#sample 1 Python 2,7 已经安装,可以正常跑,但是cx_oracle windows 版本下载下来,无法安装
https://pypi.org/project/cx-Oracle/5.3/#files
1.现在现在版本 cx_Oracle-5.3-11g.win-amd64-py2.7 (321.4 kB) 是5.3 版本,配套oracle 11g client ,配置windos 64 位的
2,安装报错如下:
Python version 2.7 required, which was not found in the registry
使用这个方法可以 手工注册 注册表,正常执行安装
https://www.cnblogs.com/min0208/archive/2012/05/24/2515584.html
#sample2 pycharm 创建一个Project 的虚拟环境时候hang 住3分钟,
因为是脱机环境,可能不能同步数据,可以考虑中断。
然后打开现有的目录,即可
#sample3 pycharm 需要手工配置解释器
Pycharm配置(1)——解释器(interpreter)
参考文档
https://blog.csdn.net/yuangan1529/article/details/80800411
今天导入模块,发现出了很多错,要升级pip,但是我发现在新建的工程项目(PycharmIDE)中有pip,而我安装的Python3中,也有pip ,那我升级哪一个呢?
1、首先,遇到的问题是:已经安装python,dos窗口却提示“python不是内部命令或外部命令,也不是可运行的程序”
解决方案:点击打开链接
2、发现两者都是一样的,都是解释器(Project Interpreter)的问题
(1)什么是解释器
先说一下,什么是解释器,Python的解释器就是Python.exe,是用来解释运行你编写的Python代码的,我们下载的Python(无论是2版本,还是3版本)其实自带解释器和编译器,可以直接在命令行敲入代码,或者写一个文本,然后调用Python的解释器来执行也可以,而Pycharm则是一个IDE(主要是让我们编写程序更加方便,或者说看起来更加简单,不需要用文本或在dos窗口编写代码),但是Pycharm是不带Python解释器的,所以你要在安装Pycharm之前,安装好Python。
上图是我的pycharm运行所需要的外部库:所在位置是一个项目文件中(注意:我的Python3安装位置是D:\Python),然后我检查了一下Pycharm的运行环境:File——>Setting
上面列出的这个图,其实找的是我的项目文件Python编程所需要的项目解释器(Project Interpreter)在哪里,其配置是什么,可以看出,它的解释器就在项目文件下,而不是我安装的D盘中的Python3,那么我就要问了,既然创建项目的时候就有,我还安装Python3干什么?
原来这个问题,我之前遇到了(大约刚安装好Pycharm的时候吧),当时是这个问题:
一开始创建项目的时候,运行第一行代码,貌似是没有配置解释器的,那我当时是怎么配置呢?
还是上面的File——>Setting——>show all(在project Interpreter选项里面),点开以后得到:
点击加号,进行添加(我们看看这个配置的解释器和D盘里面的Python3有什么关系):点击加号以后,会有两个选项,一个是add Local Python Interpreter(这个其实就是你D盘里面的Python3,也就是本地的解释器),第二个是add remote Python interpreter,也就是远程的解释器(不在你的本地机器上,但是你可以远程访问它)
看到这个选项没有,这里说是虚拟环境,也就是说这是一个虚拟解释器,它是建立在D盘里面的Python解释器(第二个圆圈)基础之上的,这里的虚拟解释器在我理解来看,其实和缓存差不多,将要用到的东西放到项目文件夹中,用到的时候,直接调用邻近的,这样速度快,如果没有了,再去原解释器(D盘中),寻找需要的东西。
在网上找了一下关于解释器配置的几种不同说明,可以参考一下:pycharm下基于Virtualenvwrapper和anaconda的Python虚拟环境配置应用
上面提到这种虚拟环境,其实是起到隔离不同版本的Python的效果,virtualenv和conda是两种不同的虚拟隔离环境,当然这些我暂时还没有用到,就先不介绍了,conda用到的是Anaconda
(2)虚拟与基本解释器是否同步?
