近期在跟进新项目的时候,整体的业务线非常之长,会一直重复登录退出不同账号的这个流程,所以想从登录开始实现部分的自动化。因为是B/S的架构,所以采用的是selenium的框架来实现。大致实现步骤如下:
1.环境准备
2.验证码爬取
3.识别方案选择
4.图像处理和识别
5.自动化实现
一、环境准备
系统:macOS
软件:Pycharm
语言:Python 2.7
浏览器:Chrome 70.0.35
依赖库:selenium 3.141、xlrd 1.1、aip 1.0.0.5、pytesser、pytesseract 0.2.5、opencv-python 3.4.3、urllib3 1.24.1、Pillow-PIL 0.1
驱动安装与配置环境:
① 下载chromedriver:http://chromedriver.storage.googleapis.com/index.html(需代理)、http://npm.taobao.org/mirrors/chromedriver/(无需代理)
②具体浏览器与驱动版本映射表可参考 https://blog.csdn.net/huilan_same/article/details/51896672 ,最新chrome 74版本---ChromeDriver v74.0.3729.6
③解压后放置在/usr/local/bin/目录下
④加入环境变量:export PATH=$PATH:/usr/local/bin/ChromeDriver
二、验证码爬取
对于验证码而言,目前各式网站出现的验证码类型基本有:图形验证码(数字、计算题、中文、英文、问答题)、滑块验证码、语音验证码、图片验证码(正倒序、同类型)。自身项目的验证码为数字+英文图形验证码,针对这一块的内容,首先我们先来爬取一些验证码到指定文件夹中,来着重分析一下特点。代码如下:
1 #-*- coding:utf-8 -*- 2 from selenium import webdriver 3 import time 4 import urllib 5 import os 6 import sys 7 8 9 req_url = "https://项目网址/#/" 10 11 12 def download_code(num): 13 for i in range(int(num)): 14 browser.refresh() 15 time.sleep(3) 16 # 寻找登录按钮,查找登录classname 17 browser.find_elements_by_css_selector("[class='ant-btn logining-btn ant-btn-primary ant-btn-lg ant-btn-background-ghost']")[0].click() 18 time.sleep(3) 19 #获取验证码url链接 20 src=browser.find_elements_by_css_selector("[class='picturecode-img']")[0].get_attribute("src") 21 time.sleep(1) 22 23 local = '/Users/funny/PycharmProjects/auto_cloud/code_pic/' + str(i) + '.png' 24 print local 25 urllib.urlretrieve(src,local) 26 time.sleep(1) 27 28 if __name__=="__main__": 29 browser = webdriver.Chrome() 30 browser.get(req_url) 31 download_code(sys.argv[1]) 32 browser.close()
大致讲解一下上面出现的一些函数用法和实现过程中存在的问题。
1.使用classname定位,运行时报错
A:一般来说,使用classname来定位还是比较精准的,但是此项目的classname包含了多个tag,如上述的登录按钮class='ant-btn logining-btn ant-btn-primary ant-btn-lg ant-btn-background-ghost',这时候使用 find_elements_by_class_name方法定位,会无法定位并报错。所以需要使用find_elements_by_css_selector,大家可以根据各自项目来选择方法。
2.urllib.urlretrieve(src,local)
urllib模块提供的urlretrieve()函数,urlretrieve()方法直接将远程数据下载到本地,传入下载的链接。
3.命令行获取参数
为了指定我们想要下载的验证码数量,要在源程序里面修改吗?不用。sys.argv[]是一个从程序外部获取参数的桥梁,所获得的是一个列表(list),文中的sys.argv[1]则是代表获取列表中的下标为1的内容,在终端我们运行的方法是:python catch_code.py 10 ,这样sys.argv[1]取到的的值则为10,num的值亦为10,循环10次下载验证码。
三、识别方案选择
上节中爬取下来了100张验证码,如下图:

