String
1.toString:显示对象内容时系统自动调用的方法。
public class TOSTRING {
public String toString(){
return "this is toString method";
}
}
TOSTRING t = new TOSTRING();
System.out.println(t);
2.Math
Math.函数
3.String
1)char charAt(int n) //获得字符串索引为1的字符
String a = "abc";
char b = a.charAt(1); //b的值为'b'
2)int compareTo(String s)
String s = "abc";
String ss = "abd";
System.out.println(s.compareTo(ss));
比较两个字符串的大小,相等输出0;如果s小于ss,输出-1;如果s大于ss,输出1。
尝试了一下,比较"abc"和"ABC",输出的是32,不知道是什么=。=,如果要忽略大小写比较字符串的话可以用下面的compareToIgnoreCase(String s)函数
3)int compareToIgnoreCase(String s)
String s = "abc";
String ss = "BCD";
System.out.println("test compareTo");
System.out.println(s.compareToIgnoreCase(ss));
4)boolean endsWith(String s)
判断字符串是否以s结尾,如果是,返回true
String a = "student.doc";
boolean b = s.endsWith("doc");
5)equals
判断两个字符串对象内容是否相同。如果用“==”比较的是两个字符串在内存存储的地址是否一样。另外一个类似的方法是equalsIgnoreCase(s1);
6)int indexOf(String s,[int i])
查找s在字符串中的索引,找不到返回-1。如果加上参数i表示忽略前i个字符,直接从i+1处找s。对应的还是方法lastIndexOf
String s = "abc";
int index = s.indexOf('d'); //返回-1
index = s.indexOf('b',2); //返回-1
index = s.lastIndexOf('b'); //返回1
7)length方法:返回字符串的长度
8)replace方法:替换字符串中所有指定的字符,然后生成一个新的字符串。
replaceAll方法:替换某个制定的字符串——s.replaceAll("ba","12");
replaceFirst方法:替换s中第一次出现的制定字符串
9)split方法:以特定字符串作为间隔摘分字符串得到一个字符串数组
如果字符串内部存在和间隔字符串相同的内容时,将得到空字符串,例如abbcbtbb用b拆分得到{"a","","c","t"},结尾的空
字符串被忽略
10)String substring(int m):返回索引值m(包括)以后的所有字符作为子字符串
String substring(int m,int n):返回索引值m(包括)到n(不包括)之间的字符作为子字符串。
11)String trim():去掉字符串开始和结尾的空格。
12)valueOf:将其他类型的数据转换为字符串类型。static方法,不用创建String类型的对象。下面是一个判断自然数位数的程序
int n = 12345;
string s = String.valueOf(n);
int len = s.length(); //len值为5
StringBuffer
StringBuffer处理字符串的时候不生成新的对象,直接在原来的字符串上面修改。
1)初始化
StringBuffer s = new StringBuffer();
2)和String之间的转化
String s = "abc";
StringBuffer sb1 = new StringBuffer("123");
StringBuffer sb2 = new StringBuffer(s); //String转StringBuffer
String s1 = sb1.toString(); //StringBuffer转String
3)append方法

StringBuffer sb = new StringBuffer();
String user = "test";
String pwd = "123";
sb.append("select *from userInfo where username=")
.append(user)
.append("and pwd=")
.append(pwd);
4)public StringBuffer deleteCharAt(int index)
public StringBuffer delete(int start,int end) //删除start(包含)到end(不包含)间的字符
5)public StringBuffer insert(int offset, String str)
查了一下第二个参数的取值还有很多,包括boolean,int等。
6)reverse
7)public void SetCharAt(int index,char ch);
新手容易混乱的String+和StringBuffer,以及Java的方法参数传递方式。
之前在交流 群里和猿友们讨论string+和stringbuffer哪个速度快以及Java的方法参数传递的问题,引起了群里猿友的小讨论。最终LZ得出的结果是 string+没有stringbuffer快,不过要看情况。而对于Java的方法参数传递问题,则是百年不变的答案,Java只有值传递。
有一位偏爱技术的猿友,问了LZ好几次这个问题,让LZ再解答一次。由于时间老是对不上,因此都没回复。这里LZ专门写篇博文来解释这个问题,到时候小黎同学来看一下吧。
string+和stringbuffer的速度比较
LZ经常会在交流群里写一些问题,让猿友们回答。有一次LZ写了这样一段程序,问在运行时到底是哪种方式速度快,结果很多猿友果然上了LZ的套。
public class Main{
public static void main(String[] args){
/* 1 */
String string = "a" + "b" + "c";
/* 2 */
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("a");
stringBuffer.append("b");
stringBuffer.append("c");
string = stringBuffer.toString();
}
}
当时大部分的新手猿友都表示,stringbuffer快于string+。唯有群里一位有工作经验的猿友说,是string+的速度快。这让LZ意识到,工作经验确实不是白积累的,一个小问题就看出来了。
这里确实string+的写法要比stringbuffer快,是因为在编译这段程序的时候,编译器会进行常量优化,它会将a、b、c直接合成一个常量abc保存在对应的class文件当中。LZ当时在群里贴出了编译后的class文件的反编译代码,如下。
public class Main
{
public static void main(String[] args)
{
String string = "abc";
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("a");
stringBuffer.append("b");
stringBuffer.append("c");
string = stringBuffer.toString();
}
}
可以看出,在编译这个java文件时,编译器已经直接进行了+运算,这是因为a、b、c这三个字符串都是常量,是可以在编译期由编译器完成这个运算的。假设我们换一种写法。
public class Main{
public static void main(String[] args){
/* 1 */
String a = "a";
String b = "b";
String c = "c";
String string = a + b + c;
/* 2 */
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(a);
stringBuffer.append(b);
stringBuffer.append(c);
string = stringBuffer.toString();
}
}
此处的答案貌似应该是stringbuffer更快,因为此时a、b、c都是对象,编译器已经无法在编译期进行提前的运算优化了。
但是,事实真的是这样的吗?