所以说一切的基础还是在D盘中的Python中,但是两者是同步的吗?
答案是不同步的,我在D盘的Python中安装了numpy模块,但是用虚拟解释器依然报错,只有在虚拟解释器(也就是你解释器的环境下,执行pip install才可以),再次更新一下,两者虽然是不同步的,但是更新下载的时候,只要D盘根解释器已经下载过了,那么虚拟环境中,就不需要联网下载了,可以直接复制D盘的模块,如下图:
上图,是我在D盘Python中下载numpy是,要联网下载关于numpy模块的包,但是我的虚拟解释器那边没有进行更新,但是我在虚拟解释器中下载安装numpy的时候,却非常简单:
如上图所示,没有下载文件,我猜测是直接复制粘贴的D盘中的内容
建议以后先在D盘的Python(我的base interpreter所在位置)安装模块,然后再在虚拟环境中安装,这样以后虚拟环境发生了改变,也可以快速再次安装
————————————————
版权声明:本文为CSDN博主「蓝亚之舟」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yuangan1529/article/details/80800411
####sample 4;
cx_Oracle 连接测试,参考文档
https://cloud.tencent.com/developer/article/1661831
# -*- coding:utf-8 -*-
import cx_Oracle
db = cx_Oracle.connect('dbmgr', 'dbmgr', '10.241.131.126:1521/pcrs')
# db = cx_Oracle.connect('C##oracle', 'oracle', '192.168.106.100:1521/orcl')
cursor=db.cursor()
# sql="SELECT COLUMN1, COLUMN2 FROM C##ORACLE.NEWTABLE"
sql="select du.username,su.password,du.profile,du.account_status
from dba_users du,sys.user$ su
where du.username in (select username from sys.t_user_cfg)
and du.username = su.name"
cursor.execute(sql)
result = cursor.fetchall()
for i in result:
print(i)
cursor.close();
db.close();
###
##sample 1:cx-oracle-lob 读取,for x 后面加入,
https://stackoverflow.com/questions/8646968/how-do-i-read-cx-oracle-lob-data-in-python
cx-oracle-lob 读取,for x 后面加入,
There should be an extra comma in the for loop, see in below code, i have supplied an extra comma after x in for loop.
dsn = cx_Oracle.makedsn(hostname, port, sid)
orcl = cx_Oracle.connect(username + '/' + password + '@' + dsn)
curs = orcl.cursor()
sql = "select TEMPLATE from my_table where id ='6'"
curs.execute(sql)
rows = curs.fetchall()
for x, in rows:
print(x)
Share
Edit
Follow
Flag
##sample 2:cx_Oracle模块学习之绑定变量
https://www.cnblogs.com/riskyer/p/3310676.html
cur.execute('''select * from departments
where department_id=:id and
department_name=:name
''',id=dept_id,name=dept_name
)
cursor.execute('''SELECT DBMS_METADATA.GET_DDL('TABLESPACE',:tname) FROM DUAL''', tname=t_name)
cur.execute('''insert into departments (department_id,department_name,manager_id,location_id)
values(:ID,:NAME,:MGR_ID,:LOC_ID)
''', {'ID':555,'NAME':'WaterBin','MGR_ID':110,'LOC_ID':7788}
)
#######sample 3 How to change values in a tuple?