基本特性是:横向排列、数字与英文字母组合、字母间粘连占比约30%、背景干扰较少。阅读已有的一些ocr识别技术,基本有以下三个方向:
① pytesser
② pytesseract
③ 百度文字识别 AipOcr
为了对比这三者识别技术的识别率,对应实现来展示效果,所以样本选择为0.png、4.png、11.png(字母粘连、纯字母、字母+数字)
pytesser:谷歌OCR开源项目的一个模块,在python中导入这个模块即可将图片中的文字转换成文本。pytesser下载链接:http://code.google.com/p/pytesser/ ,实现代码如下:
1 #-*- coding:utf-8 -*- 2 from PIL import Image 3 import pytesser.pytesser as pytesser 4 5 image = Image.open('code_pic/test_pic/0.png') 6 print pytesser.image_file_to_string('code_pic/test_pic/0.png') 7 print pytesser.image_to_string(image)
image_file_to_string()函数可以实现简单的英文字母识别,如果图像是不相容的,会先转换成兼容的格式,然后再提取图片中的文本信息。
image_to_string()函数亦可实现英文字母识别,读取图片时,将内存中的图像文件保存为bmp,再使用tesseract处理。
执行结果如下:

顺序识别0,4,11图片后均无法识别结果,识别概率为0%
pytesseract:Google的Tesseract-OCR引擎包装器
1 print pytesseract.image_to_string(Image.open('code_pic/test_pic/11.png'),lang="eng")
顺序识别0,4,11图片后均无法识别结果,识别概率为0%
AipOcr:一款百度提供的OCR识别服务,支持多种图片格式,接口免费调用50000次/日,具体请参考官方文档:https://ai.baidu.com/docs#/OCR-API/top ,在实现之前,我们需要创建一款产品,来获得AppID、API Key、Secret Key的值。如下图:

获取到以上三个参数后,继续上代码:
1 from aip import AipOcr 2 3 # 你的 APPID AK SK 4 APP_ID = '1*****' 5 API_KEY = 'sHzo*******' 6 SECRET_KEY = 'V******' 7 8 client = AipOcr(APP_ID, API_KEY, SECRET_KEY) 9 # 读取图片 10 def get_file_content(filePath): 11 with open(filePath, 'rb') as fp: 12 return fp.read() 13 14 image = get_file_content('/Users/funny/PycharmProjects/auto_cloud/code_pic/test_pic/11.png') 15 # 调用通用文字识别, 图片参数为本地图片 16 result = client.general(image) 17 18 # 定义参数变量 19 options = { 20 # 定义图像方向 21 'detect_direction' : 'true', 22 # 识别语言类型,默认为'CHN_ENG'中英文混合 23 'language_type' : 'CHN_ENG', 24 25 26 } 27 28 # 调用通用文字识别接口 29 result = client.general(image,options) 30 print(result) 31 for word in result['words_result']: 32 print(word['words'])
顺序识别0,4,11图片后,图片11识别出了一半,提取到了"2F",概率为16%
四、图像处理和识别
在上节看来,未经过处理的图片进行识别,识别概率都非常之低。所以我们换一个角度来思考,通过对图片进行一些处理,使得特征更加明显,再通过上述的三种识别库来识别,提高识别的概率。步骤大致如下:1)灰度二值化 2)线降噪 3)开运算
1)灰度二值化
im = cv2.imread('/Users/funny/PycharmProjects/auto_cloud/code_pic/0.png') im = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY) # 二值化 th1 = cv2.adaptiveThreshold(im, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 1) edges = cv2.Canny(th1, 30, 70) cv2.imshow('二值化',th1) cv2.waitKey(0) cv2.destroyAllWindows()
处理的图像如下:
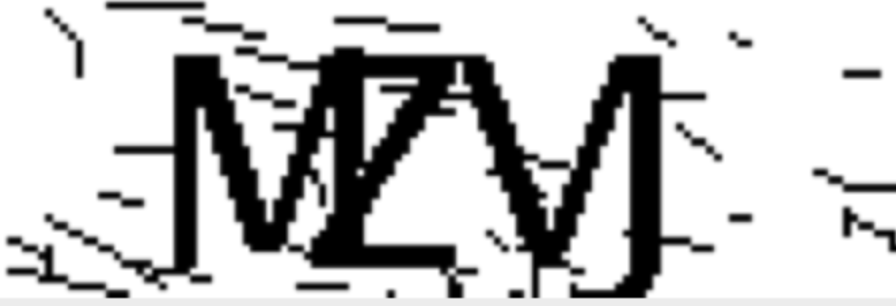
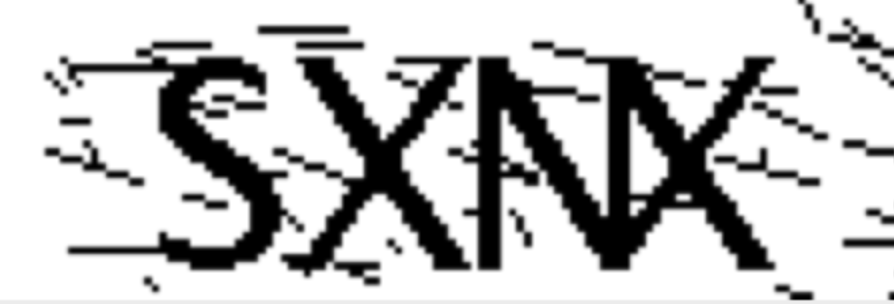
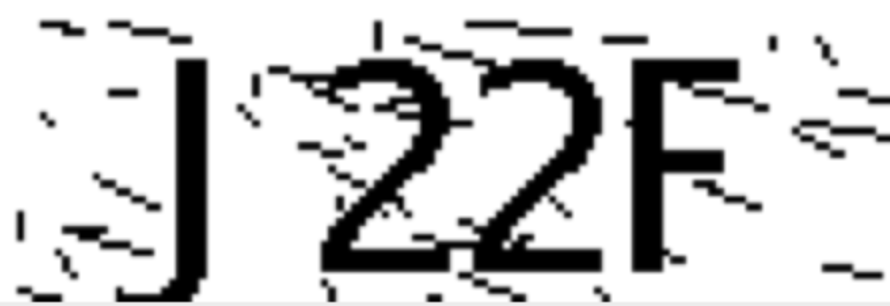
2)线降噪
#二值化图片,并且线降噪 img = cv2.imread('/Users/funny/PycharmProjects/auto_cloud/code_pic/11.png') img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #灰值化 h, w = img.shape[:2] # opencv矩阵点是反的 # img[1,2] 1:图片的高度,2:图片的宽度 for y in range(1, w - 1): for x in range(1, h - 1): count = 0 if img[x, y - 1] > 245: count = count + 1 if img[x, y + 1] > 245: count = count + 1 if img[x - 1, y] > 245: count = count + 1 if img[x + 1, y] > 245: count = count + 1 if count > 2: img[x, y] = 255 cv2.imshow('线降噪',img) cv2.waitKey(0) cv2.destroyAllWindows()
处理的图像如下:

