1. java集合框架图
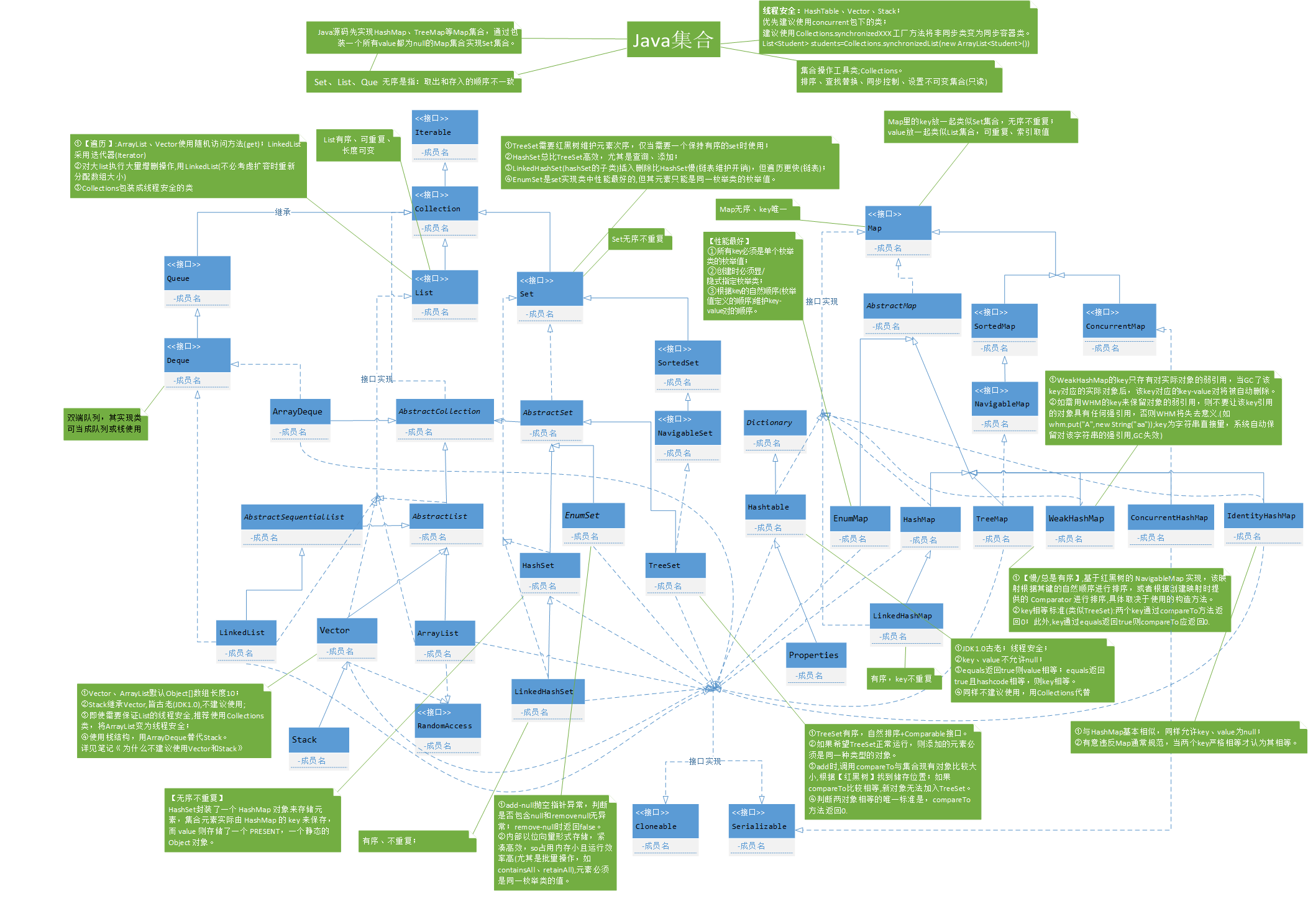
图片来源 https://blog.csdn.net/u010887744/article/details/50575735
2. 迭代器
Iterator:迭代器,它是Java集合的顶层接口(不包括 map 系列的集合,Map接口 是 map 系列集合的顶层接口)
使用场景:只要实现了Iterable接口的类,就可以使用Iterator迭代器,注意:map系列集合不能够使用迭代器
迭代器函数:
Object next():返回迭代器刚越过的元素的引用,返回值是 Object,
Iterator<Student> it = arr.iterator(); // 这样使用时可以不强制类型转换
boolean hasNext():判断容器内是否还有可供访问的元素
void remove():删除迭代器刚越过的元素
3. 集合遍历的三种方法:
public static void main(String[] args) { ArrayList<Student> arr = new ArrayList<Student>(); Student s1 = new Student("linqinxia", 216); Student s2 = new Student("diaochan", 78); Student s3 = new Student("wnagjing", 78); Student s4 = new Student("wnagjun", 88); arr.add(s1); arr.add(s2); arr.add(s3); arr.add(s4); // 方法1:迭代器遍历 Iterator<Student> it = arr.iterator(); while (it.hasNext()) { Student s = it.next(); System.out.println(s.getName() + "---" + s.getAge()); } // 方法2:增强for 遍历 for (Student m : arr) { System.out.println(m.getName() + "----" + m.getAge()); } // 方法3:使用for 循环遍历 for (int x = 0; x < arr.size(); x++) { Student s = (Student) arr.get(x); System.out.println(s.getName() + "----" + s.getAge()); } }
4. collection(接口,继承自Iterable,实现:AbstractCollection):
public static void main(String[] args) { Collection<Person> c1 = new ArrayList<Person>(); Collection<Student> c2 = new ArrayList<Student>(); Collection<Student> c3 = new ArrayList<Student>(); Person p1 = new Person(); Person p2 = new Person(); Person p3 = new Person(); Student s1 = new Student("wangjing", 20); Student s2 = new Student("wangjun", 21); Student s3 = new Student("xiaoha", 19); Student s4 = new Student("wangjing", 20); c1.add(p1); //1. add(#):添加一个元素 c1.add(p2); c1.add(p3); c2.add(s1); c2.add(s2); c2.add(s3); c3.add(s4); c1.addAll(c2); //2. addAll(Collection<? extends E>):添加另一个集合中所有的元素 System.out.println(c1.size()); c1.clear(); //3. clear():清除集合中所有的元素 System.out.println(c1.size()); System.out.println(c2.contains(s2)); //4. contains(Object):判断该元素是否在集合中 System.out.println(c2.containsAll(c3)); //5. containsAll(Collection<? extends E>):判断输入集合所有元素是否在该集合中 c3.add(s2); c3.add(s3); System.out.println(c2.equals(c3)); //6. equals(Object):判断两个集合中所有的元素是否相等,只需要判断c2中的每一个元素是否equals c3中的一个元素,equals可以重写 System.out.println(c2.hashCode()); //7. hashCode():返回集合的hashCode编码 Iterator<Student> it = c2.iterator(); //8. iterator():返回集合的迭代器 while(it.hasNext()) { Student s = it.next(); System.out.println(s.getName() + ":" + s.getAge()); } System.out.println(c2.parallelStream()); //9. parallelStream():返回java.util.stream.ReferencePipeline$Head@5c647e05 c2.remove(s2); //10. remove(Object):删除一个元素 System.out.println(c2.size()); c2.add(s2); c2.removeAll(c3); // 11. removeAll(Collection<?