这周学习了hadoop的核心HDFS。
在现代的企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理分布在集群上的文件系统成为分布式文件系统。HDFS是Apache Hadoop项目的一个子项目。Hadoop非常适合于存储大型数据(比如TB和PB),其就是使用HDFS作为存储系统。HDFS使用多台计算机存储文件,并且提供统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统。
HDFS适合于存储大文件,需要高吞吐量,对延时没有要求;采用流式的数据访问方式,即一次写入、多次读取,数据集经常从数据源生成或者拷贝一次,然后在其上做很多分析工作;运行于商业硬件上:Hadoop不需要特别贵的机器,可运行于普通廉价机器,可以处节约成本;需要高容错性;为数据存储提供所需的扩展能力。不适用于低延时的数据访问,对延时要求在毫秒级别的应用,不适合采用HDFS。不适用于大量小文件,文件的元数据保存在NameNode中,整个文件系统的文件数量会受限于NameNode的内存大小。不适用于多方读写,不适用于需要任意的文件修改HDFS采用追加(append-only)的方式写入数据不支持文件任意offset的修改,不支持多个写入器(writer)。
HDFS的架构是一个主/从(Mater/Slave)体系结构。HDFS由HDFS Client、NameNode、DataNode和Secondary NameNode四部分组成。其中,Client就是客户端,NameNode就是master,是一个管理者,DataNode是Slave,实际操作执行NameNode下达的命令,Secondary NameNode是辅助NameNode,分担其工作量的存在,紧急情况下,可以辅助恢复NameNode。
NameNode在内存中保存着整个文件系统的名称、空间和文件数据块的地址映射,整个HDFS可存储的文件数受限于NameNode的内存大小。DataNode提供真实文件数据的存储服务,以数据块的形式存储HDFS文件,相应HDFS客户端读写请求,周期性向NameNode汇报心跳信息,周期性向NameNode汇报数据块信息,周期性向NameNode汇报缓存数据块信息。
HDFS的文件副本机制:所有文件都是以block块的方式存放在HDFS文件操作系统中,作用:一个文件有可能大于集群中任意一个磁盘,引入块机制,可以很好的解决这个问题;使用块作为文件存储的逻辑单位可以简化存储子系统;块非常适合用于数据备份进而提供数据容错能力。