https://stackoverflow.com/questions/11458239/how-to-change-values-in-a-tuple
t = ('275', '54000', '0.0', '5000.0', '0.0')
lst = list(t)
lst[0] = '300'
t = tuple(lst)
###sample 4
深入理解Python变量与赋值
https://blog.csdn.net/i6223671/article/details/100068214
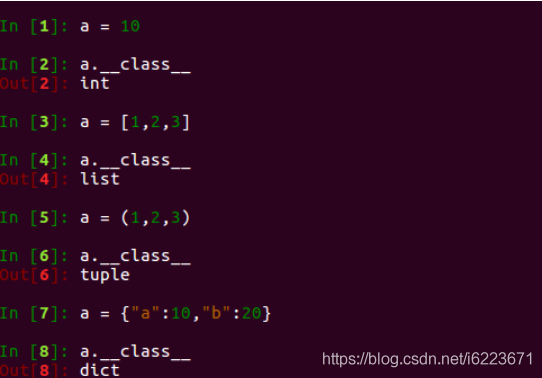
##########sample 1
##sample python 替换文件内容
##参考https://www.cnblogs.com/milian0711/p/7132377.html python 2.7版本解决TypeError: 'encoding' is an invalid keyword argument for this function
###https://www.cnblogs.com/yujihaia/p/7468235.html python 文件内容修改替换操作
# -*- coding:utf-8 -*-
import os
import io
# 打开旧文件
f = io.open('file_text.txt','r',encoding='utf-8')
# 打开新文件
f_new = io.open('file_text_bak.txt','w',encoding='utf-8')
# 循环读取旧文件
for line in f:
# 进行判断
if "Good day is good day" in line:
line = line.replace('Good day is good day','hello,yanyan')
# 如果不符合就正常的将文件中的内容读取并且输出到新文件中
f_new.write(line)
f.close()
f_new.close()
#######
###sample 1 from doc https://www.it610.com/article/1293833117810892800.htm
cd e:\test_pymagic_boxvenvScripts>
pip install E:\test_pymagic_boxpackagePyMySQL-0.9.0-py2.py3-none-any.whl
or
python E:\test_pymagic_boxpackagePyMySQL-0.9.0PyMySQL-0.9.0setup.py install
cd E:\test_pymagic_boxpackagePyMySQL-0.9.0PyMySQL-0.9.0
step step
from doc https://www.it610.com/article/1293833117810892800.htm
根据输出日志,安装顺序如下,依次安装每个补丁:
Installing collected packages: enum34, asn1crypto, pycparser, cffi, idna, ipaddress, cryptography, pymysql
实际安装步骤如下:
(切换到 pip 路径,执行按安装)
cd e:\test_pymagic_boxvenvScripts>
pip install E:\test_pymagic_boxpackagePyMySQL-0.9.0asn1crypto-1.4.0-py2.py3-none-any.whl
pip install E:\test_pymagic_boxpackagePyMySQL-0.9.0six-1.16.0-py2.py3-none-any.whl
pip install E:\test_pymagic_boxpackagePyMySQL-0.9.0enum34-1.1.10-py2-none-any.whl
pip install E:\test_pymagic_boxpackagePyMySQL-0.9.0pycparser-2.20-py2.py3-none-any.whl
pip install E:\test_pymagic_boxpackagePyMySQL-0.9.0cffi-1.14.5-cp27-cp27m-win_amd64.whl
pip install E:\test_pymagic_boxpackagePyMySQL-0.9.0idna-2.10-py2.py3-none-any.whl
pip install E:\test_pymagic_boxpackagePyMySQL-0.9.0ipaddress-1.0.23-py2.py3-none-any.whl
pip install E:\test_pymagic_boxpackagePyMySQL-0.9.0cryptography-2.6-cp27-cp27m-win_amd64.whl
pip install E:\test_pymagic_boxpackagePyMySQL-0.9.0-py2.py3-none-any.whl