其实答案依然是第一种写法更快,也就是string+的写法更快,这一点可能会有猿友比较疑惑。这个原因是因为string+其实是由stringbuilder完成的,而一般情况下stringbuilder要快于stringbuffer,这是因为stringbuilder线程不安全,少了很多线程锁的时间开销,因此这里依然是string+的写法速度更快。
尽管LZ已经解释了原因,不过可能还是有猿友依然不太相信,那么下面我们来写一个测试程序。
public class Main
{
public static void main(String[] args)
{
String a = "a";
String b = "b";
String c = "c";
long start = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
String string = a + b + c;
if (string.equals("abc")) {}
}
System.out.println("string+ cost time:" + (System.currentTimeMillis() - start) + "ms");
start = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(a);
stringBuffer.append(b);
stringBuffer.append(c);
String string = stringBuffer.toString();
if (string.equals("abc")) {}
}
System.out.println("stringbuffer cost time:" + (System.currentTimeMillis() - start) + "ms");
}
}
我们每个进行了1亿次,我们会看到string+竟然真的快于stringbuffer,是不是瞬间被毁了三观,我们来看下结果。

答案已经很显然,string+竟然真的比stringbuffer要快。这里其实还是编译器捣的鬼,string+事实上是由stringbuilder完成的。我们来看一下这个程序的class文件内容就可以看出来了。

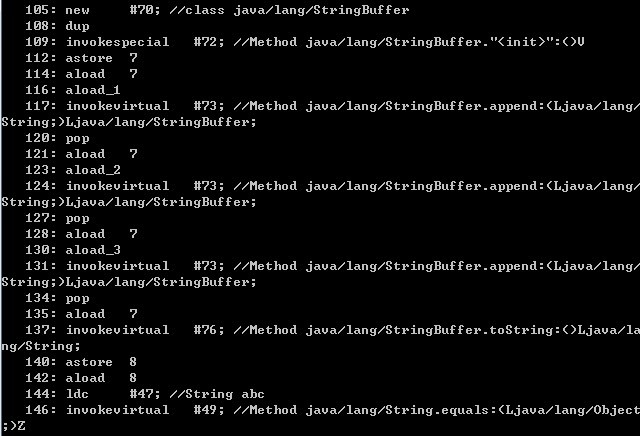
由于文件太长,所以LZ是分开截的图。可以看到,里面有两次 stringbuilder的append方法调用,三次stringbuffer的append方法调用。stringbuilder只有两次 append方法的调用,是因为在创建stringbuilder对象的时候,第一个字符串也就是a对象已经被当做构造函数的参数传入了进去,因此就少了 一次append方法。
不过请各位猿友不要误会,这里stringbuilder之所以比stringbuffer快,是因为少了锁同步的开销,而不是因为少了一次append方法,原因看下面这段stringbuilder类的源码就知道了。
public StringBuilder(String str) {
super(str.length() + 16);
append(str);
}
可以看到,实际上带有string参数的构造方法,依然是使用的append方法,因此stringbuilder其实也进行了三次append方法的调用。
看到这里,估计有的猿友就该奇怪了,这么看的话,似乎string+的速度比stringbuffer更快,难道以前的认识都错误了?