>) System.out.println(c2.size()); c2.size(); //12. c2.size():返回集合的大小 c2.add(s1); c2.add(s2); c2.add(s3); Student[] s = c2.toArray(new Student[0]); //13 toArray[T[]] 将集合转换成数组 数组转集合的方法:List<String> mlist = Arrays.asList(array); System.out.println(s[1].getName()); Object[] objs = c2.toArray(); //14 toArray[],集合转数组 System.out.println(Arrays.toString(objs)); c3.clear(); c3.add(s1); c3.add(s2); c2.retainAll(c3); //15 retainAll(): c2中的元素全部使用c3中的元素代替 Object[] obj = c2.toArray(); System.out.println(Arrays.toString(obj)); }
5 List(接口,继承自Collection,实现:AbstractCollection,有序(存储顺序与取出顺序一致)可以重复)
public static void main(String[] args) { List<String> s = new ArrayList<String>(); s.add("wangjing"); s.add("wangjun"); s.add("wangjing"); s.add("xiaoha"); s.add("wangjing"); System.out.println(s.indexOf("wangjing")); // indexOf(Object) 返回对象在集合中首次出现的索引 System.out.println(s.lastIndexOf("wangjing")); // lastIndexOf(Object) 返回对象在集合中最后一次出现的索引 ListIterator<String> lt = s.listIterator(); // listIterator 返回ListIterator接口的具体实现 // ------------------------ListIterator--------------------------------- System.out.println(lt.next()); // ListIterator:next() 返回下一个对象,注意,next()第一次使用后对应的索引是0 System.out.println(lt.previous()); // ListIterator:previous() 返回上一个对象 lt.next(); lt.next(); System.out.println(lt.nextIndex()); // ListIterator:nextIndex() 返回下一个next()对象的索引 lt.add("lainglaing"); // ListIterator:add(E) 从当前索引所在的位置插入对象,next()指向第几个对象,从第几个对象的位置插入 while (lt.hasNext()) { // ListIterator:Next() 判断是否有前一个对象 lt.next(); } while (lt.hasPrevious()) { // ListIterator:hasPrevious() 判断是否有前一个对象 System.out.println(lt.previous()); } System.out.println("--------"); lt.remove(); // ListIterator:remove() 删除迭代器最后一次操作的元素,此次删除的是集合的第一个元素 while (lt.hasNext()) { // ListIterator:Next() 判断是否有前一个对象 System.out.println(lt.next()); } lt.set("xiaohuang"); // ListIterator:set(E) 将迭代器最后一次返回的对象用E替代 while (lt.hasPrevious()) { // ListIterator:hasPrevious() 判断是否有前一个对象 lt.previous(); } while (lt.hasNext()) { // ListIterator:Next() 判断是否有前一个对象 