#
#######sample 2 https://www.cnblogs.com/walk1314/p/7251126.html
python2(中文编码问题):UnicodeDecodeError: 'ascii' codec can't decode byte 0x?? in position 1
python在安装时,默认的编码是ascii,当程序中出现非ascii编码时,python的处理常常会报这样的错UnicodeDecodeError: 'ascii' codec can't decode byte 0x?? in position 1: ordinal not in range(128),python没办法处理非ascii编码的,此时需要自己设置将python的默认编码,一般设置为utf8的编码格式。
查询系统默认编码可以在解释器中输入以下命令:
python代码
>>>sys.getdefaultencoding()
设置默认编码时使用:
python代码
>>>sys.setdefaultencoding('utf8')
可能会报AttributeError: 'module' object has no attribute 'setdefaultencoding'的错误。执行reload(sys),再执行以上命令就可以顺利通过。
此时再执行sys.getdefaultencoding()就会发现编码已经被设置为utf8的了,但是在解释器里修改的编码只能保证当次有效,在重启解释器后,会发现,编码又被重置为默认的ascii了。
有2种方法设置python的默认编码:
一个解决的方案在程序中加入以下代码:
Python代码
# encoding=utf8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
另一个方案是在python的Libsite-packages文件夹下新建一个sitecustomize.py,内容为:
Python代码
# encoding=utf8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
此时重启python解释器,执行sys.getdefaultencoding(),发现编码已经被设置为utf8的了,多次重启之后,效果相同,这是因为系统在python启动的时候,自行调用该文件,设置系统的默认编码,而不需要每次都手动的加上解决代码,属于一劳永逸的解决方法。
###sample 1 python print 中文
解决pycharm中中文列表输出'xe5xa4xa7xe8x92x9c'之类的字符串
wqy94103 2017-08-09 20:42:29 19850 收藏 7
分类专栏: python 文章标签: python
版权
#coding=utf-8
member=["贝贝","晶晶","欢欢"]
print(member)
print("北京欢迎您!")
1
2
3
4
如上代码块,结果输出为:
[‘xe8xb4x9dxe8xb4x9d’, ‘xe6x99xb6xe6x99xb6’, ‘xe6xacxa2xe6xacxa2’]
北京欢迎您!
该怎么解决以上pycharm中的中文列表输出的编码问题呢?
其实,只需将代码中的‘print(member)’改为’print str(member).decode(‘string-escape’)‘即可
————————————————
版权声明:本文为CSDN博主「wqy94103」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wqy94103/article/details/77016578
##sample 2 python 变量 %c %s 的区别
https://zhidao.baidu.com/question/2017135013606924908.html
符 号
描述
%c
格式化字符及其ASCII码
%s
格式化字符串
%d
格式化整数
%u
格式化无符号整型
%o
格式化无符号八进制数
%x
格式化无符号十六进制数
%X
格式化无符号十六进制数(大写)
%f
格式化浮点数字,可指定小数点后的精度 如:%.2f
%e
用科学计数法格式化浮点数
%E
作用同%e,用科学计数法格式化浮点数
%g
%f和%e的简写
%G
%f 和 %E 的简写
%p
用十六进制数格式化变量的地址
'%c'%65:输出ASII码65对应的字符,对应的是'A'
“%c”是占位符的一种,还有%s %d 等等
%c指的是 字符及其ASCII码
65的ASCII码就是A
#####
##sample for python2
参考https://www.cnblogs.com/ming5218/p/7965973.html
https://blog.csdn.net/jihu0412/article/details/81030308
##for python3
原因:
在 Python 3.x 版本后,ConfigParser.py 已经更名为 configparser.py 所以出错!