答案当然是否定的,我们来看下面这个小程序,你就看出来差别有多大了。
public class Main
{
public static void main(String[] args)
{
String a = "a";
long start = System.currentTimeMillis();
String string = a;
for (int i = 0; i < 100000; i++) {
string += a;
}
if (string.equals("abc")) {}
System.out.println("string+ cost time:" + (System.currentTimeMillis() - start) + "ms");
start = System.currentTimeMillis();
StringBuffer stringBuffer = new StringBuffer();
for (int i = 0; i < 100000; i++) {
stringBuffer.append(a);
}
if (stringBuffer.toString().equals("abc")) {}
System.out.println("stringbuffer cost time:" + (System.currentTimeMillis() - start) + "ms");
}
}
这个程序与刚才的程序有着细微的差别,但是结果却会让你大跌眼镜。我们来看结果输出。
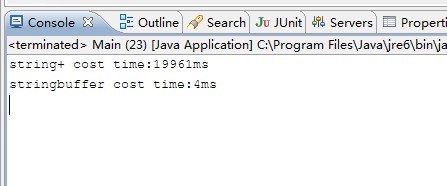
看到这个结果是不是直接给跪了,效率差了这么多?这还是LZ将循环次数降到了10万,而不是1亿,因为1亿次LZ跑了很久也没跑完,LZ等不急了,0.0。
造成这种情况的原因,我们看两个程序的区别就看出来了。第一个循环1亿次的程 序,不管是string+还是stringbuffer都是在循环体里构造的字符串,最重要的是string+是由一个语句构造而成的,因此此时 string+其实和stringbuffer实际运行的方式是一样的,只不过string+是使用的stringbuilder而已。
而对于上面这个10万次循环的程序,stringbuffer就不用说了,实 际运行的方式很明显。而对于string+,它将会创造10万个stringbuilder对象,每一次循环体的发生,都相当于我们新建了一个 stringbuilder对象,将string对象作为构造函数的参数,并进行一次append方法和一次toString方法。
由上面几个小程序我们可以看出,在string+写成一个表达式的时候(更准确的说,是写成一个赋值语句的时候),效率其实比stringbuffer更快,但如果不是这样的话,则效率会明显低于stringbuffer。我们来再写一个程序证实这一点。
为了不会导致编译失败,我们将循环次数减为1万次,否则会超出文件的最大长度,我们先来看看刚才的程序改为1万次循环的结果。
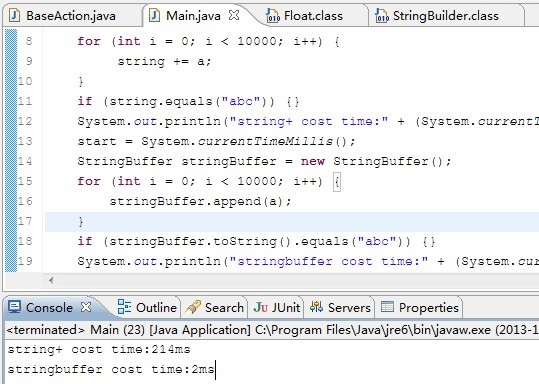
可以看到,在1万次的循环下,依然可以看到效率上的明显差异,这个差距已经足够我们观察了。现在我们就改一种写法,它会让string+的效率提高到stringbuffer的速度,甚至更快。
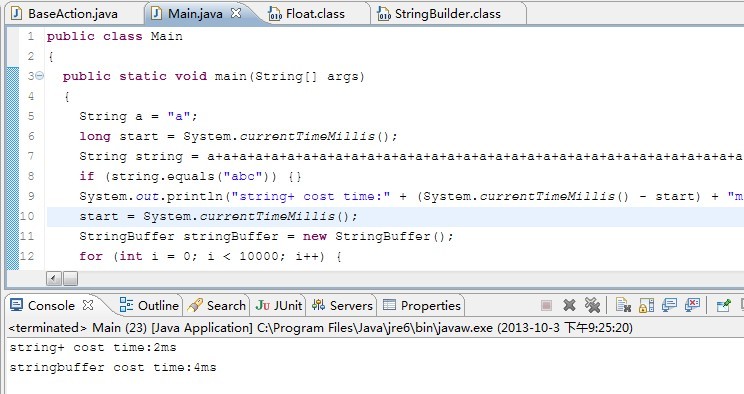
这里我们是将1万次字符串的拼接直接写成了一个表达式,那个a+a+...表达式一共是1万个(是LZ使用循环打印出来贴到代码处的),可以看到,此时string+的速度已经超过了stringbuffer。
因此LZ给各位猿友一个建议,如果是有限个string+的操作,可以直接写 成一个表达式的情况下,那么速度其实与stringbuffer是一样的,甚至更快,因此有时候没必要就几个字符串操作也要建个 stringbuffer(如果中途拼接操作的字符串是线程间共享的,那么也建议使用stringbuffer,因为它是线程安全的)。但是如果把 string+的操作拆分成语句去进行的话,那么速度将会指数倍下降。
总之,我们大部分时候的宗旨是,如果是string+操作,我们应该尽量在一个语句中完成。如果是无法做到,并且拼接动作很多,比如数百上千成万次,则必须使用stringbuffer,不能用string+,否则速度会很慢。
Java的方法参数传递方式
这个问题的引入是当时LZ在群里问了这样一个问题,就是Java的方法参数传递是值传递还是引用传递?对于基本类型和对象来说,都会发生什么情况?