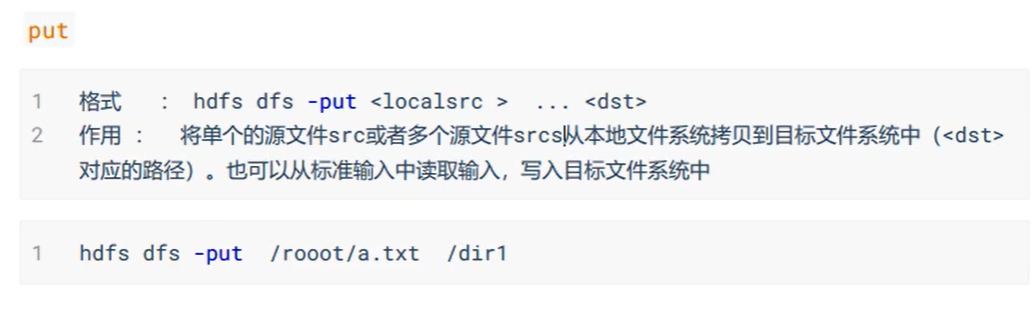

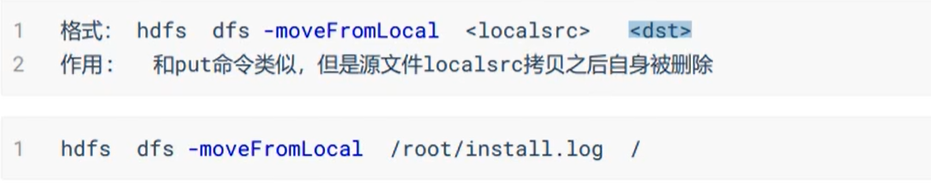

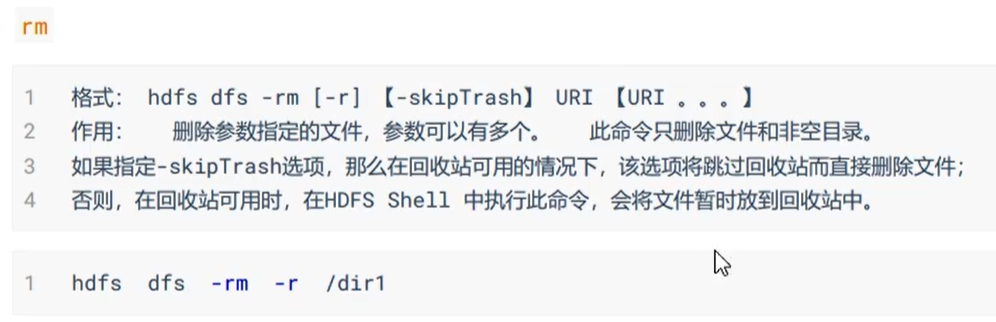


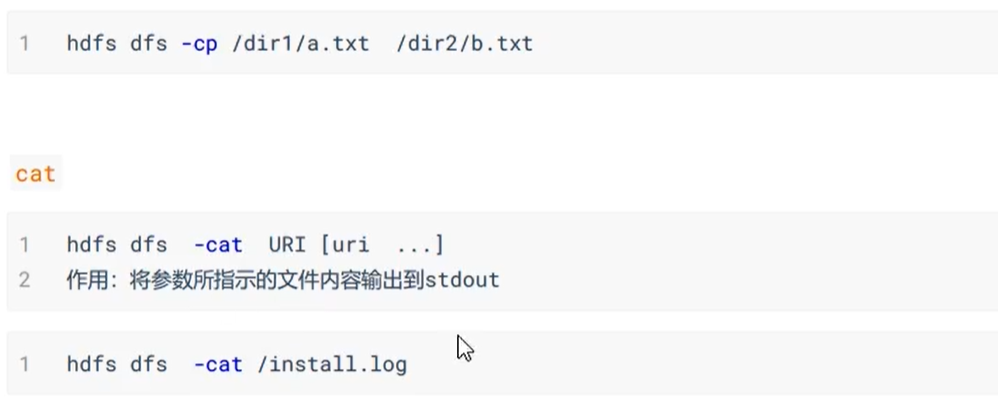
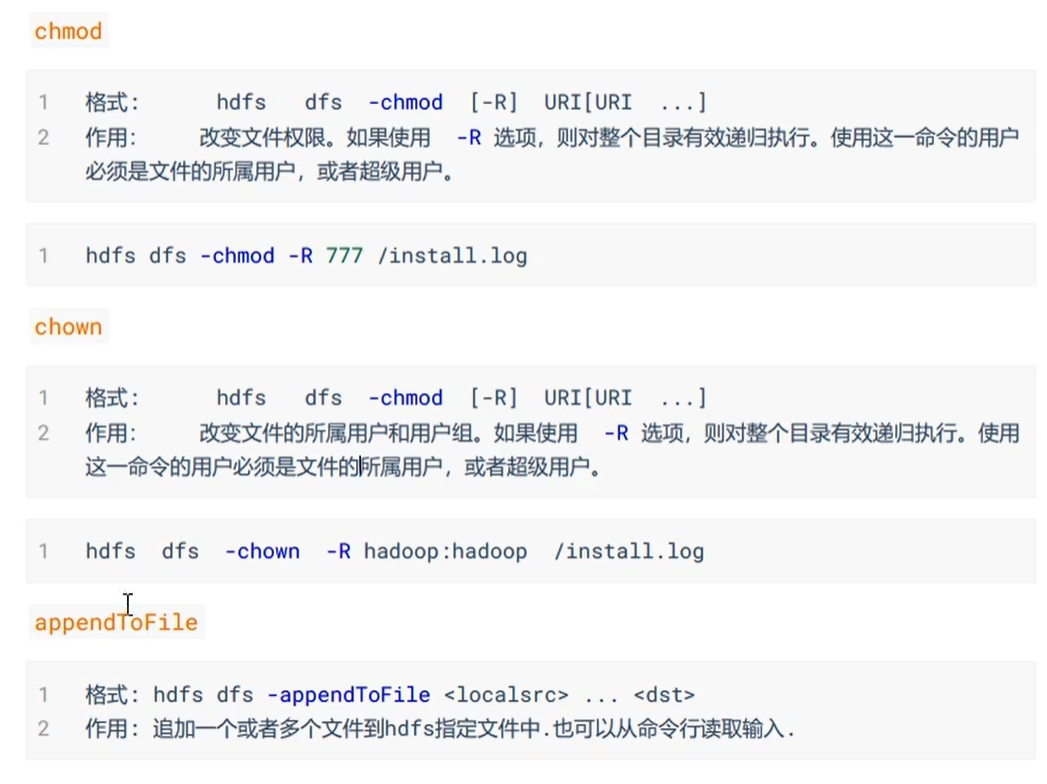

还有一些HDFS文件限额配置的命令,以及一些关于安全模式的高级命令。
还学习了HDFS的文件写入过程和读取过程。
另外,还学习了hdfs的文件管理:fsimage文件和edits文件,以及secondarynamenode。