解决办法:
cp /usr/local/python3/lib/python3.6/configparser.py /usr/local/python3/lib/python3.6/ConfigParse
##for python2
import ConfigParser
config = ConfigParser.ConfigParser()
config.read('C:\tt\tt\test_py\magic_box\config\config.ini')
['C:\tt\tt\test_py\magic_box\config\config.ini']
##section 部分
print(config.sections())
['test', 'oracle', 'mysql']
##option 部分
r = config.options("mysql")
print(r)
config.get("mysql", "my_pass")
########### sample
https://www.cnblogs.com/kakaln/p/8192957.html#:~:text=%E5%9C%A8%E4%BD%BF%E7%94%A8pycharm%E6%97%B6%EF%BC%8C%E7%BB%8F%E5%B8%B8%E4%BC%9A%E9%9C%80%E8%A6%81%E5%A4%9A%E8%A1%8C%E4%BB%A3%E7%A0%81%E5%90%8C%E6%97%B6%E7%BC%A9%E8%BF%9B%E3%80%81%E5%B7%A6%E7%A7%BB%EF%BC%8Cpycharm%E6%8F%90%E4%BE%9B%E4%BA%86%E5%BF%AB%E6%8D%B7%E6%96%B9%E5%BC%8F%201%E3%80%81pycharm%E4%BD%BF%E5%A4%9A%E8%A1%8C%E4%BB%A3%E7%A0%81%E5%90%8C%E6%97%B6%E7%BC%A9%E8%BF%9B,%E9%BC%A0%E6%A0%87%E9%80%89%E4%B8%AD%E5%A4%9A%E8%A1%8C%E4%BB%A3%E7%A0%81%E5%90%8E%EF%BC%8C%E6%8C%89%E4%B8%8BTab%E9%94%AE%EF%BC%8C%E4%B8%80%E6%AC%A1%E7%BC%A9%E8%BF%9B%E5%9B%9B%E4%B8%AA%E5%AD%97%E7%AC%A6%202%E3%80%81pycharm%E4%BD%BF%E5%A4%9A%E8%A1%8C%E4%BB%A3%E7%A0%81%E5%90%8C%E6%97%B6%E5%B7%A6%E7%A7%BB%20%E9%BC%A0%E6%A0%87%E9%80%89%E4%B8%AD%E5%A4%9A%E8%A1%8C%E4%BB%A3%E7%A0%81%E5%90%8E%EF%BC%8C%E5%90%8C%E6%97%B6%E6%8C%89%E4%BD%8Fshift%2BTab%E9%94%AE%EF%BC%8C%E4%B8%80%E6%AC%A1%E5%B7%A6%E7%A7%BB
pycharm多行代码缩进、左移
在使用pycharm时,经常会需要多行代码同时缩进、左移,pycharm提供了快捷方式
1、pycharm使多行代码同时缩进
鼠标选中多行代码后,按下Tab键,一次缩进四个字符
2、pycharm使多行代码同时左移
鼠标选中多行代码后,同时按住shift+Tab键,一次左移四个字符
########sample 1
##根据下载的顺序,倒叙安装
C:Python27Scripts>pip download faker
Collecting faker
Downloading https://files.pythonhosted.org/packages/35/28/0fbb15ffe79f1068211f6219b88dc817e5f6b455e23806e3d3a4699fd454/Faker-3.0.1-py2.py3-none-any.whl (977kB)
100% |████████████████████████████████| 983kB 181kB/s
Saved c:python27scriptsfaker-3.0.1-py2.py3-none-any.whl
Collecting text-unidecode==1.3 (from faker)
Downloading https://files.pythonhosted.org/packages/a6/a5/c0b6468d3824fe3fde30dbb5e1f687b291608f9473681bbf7dabbf5a87d7/text_unidecode-1.3-py2.py3-none-any.whl (78kB)
100% |████████████████████████████████| 81kB 217kB/s
Saved c:python27scripts ext_unidecode-1.3-py2.py3-none-any.whl
Collecting ipaddress; python_version < "3.3" (from faker)
File was already downloaded c:python27scriptsipaddress-1.0.23-py2.py3-none-any.whl
Collecting python-dateutil>=2.4 (from faker)
Downloading https://files.pythonhosted.org/packages/d4/70/d60450c3dd48ef87586924207ae8907090de0b306af2bce5d134d78615cb/python_dateutil-2.8.1-py2.py3-none-any.whl (227kB)
100% |████████████████████████████████| 235kB 252kB/s
Saved c:python27scriptspython_dateutil-2.8.1-py2.py3-none-any.whl
Collecting six>=1.10 (from faker)
File was already downloaded c:python27scriptssix-1.16.0-py2.py3-none-any.whl
##for faker
cd e:\test_pymagic_boxvenvScripts