这道题大部分猿友还是说的不错的,包括群里的新手猿友。答案是Java只有值传递,因为Java只有值传递,因此在改变形参的值的时候,实参是不会因此而改变的。这一点从下面这个小程序可以很明显的看出来。
public class Main
{
public static void main(String[] args)
{
int a = 2;
Object object = new Object();
System.out.println(a + ":" + object);
change(a, object);
System.out.println(a + ":" + object);
}
public static void change(int a,Object object){
a = 1;
object = new Object();
}
}
我们在方法当中改变形参的值,之后再次输出两个实参的值,会发现它们无任何变化。

这就足以说明Java只有值传递了,无论是对象还是基本类型,改变形参的值不会反应到实参上面去,这也正是值传递的奥义所在。
对于基本类型来说,这一点比较明显,不过对于对象来讲,很多猿友会有误解。认为我们在方法里改变形参对象属性的值,是会反映到实参上面去的,因此部分猿友认为这就是引用传递。
首先LZ要强调的是,上面也说了,我们只是改变形参对象属性的值,反映到实参上面去的,而不是真的改变了实参的值,也就是说实参引用的对象依然是原来的对象,只不过对象里的属性值改变了而已。
针对上面这一点,我们使用下面这个程序来说明。
public class Main
{
public static void main(String[] args)
{
int a = 2;
Entity entity = new Entity();
entity.a = 100;
System.out.println(a + ":" + entity);
System.out.println(entity.a);
change(a, entity);
System.out.println(a + ":" + entity);
System.out.println(entity.a);
}
public static void change(int a,Entity entity){
a = 1;
entity.a = 200;
}
}
class Entity{
int a;
}
我们在方法里改变了entity对象的属性值为200,我们来看一下结果。

可以看到,实参对象的值依然没有改变,只是属性值变了而已,因此这依旧是值传递的范围。为了说明这个区别,我们来看下真正的引用传递。由于Java当中不存在引用传递,因此LZ借用C/C++来让各位看下真正的引用传递是什么效果。
1 #include <stdio.h>
2
3 class Entity{
4 public:
5 int a;
6 Entity(){};
7 };
8
9 void change(int &a,Entity *&entity);
10
11 int main(){
12 int a = 2;
13 Entity *entity = new Entity();
14 printf("%d:%p
",a,entity);
15 change(a, entity);
16 printf("%d:%p
",a,entity);
17 }
18
19 void change(int &a,Entity *&entity){
20 a = 1;
21 entity = new Entity();
22 }
LZ尽量保持和Java的第一个程序是一样的结构,只不过C/C++中没有现成的Object对象,因此这里使用Entity对象代替,这样便于各位猿友理解。我们来看下结果,结果会发现引用传递的时候,在方法里改变形参的值会直接反应到实参上面去。
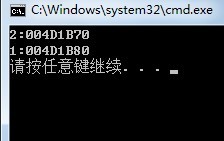
可以看到,在引用传递的时候,无论是基本类型,还是对象类型,实参的值都发生 了变化,这里才是真正的引用传递。当然了,LZ对C/C++的理解非常有限,不过毋庸置疑的是,真正的引用传递应该是类似上述的现象,也就是说实参会因形 参的改变而改变的现象,而这显然不是我们Java程序当中的现象。
因此,结论就是Java当中只有值传递,但是这并不影响我们在方法中改变对象参数的属性值。
文章小结
我们平时多了解一些语言的特性确实是有很多好处的,这会潜移默化的影响我们编码的质量。希望各位猿友在遇到这种问题的时候也自己多写写代码,看看自己的理解对不对,在这样的过程中进步会很快,尤其是在初次接触一个编程语言的时候。
附录
有一次LZ的一个同事给LZ借钱,LZ说,“干嘛用的”。那哥们说,“接女朋友用的”。LZ问多少钱,那哥们说“10块就够了”。LZ疑惑了,便问,“10块钱,尼玛起步价都不怎么够”。结果那哥们蛋定的拿过钱,说了一句“够了,我付快递费”。