System.out.println(lt.next()); } System.out.println("*************************88"); // ------------------------------------------------------------------------ ListIterator<String> lm = s.listIterator(3); // listIterator(n) 取集合前n-1个元素转换成ListIterator while (lm.hasNext()) { // ListIterator:Next() 判断是否有前一个对象 System.out.println(lm.next()); } List<String> li = s.subList(0, 3); //sublist(int, int) 截断操作,包左不包右 for (int i = 0; i < li.size(); i++) { System.out.println(li.get(i)); } System.out.println("--------------"); s.set(1, "wangwangwang"); //set(int, E):修改第n个对象,使用E代替 for (int i = 0; i < s.size(); i++) { System.out.println(s.get(i)); } }
5.1 ArrayList
特点:底层数据结构是数组,查询快,增删慢
线程不安全,效率高
5.2 Vector
特点:底层数据结构是数组,查询快,增删慢
线程安全,效率低
5.3 LinkedList
特点:底层数据结构是链表,查询慢,增删快
线程不安全,效率高
6. Set(元素唯一性)
6.1 HashSet
特点:基于哈希表:一个元素为链表的数组,综合了数组和链表的特点,无序
重要:唯一性依赖于底层的hashCode()和equals()
public static void main(String[] args) { Set<String> set = new HashSet<String>(); set.add("hello"); //add(E): 底层依赖hashCode() 和 equals() set.add("java"); //String重写了hashCode() 和 equals() set.add("world"); set.add("hello"); set.add("java"); set.add("world"); for(String s:set) { System.out.println(s); //java world hello } Set<Student> hs = new HashSet<Student>(); Student s1 = new Student("wangjing", 20); Student s2 = new Student("wangjun", 20); Student s3 = new Student("wangjing", 20); hs.add(s1); hs.add(s2); hs.add(s3); System.out.println(hs); }
6.2 HashSet的子类LinkedHashSet
特点:具有可预知的迭代顺序的set接口的哈希表(唯一性)和链表(有序)实现
public static void main(String[] args) { LinkedHashSet<String> hs = new LinkedHashSet<String>(); hs.add("hello"); hs.add("world"); hs.add("java"); hs.add("world"); System.out.println(hs); // [hello, world, java] }
6.3 TreeSet(继承自AbstractSet)
特点:能够对元素按照某种规则排序
唯一性:根据比较返回是否是0来决定的
排序的两种方法:
A:自然排序
自然排序重要:真正的比较依赖于元素的compareTo()方法,这个方法是定义在Comparable里面的,如果想重写该方法,必须实现Comparable接口
TreeSet的底层是二叉树结构(红黑树:自平衡的二叉树,二叉检索树,对于二叉检索树的任意一个节点,设其值为K,则该节点左子树中的任意一个节点的值都小于K,该节点右子树中的任意一个节点的值都大于等于K,如果按照中序遍历将各个节点打印出来,就会得到从小到大排列的节点。)
compareTo方法写法:
学生类按照年龄排序:
@Override public int compareTo(Student o) { int num = this.age - o.age; int nu = num == 0 ? this.name.compareTo(o.name) : num; return nu; // 返回0,则不添加,返回数大于0,添加到二叉树右边,返回数小于0,添加到二叉树左边,实现了去重 }
学生类按照姓名的长度排序
@Override public int compareTo(Student o) { int num = this.name.length(); int nu = num == 0 ? this.name.compareTo(o.name) : num; int numu = nu == 0 ? this.age - o.age : nu; return numu; // 返回0,则不添加,返回数大于0,添加到右边,返回数小于0,添加到左边 }