pip install E:\test_pymagic_boxpackagefakerpython_dateutil-2.8.1-py2.py3-none-any.whl
pip install E:\test_pymagic_boxpackagefaker ext_unidecode-1.3-py2.py3-none-any.whl
pip install E:\test_pymagic_boxpackagefakerFaker-3.0.1-py2.py3-none-any.whl
##for openpyxl
cd E: t est_pymagic_boxvenvScripts
python E: t est_pymagic_boxpackagefakeret_xmlfile-1.0.1et_xmlfile-1.0.1setup.py install
pip install E: t est_pymagic_boxpackagefakerjdcal-1.4.1-py2.py3-none-any.whl
cd E: t est_pymagic_boxpackagefakeropenpyxl-2.6.4openpyxl-2.6.4
E: t est_pymagic_boxvenvScriptspython setup.py install
##sampe 2
###sample 2 import openpyxl 报错如下:
报错如下:
import openpyxl
ImportError: No module named et_xmlfile
openpyxl.__version__
解决办法:
感谢 KiGiBoy https://www.cnblogs.com/ls11736/p/12398376.html
1.下载et_xmlfile,并解压,然后复制解压后的et_xmlfile,et_xmlfile.egg-info两个文件夹到site-packages下(E:peng est_pymagic_boxvenvLibsite-packages)
copy E:peng est_pymagic_boxvenvLibsite-packages
2.
cd E:peng est_pymagic_boxpackagefakeropenpyxl-2.6.4openpyxl-2.6.4
E:peng est_pymagic_boxvenvScriptspython setup.py install
##sample 3
python中无法创建包含中文路径的文件
https://blog.csdn.net/qq_34621987/article/details/80877210
2.原因:python中默认使用unicode编码,将一个包含中文的utf-8编码的字符串用于创建文件时会出现上图错误中的情况,
应该将encode('utf-8')去掉,或者在字符串前加上u,如 u"一张图片.jpg"
###########sample1
###sample 1
1.首先找到anaconda,运行一次,即使启动不成功,也没关系。
3.
在spyder 右下角的控制台中可以用!pip 使用pip命令:
!pip install 你要安装的模块
pip install faker
pip list
import faker
######sample 2
###sampl 2
3 spyder中debug的一些基本操作
F12是设置断点:
最上方总共有5个调试按钮,都是蓝色的,从左到右依次是:
进入调试;运行当前行;进入函数或方法内运行;跳出函数或方法;运行到下一个断点;退出调试。
我感觉还挺这些按钮的功能左右还对称的。
大概就这样吧,感觉这几个按钮用好了,调试起来效率非常高。
比如说在for循环里面,直接运行到下一个断点,就可以进入下一个循环,或者跳出循环等。
这个就要慢慢摸索了…
————————————————
版权声明:本文为CSDN博主「宇内虹游」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_39278265/article/details/84963883
###########sample 3
3、按照程序员不同的需求进行调试。spyder中提供了调式面板,如图所示
其中第一个按钮是进行调试按钮,点击或者按Ctrl+F5就进入调式,程序到达你设置的第一个断点,这步是调式所必需的;第二个是单步调式按钮,点击或者按Ctrl+F10就可以在设置的断点之后单步调式;第三个按钮可以进入到光标所在句子中含有的函数体内部,或者按快捷键Ctrl+F11;第四个是从此函数中跳出;第五个是跳转到下一个断点;最后一个按钮是停止调试。
点击进行调试之后,可以在下图所示的地方看到变量信息。
#################sampl
https://blog.csdn.net/u012941152/article/details/83011110
Xpath (XML Path Language),是W3C定义的用来在XML文档中选择节点的语言
cols = len(jntua.find_elements_by_xpath('//*[@id="rs"]/table/tbody/tr[1]/th'))
从根目录/开始有点像Linux的文件查看,/代表根目录,一级一级的查找,直接子节点,相当于css_selector中的>号
/html/body/div/p
查找 所有 包含id=rs 的元素,下一级table ,下一级tbody,下一级tr
'//*[@id="rs"]/table/tbody/tr'
查找 所有 包含id=rs 的元素,下一级table ,下一级tbody,下一级tr,下一级th
'//*[@id="rs"]/table/tbody/tr[1]/th'))
找到所有 包含id=rs 的元素,下一级table ,下一级tbody,下一级tr[字符],下一级th[字符]
"//*[@id='rs']/table/tbody/tr[" + str(r) + "]/td[" + str(c) + "]"
####sample 3
selenium报错Message: This version of ChromeDriver only supports Chrome version xx
https://blog.csdn.net/qq_41605934/article/details/116330227
######sample 1
https://www.py.cn/tools/spyder/16326.html
怎么在spyder中建立工程?
