布隆过滤器简介
布隆过滤器(BloomFilter)是1970年由布隆提出的一种空间空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并判断一个元素是否属于这个集合。使用布隆过滤器,存在第一类出错(Falsepositive),但是不会存在第二类错误(Falsenegative),因此,布隆过滤器拥有100%的召回率。也就是说,布隆过滤器能够准确判断一个元素不在集合内,但只能判断一个元素可能在集合内。因此,BloomFilter不适合“零错误”的应用场合。在能够容忍低错误的应用场合下,BloomFilter通过极少的错误换取了存储空间的极大节省。我们可以向布隆过滤器里添加元素,但是不能从中移除元素(普通布隆过滤器,增强的布隆过滤器是可以移除元素的)。随着布隆过滤器中元素的增加,犯第一类错误的可能性也随之增大。
基本原理:
在进行布隆过滤器的介绍前,先说一下位数组(bit array)。所谓的位数组,主要是为了有效地利用内存空间而设计的一种存储数据的方式。在这种结构中一个整数在内存中用一位(1 bit)表示。这里所谓的表示就是如果整数存在,相应的二进制位就为 1,否则为 0。
布隆过滤器便利用了位数组的特性,它通过 hash 函数(为了降低 hash 函数的冲突效应,一般会选择多个随机的 hash 函数)将一个元素映射成一个位数组(Bit array)中的某些点上。在检索的时候,通过判断这些点是不是 1 来判读集合中有没有某个特定的元素。这就是布隆过滤器的基本思想。
举个例子,假设我们有 4 个元素 ‘cat’,‘dog’,‘pig’,‘bee’,选择 3 个 hash 函数,位数组长度为 10。为了方便说明,我们依次修改位数组的值。当插入第一个元素时 ‘cat’ 后,位数组变为: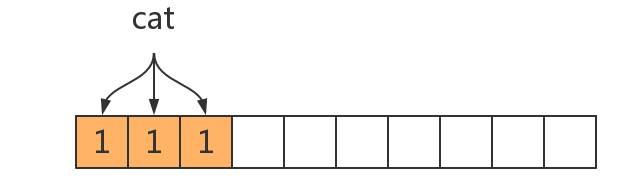
当插入 ‘dog’ 和 ‘pig’ 后,位数组变为:

当我们查询 ‘bee’ 的时候,如果,‘bee’ 有一位或两位映射在 9,10 位上,则可以正确判断出元素 ‘bee’ 不在集合中,但是如果 ‘bee’ 被映射在 1-8 位上则会出现误判,并且随着元素增加,误判率会逐渐增加。
布隆过滤器的判断有以下特点:
- 如果判断一个元素在集合中,那么这个元素有一定概率不在集合中(会出现误判)
- 如果判断一个元素不在集合中,那么这个元素一定不在集合中(不会出现误判)
上面的例子说明了布隆过滤器的插入过程和误判率的问题,在这个例子中涉及三个重要数值:
需要存放的集合中元素的个数 n
位数组的长度 m
hash 函数的个数 k
最优的 m 和 k
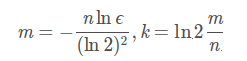
参考代码