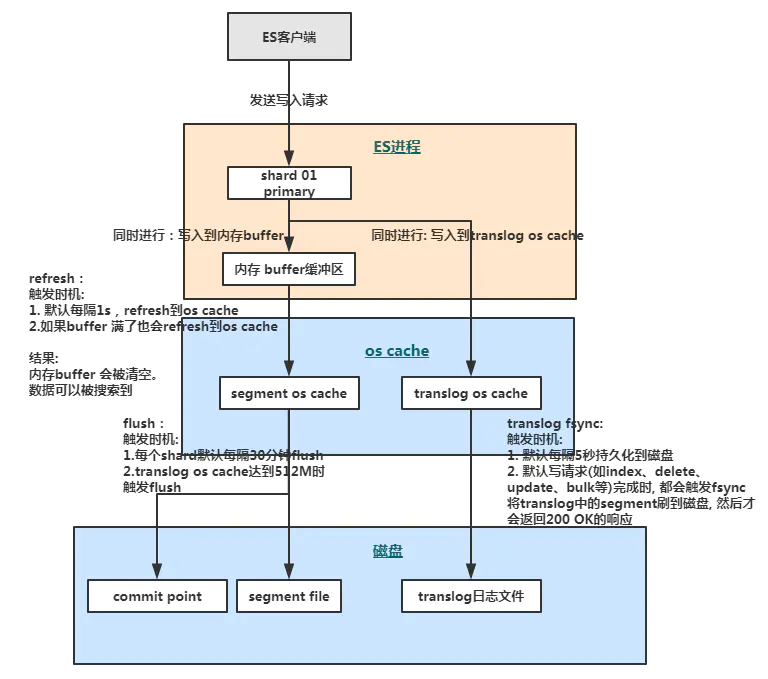
es写入过程关键步骤:
- 数据写入index buffer缓冲和translog日志文件。index buffer(indices.memory.index_buffer_size) 大小默认是heap的10%,最小值为48M。
- 每隔一秒钟(index.refresh_interval),index buffer中的数据被写入新的segment file,并进入os cache,此时segment被打开并供search使用。
- buffer被清空。
- 重复1~3,新的segment不断添加,buffer不断被清空,而translog中的数据不断累加
- 当translog长度达到一定程度的时候,commit操作发生。
假设我们的应用场景要求是,每秒 300 万的写入速度,每条 500 字节左右。
针对这种对于搜索性能要求不高,但是对写入要求较高的场景,我们需要尽可能的选择恰当写优化策略。
综合来说,可以考虑以下几个方面来提升写索引的性能:
-
加大 Translog Flush ,目的是降低 Iops、Writeblock。
-
增加 Index Refresh 间隔,目的是减少 Segment Merge 的次数。
-
调整 Bulk 线程池和队列。
-
优化节点间的任务分布。
-
优化 Lucene 层的索引建立,目的是降低 CPU 及 IO。
优化方案:
1.Lucene 在新增数据时,采用了延迟写入的策略,默认情况下索引的 refresh_interval 为 1 秒。
Lucene 将待写入的数据先写到内存中,超过 1 秒(默认)时就会触发一次 Refresh,然后 Refresh 会把内存中的的数据刷新到操作系统的文件缓存系统中。
如果我们对搜索的实效性要求不高,可以将 Refresh 周期延长,例如 30 秒。
这样还可以有效地减少段刷新次数,但这同时意味着需要消耗更多的Heap内存。
index.refresh_interval:30s2.由于 Lucene 段合并的计算量庞大,会消耗大量的 I/O,所以 ES 默认采用较保守的策略,让后台定期进行段合并,如下所述:
-
索引写入效率下降:当段合并的速度落后于索引写入的速度时,ES 会把索引的线程数量减少到 1。
这样可以避免出现堆积的段数量爆发,同时在日志中打印出“now throttling indexing”INFO 级别的“警告”信息。
-
提升段合并速度:ES 默认对段合并的速度是 20m/s,如果使用了 SSD,我们可以通过以下的命令将这个合并的速度增加到 100m/s。
PUT /_cluster/settings
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}3,修改index_buffer_size 的设置,可以设置成百分数,也可设置成具体的大小,大小可根据集群的规模做不同的设置测试。优化可以设置成20%以上。
indices.memory.index_buffer_size:10%(默认是heap的10%)
indices.memory.min_index_buffer_size: 48mb(默认)
indices.memory.max_index_buffer_size4,堆大小的设置
由于ES构建基于lucene, 而lucene设计强大之处在于lucene能够很好的利用操作系统内存来缓存索引数据,以提供快速的查询性能。lucene的索引文件segements是存储在单文件中的,并且不可变,对于OS来说,能够很友好地将索引文件保持在cache中,以便快速访问;因此,我们很有必要将一半的物理内存留给lucene ; 另一半的物理内存留给ES(JVM heap )。所以, 在ES内存设置方面,可以遵循以下原则:
当机器内存小于64G时,遵循通用的原则,50%给ES,50%留给lucene。
5,使用 hot_threads api。
集群所有节点:
curl -XGET `hostname -i`:9200/_nodes/hot_threads
单个节点:
curl -XGET `hostname -i`:9200/_nodes/node-name/hot_threads
其中 node-name 替换成自己节点节点名称
使用 top + jstatck 获取堆栈信息
参考文档:
https://www.cnblogs.com/technologykai/articles/10899582.html
https://www.cnblogs.com/zhangan/p/11231990.html
https://blog.csdn.net/wwd0501/article/details/105077508?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2.no_search_link&utm_relevant_index=5