yang
2020-02-12 12:37:592544浏览 · 0收藏 · 0评论

在spyder中建立工程的方法:(推荐:spyder使用教程)
1、Spyder项目的创建
新建一个Spyder项目需要点击Spyder上方标签栏中的Projects中的New Project选项。然后给项目取一个名字,选择一下项目存放的路径即可。
2、Spyder项目的打开
Spyder项目文件夹必须 存在.spyproject 这个文件夹,否则Spyder无法打开工程文件夹

Spyproject这个文件夹包含codestyle.ini encoding.ini vcs.ini workspace.ini 这几个配置文件
4,( 选择工具条的 project / open project 。这样就可以看到有右边的该项目文件的导航条)
##############
################sample 2 定位span 模块
https://blog.csdn.net/weixin_42346330/article/details/87093937
selenium如何定位span元素
test-runing 2019-02-12 16:02:48 24887 收藏 11
分类专栏: python+selenium自动化测试 文章标签: span元素定位 元素定位
版权
python+selenium自动化测试
专栏收录该内容
7 篇文章0 订阅
订阅专栏
在做自动化测试时,我们需要定位元素属性来进行操作,今天在做自动化时发现我要定位的登录注册元素找不到,我看了下代码发现,我用xpath获取绝对路径后,发现找不到,F12查看代码如下
代码如下
# _*_ coding: utf-8 _*_
from selenium import webdriver
import logging
import time
driver =webdriver.Chrome()
url="http:************ "
#driver.maximize_window()
driver.get(url) #进入兼职啦首页
time.sleep(2)
driver.find_element_by_xpath('//*[@id="J_site_login"]').click()
然后直接报错
原因:是因为它是内联函数,首先得定位到它的所在的模块。然后再进行定位内联函数
最后代码如下
最后俩行可以组合成一行
driver.find_element_by_xpath('/html/body/div[2]/div/div[4]/div/span//*[@id="J_site_login"]').click()
然后就
————————————————
版权声明:本文为CSDN博主「test-runing」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_42346330/article/details/87093937
########sample 3 获得标签的 绝对路径
https://blog.csdn.net/qq_33852206/article/details/108767757
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 19 16:12:28 2021
""
#通过下拉菜单,和 平级别菜单 来判断 div
from selenium import webdriver
import time
driver = webdriver.Chrome(executable_path="E:logschromedriver_win32chromedriver.exe")
#url = 'http://www.baidu.com'
#driver.get(url)
#
##绝对路径定位
#input_absPath = driver.find_element_by_xpath('/html/body/div/div/div[5]/div/div/form/span/input')
#print('绝对路径定位',input_absPath.get_attribute('outerHTML'))
url = 'http://ai.com.cn'
driver.get(url)
#绝对路径定位
#input_absPath = driver.find_element_by_xpath('/html/body/app-root/app-login/div/form/div[4]')
input_absPath = driver.find_element_by_xpath('/html/body/app-root/app-login/div/form/div[4]/button/span')
print('绝对路径定位',input_absPath.get_attribute('outerHTML'))
########sample 4 IT桔子网模拟登陆,selenium定位type属性
https://www.cnblogs.com/kai-/p/13191377.html
selenium定位type属性
driver.find_element_by_css_selector('input[type="password"]').send_keys('Password')
from selenium import webdriver #用来驱动浏览器的
from selenium.webdriver import ActionChains #破解滑动验证码的时候用,可拖动图片