B:比较器排序
public TreeSet(Comparator<? super E> comparator)
第一种方法:使用外部类,比较麻烦
public class MyComparator implements Comparator<Student>{ @Override public int compare(Student o1, Student o2) { // TODO Auto-generated method stub int num1 = o1.getName().length() - o2.getName().length(); int num2 = num1 == 0 ? o1.getName().compareTo(o2.getName()) : num1; int num3 = num2 == 0 ? o1.getAge() - o2.getAge() : num2; return num3; } } TreeSet<Student> ts = new TreeSet<Student>(new MyComparator()); // 调用
第二种方法:匿名内部类实现(常用)
TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { // TODO Auto-generated method stub int num1 = o1.getName().length() - o2.getName().length(); int num2 = num1 == 0 ? o1.getName().compareTo(o2.getName()) : num1; int num3 = num2 == 0 ? o1.getAge() - o2.getAge() : num2; return num3; } });
7. Collections:工具类
collection与collections的区别:
1. collection:是单列集合的顶层接口,有子接口List和Set
2. Collection:是针对集合操作的工具类,有对集合进行排序和二分查找的方法
public static <T> void sort(List<T> list):排序,默认自然排序
public static <T> int binarySearch(List<?> list, T key):二分查找
public static <T> t max(Collection<?> coll):最大值
pullic static void reverse(List<?> list):反转
public static void shuffle(List<?> list):随机置换
public static void main(String[] args) { List<Integer> list = new ArrayList<Integer>(); list.add(30); list.add(29); list.add(50); list.add(80); Collections.sort(list); System.out.println("list:" + list); System.out.println("binarySearch:" + Collections.binarySearch(list, 300)); System.out.println("max:" + Collections.max(list)); Collections.reverse(list); System.out.println("list:" + list); Collections.shuffle(list); // 随机置换 System.out.println("list:" + list); }
public static void main(String[] args) { List<Student> list = new ArrayList<Student>(); Student s1 = new Student("林青霞", 27); Student s2 = new Student("风清扬", 30); Student s3 = new Student("留意", 30); Student s4 = new Student("武松", 399); Student s5 = new Student("武松", 399); list.add(s1); list.add(s2); list.add(s3); list.add(s4); list.add(s5); Collections.sort(list); // 相同的元素不可以去除 System.out.println("list:" + list); Collections.sort(list, new Comparator<Student>(){ @Override public int compare(Student o1, Student o2) { int num = o1.getAge() - o2.getAge(); int num2 = num==0 ? o1.getName().compareTo(o2.getName()) : num; return num2; } }); }