Profiling is an alternative to benchmarking that is often more effective, as it gives you more fine grained measurements for the components of the system you're measuring, thus minimising external influences from consideration. It also gives the relative cost of various components, further discounting external influence.
As a consequence of giving more fine grained information for a component, profiling is really just a special case of monitoring and often uses the same infrastructure. As systems become more complex, it's becoming increasingly important to know what monitoring tools are available. By the way, being able to drill down into software components as I'll describe below, is a large advantage that open systems have over closed ones.
GNU/Linux profiling and monitoring tools are currently progressing rapidly, and are in some flux, but I'll summarise the readily available utils below.
System wide profiling
The Linux kernel has recently implemented a very useful perf infrastructure for profiling various CPU and software events. To get the perf command, install linux-tools-common on ubuntu, linux-base on debian, perf-utils on archlinux, or perf on fedora. Then you can profile the system like:
$ perf record -a -g sleep 10 # record system for 10s $ perf report --sort comm,dso # display report
That will display this handy curses interface on basically any hardware platform, which you can use to drill down to the area of interest.
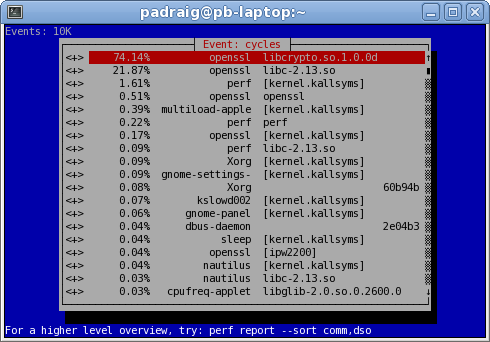
See Brendan Gregg's perf examples for a more up to date and detailed exploration of perf's capabilities.
Other system wide profiling tools to consider are sysprof and oprofile.
It's worth noting that profiling can be problematic on x86_64 at least, due to -fno-omit-frame-pointer being removed to increase performance, and 32 bit fedora at least may be going the same way.
Application level profiling
One can use perf to profile a particular command too, with a variant of the above, like perf record -g $command, or see Ingo Molnar's example of using perf to analyze the string comparison bottneck in `git gc`. There are other useful userspace tools available though. Here is an example profiling ulc_casecoll, where the graphical profile below is generated using the following commands.
valgrind --tool=callgrind ./a.out kcachegrind callgrind.out.*

Note kcachegrind is part of the "kdesdk" package on my fedora system, and can be used to read oprofile data (mentioned above) or profile python code too.
Profiling hardware events
I've detailed previously how important, efficient use of the memory hierarchy is for performance. Newer CPUs are providing counters to help tune your use of this hierarchy, and the previously mentioned Linux perf tools, expose this well. Unfortunately my pentium-m laptop doesn't expose any cache counters, but the following example from Ingo Molnar, shows how useful this technique can be.
static char array[1000][1000];
int main (void)
{
int i, j;
for (i = 0; i < 1000; i++)
for (j = 0; j < 1000; j++)
array[j][i]++;
return 0;
}
On hardware that supports enumerating cache hits and misses, you can run:
$ perf stat --repeat 10 -e cycles:u -e instructions:u -e l1-dcache-loads:u
-e l1-dcache-load-misses:u ./a.out
Performance counter stats for './a.out' (10 runs):
6,719,130 cycles:u ( +- 0.662% )
5,084,792 instructions:u # 0.757 IPC ( +- 0.000% )
1,037,032 l1-dcache-loads:u ( +- 0.009% )
1,003,604 l1-dcache-load-misses:u ( +- 0.003% )
0.003802098 seconds time elapsed ( +- 13.395% )
Note the large ratio of cache misses.
Now if we change array[j][i]++; to array[i][j]++; and re-run perf-stat:
$ perf stat --repeat 10 -e cycles:u -e instructions:u -e l1-dcache-loads:u
-e l1-dcache-load-misses:u ./a.out
Performance counter stats for './a.out' (10 runs):
2,395,407 cycles:u ( +- 0.365% )
5,084,788 instructions:u # 2.123 IPC ( +- 0.000% )
1,035,731 l1-dcache-loads:u ( +- 0.006% )
3,955 l1-dcache-load-misses:u ( +- 4.872% )
0.001806438 seconds time elapsed ( +- 3.831% )
We can see the L1 cache is much more effective.
To identify hot spots to concentrate on you can use:
$ perf top -e l1-dcache-load-misses -e l1-dcache-loads
PerfTop: 1923 irqs/sec kernel: 0.0% exact: 0.0% [l1-dcache-load-misses...
----------------------------------------------------------------------------------
weight samples pcnt funct DSO
______ _______ _____ _____ ______________________
1.9 6184 98.8% func2 /home/padraig/a.out
0.0 69 1.1% func1 /home/padraig/a.out
Specialised profiling
system entry points
- strace -c $cmd
- ltrace -c $cmd
heap memory
- google perftools (does CPU profiling too)
- go perftools
- valgrind massif
- glib mem tracing with systemtap
I/O
- I/O profiling with systemtap
- process I/O profiling with ioprofile (uses strace & lsof)
- process I/O profiling with iogrind
GCC
- gprof sampling
- -finstrument-functions and_cyg_profile_func_enter
- instrument functions and display with graphvis