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC # 和下面WebDriverWait一起用的
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
driver = webdriver.Chrome()
driver.get('https://www.itjuzi.com/login?url=%2F')
# 方式一 Xpath
# driver.find_element_by_xpath('//*[@id="app"]/div[1]/div[2]/div/div/div/div/div[2]/div[1]/form/div[1]/div/div[1]/input').send_keys("jeremy.li@mioying.com")
# driver.find_element_by_xpath('//*[@id="app"]/div[1]/div[2]/div/div/div/div/div[2]/div[1]/form/div[2]/div/div/input').send_keys('Password')
# driver.find_element_by_xpath('//*[@id="app"]/div[1]/div[2]/div/div/div/div/div[2]/div[1]/div/button').click()
# driver.find_element_by_xpath('//form[@class="el-form"]/div/div/div/input').send_keys('jeremy.li@mioying.com')
# driver.find_element_by_xpath('//form[@class="el-form"]/div[2]/div/div/input').send_keys('Password')
# 方式二
driver.find_element_by_css_selector('.el-input__inner').send_keys('jeremy.li@mioying.com')
driver.find_element_by_css_selector('input[type="password"]').send_keys('Password')
############sample 4
selenium.元素定位(find_element_by)
https://www.cnblogs.com/youngleesin/p/10447907.html

from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.implicitly_wait(10) #隐形等待
driver.get('https://www.baidu.com/')
sleep(1)
#以五种定位方式定位到百度首页的搜索输入框
kw_find = driver.find_element_by_id('kw')
#kw_find= driver.find_element_by_class_name('s_ipt')
#kw_find= driver.find_element_by_name('wd')
#kw_find = driver.find_element_by_xpath('//*[@id="kw"]')
#kw_find = driver.find_element_by_css_selector('#kw') #id用#kw,class用.s_ipt ,与css的简写方式相同
#send_keys() 是selenium自带的方法,用来输入文本
kw_find.send_keys('selenium')
#使用id定位方式定位到搜索按钮
su_find = driver.find_element_by_id('su')
#click() 是selenium自带的方法,用来点击定位的元素
su_find.click()
sleep(1)
driver.quit()
#####sample 5 通过chrom 浏览器查找路径xpath的路径
https://www.cnblogs.com/lukechenblogs/p/10481000.html
selenium-百度搜索框输入后,定位联想下拉框元素 (重要)
/html/body/div[1]/div[1]/div[5]/div[1]/div/form/div/ul/li[1]
/html/body/div[1]/div[1]/div[5]/div[1]/div/form/div/ul/li[2]
<li data-key="123123交警官网app" class="bdsug-overflow">123<b>123交警官网app</b></li>
//*[@id="form"]/div/ul/li[2]
#举例如下:
1、输入关键字后,显示联想下拉框,鼠标右键对应的联想字段,点击检查,就可在F12模式下元素查看器中定位到,之后使用Xpath定位。 (重要)


CodeForces 425E Sereja and Sets
int有符号和无符号类型内存 -- C
软件体系结构————防御性编程
Hibernate各保存方法之间的差 (save,persist,update,saveOrUpdte,merge,flush,lock)等一下
椭圆识别
UVa 10223
照片详细解释YUV420数据格式
LeetCode:Reverse Integer
看了此文你还不懂傅里叶变换,那就来掐我吧