进行任何事先训练,仅在有预测需求时才根据当前样本进行概率估计与预测;
3、数据不断增加时
若数据不断增加,则可在现有概率估值的基础上,仅对新增样本的属性值所涉及的概率估值进行修正即可实现增量学习(在线学习);
四、Python实现
我们使用sklearn.naive_bayes中的GaussianNB()来进行朴素贝叶斯分类,这种方法基于的就是我们前面提到的假设非类别型的连续数值变量服从正态分布即高斯分布,其参数非常简单(因为整个建模过程没有什么需要调参数的地方)如下:
priors:数组型,控制针对各类别比例的先验分布,若本参数有输入,则接下来的先验分布将不再基于样本集进行计算;
函数输出项:
class_prior_:输出基于样本集计算出的各类别的先验分布
class_count_:输出训练集中各个类别的样本数量
theta_:输出计算出的对应各连续型特征各类别的样本均值
sigma_:输出计算出的对应各连续型特征各类别的样本方差
下面以我们喜闻乐见的鸢尾花数据进行演示:
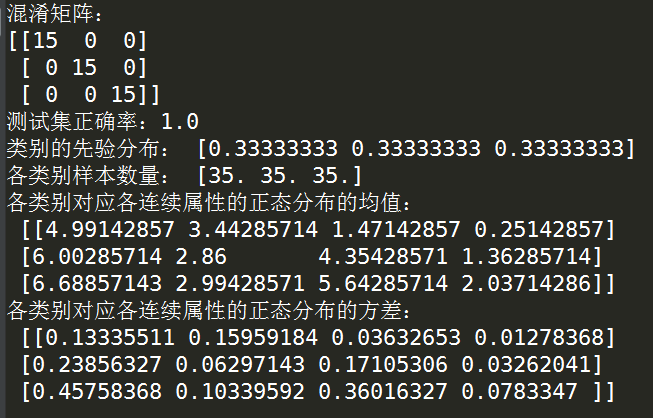
from sklearn.naive_bayes import GaussianNB from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix '''载入数据''' X,y = datasets.load_iris(return_X_y=True) '''分割训练集与验证集,这里采用分层抽样的方法控制类别的先验概率''' X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,stratify=y) '''初始化高斯朴素贝叶斯分类器''' clf = GaussianNB() '''训练分类器''' clf = clf.fit(X_train,y_train) '''打印分类器在验证集上的混淆矩阵''' print('混淆矩阵:') print(confusion_matrix(y_test,clf.predict(X_test))) '''打印测试集上的正确率''' print('测试集正确率:'+str(clf.score(X_test,y_test))) '''打印分类器训练后的各返回项''' print('类别的先验分布:',clf.class_prior_) print('各类别样本数量:',clf.class_count_) print('各类别对应各连续属性的正态分布的均值:',' ',clf.theta_) print('各类别对应各连续属性的正态分布的方差:',' ',clf.sigma_)
运行结果:
五、R实现
在R中有很多包支持朴素贝叶斯分类(事实上自己写自编函数实现也不是件难事),这里选用比较有代表性的e1071包中的naiveBayes()来完成相应功能,其主要参数如下:
formula:这时R中常见的一种格式,类别标签~自变量 的输入形式
data:指定训练数据所在的数据框
laplace:控制前面提到的平滑处理中的拉普拉斯修正,默认值为0,即不进行平滑,若需要进行拉普拉斯修正,这里建议值为1
下面是一个简单的演示:
> rm(list=ls()) > library(e1071) > data(iris) > > #留出法分割训练集与验证集 > sam <- sample(1:dim(iris)[1],dim(iris)[1]*0.8) > X_train <- iris[sam,1:4] > y_train <- iris[sam,5] > X_test <- iris[-sam,1:4] > y_test <- iris[-sam,5] > train <- cbind(y_train,X_train) > > #利用训练集训练朴素贝叶斯分类器 > clf <- naiveBayes(y_train~.,data=train) > > #混淆矩阵 > table(y_test,predict(clf,X_test)) y_test setosa versicolor virginica setosa 9 0 0 versicolor 0 7 1 virginica 0 0 13 > > #测试正确率 > sum(diag(prop.table(table(y_test,predict(clf,X_test))))) [1] 0.9666667
以上就是关于朴素贝叶斯的基本内容,其实朴素贝叶斯方法运用最多的是文本分类问题,接下来的几篇博客我将围绕朴素贝叶斯的文本分类方法进行详细介绍(包含网络文本数据采集的过程)