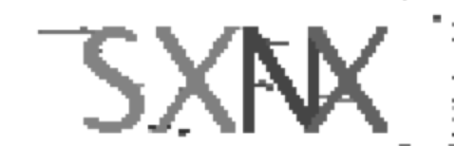

3)闭运算
img = cv2.imread('/Users/funny/PycharmProjects/auto_cloud/code_pic/11.png') img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 3)) # 定义结构元素 opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel) # 开运算 closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) cv2.imshow('闭运算',closing) cv2.waitKey(0) cv2.destroyAllWindows()
处理的图像如下:



图像处理到现在基本上我们已经将已有的背景干扰及色彩去除完毕,接下来我们针对这些处理的图像进行三种识别方案的识别,识别结果如下表:

我们来分析一下这个表,在最开始的二值化,AipOcr至少识别出来了一些内容。纵观三种图像处理后的识别效果,明显闭运算已经能识别出大致的内容了,图片4.png三种识别方式都是可以识别出来,对于0.png这种粘连字母,识别效果基本为0%,而11.png“j”的底部表现不出来,所以识别不出来,但后面的内容亦识别成功。所以我们可以总结三点:①识别方式精准度 :AipOcr>pytesser>pytesseract。 ②处理后效果:闭运算>线降噪>二值化。③粘连性、带噪点图片识别效果非常差(当前准确值是基于我选取的样本集)。
五、自动化实现
从上节的处理和识别中的总结内容中,本项目我们选择将AipOcr作为识别,若识别结果不正确(如粘连、噪点过多、部分裁剪图片),将获取新的验证码,以此类推。将上述部分代码封装,方便调用,最终完整代码如下:
1 #-*- coding:utf-8 -*- 2 from selenium import webdriver 3 from time import sleep 4 import xlrd 5 import os 6 import time 7 import urllib 8 import cv2 9 from aip import AipOcr 10 #define 11 req_url = "网址" 12 local = '/Users/funny/PycharmProjects/auto_cloud/code_pic/code.png' 13 APP_ID = '1****2' 14 API_KEY = 's*****' 15 SECRET_KEY = 'V******Hw' 16 xlsname="user_tab.xlsx" 17 18 #excel读取 19 def Load_excel(): 20 excel = xlrd.open_workbook(xlsname) 21 shxrange = range(excel.nsheets) 22 try: 23 sh = excel.sheet_by_name("Sheet1") 24 except: 25 print "no sheet in %s named Sheet1" % xlsname 26 nrows = sh.nrows 27 ncols = sh.ncols 28 #print "nrows %d, ncols %d" % (nrows, ncols) 29 # 获取第一行第一列数据 30 cell_value = sh.cell_value(1, 1) 31 # print cell_value 32 row_list = [] 33 # 获取各行数据 34 for i in range(1, nrows): 35 row_data = sh.row_values(i) 36 row_list.append(row_data) 37 return row_list 38 39 def change_catch(): 40 img = cv2.imread('/Users/funny/PycharmProjects/auto_cloud/code_pic/code.png') 41 img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) 42 kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 3)) # 定义结构元素 43 closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) 44 cv2.imwrite('/Users/funny/PycharmProjects/auto_cloud/code_pic/code-close.png',closing) 45 46 def code_detect(): 47 client = AipOcr(APP_ID, API_KEY, SECRET_KEY) 48 f=open('/Users/funny/PycharmProjects/auto_cloud/code_pic/code-close.png','rb') 49 image =f.read() 50 # 调用通用文字识别, 图片参数为本地图片 51 result = client.general(image) 52 # 定义参数变量 53 options = { 54 # 定义图像方向 55 'detect_direction': 'true', 56 # 识别语言类型,默认为'CHN_ENG'中英文混合 57 'language_type': 'CHN_ENG', 58 } 59 # 调用通用文字识别接口 60 result = client.general(image, options) 61 print result 62 print str(result['words_result'][0]['words']) 63 return str(result['words_result'][0]['words']) 64 65 66 67 68 69 70 if __name__ == '__main__': 71 72 flag=False 73 row_list=Load_excel() 74 print row_list 75 browser = webdriver.Chrome() 76 browser.get(req_url) 77 time.sleep(4) 78 #寻找登录按钮,查找登录classname 79 browser.find_elements_by_css_selector("[class='ant-btn logining-btn ant-btn-primary ant-btn-lg ant-btn-background-ghost']")[0].click() 80 time.sleep(2) 81 #获取验证码url 82 src = browser.find_elements_by_css_selector("[class='picturecode-img']")[0].get_attribute("src") 83 urllib.urlretrieve(src, local) 84 print "下载验证码中。。。" 85 change_catch() 86 word=code_detect() 87 print word 88 time.sleep(1) 89 browser.find_element_by_id("loginName").send_keys(row_list[0][1]) 90 browser.find_element_by_id("password").send_keys(row_list[0][2]) 91 browser.find_element_by_id("imgValidCode").send_keys(word) 92 browser.find_elements_by_css_selector("[class='ant-btn ant-btn-primary ant-btn-lg ant-btn-block']")[0].click() 93 time.sleep(1) 94 95 while browser.current_url=="网址": 96 time.sleep(2) 97 src = browser.find_elements_by_css_selector("[class='picturecode-img']")[0].get_attribute("src") 98 urllib.urlretrieve(src, local) 99 print "下载验证码中。。。" 100 change_catch() 101 word = code_detect() 102 time.sleep(2) 103 browser.find_element_by_id("imgValidCode").send_keys(word) 104 browser.find_elements_by_css_selector("[class='ant-btn ant-btn-primary ant-btn-lg ant-btn-block']")[0].click() 105 106 print "登录成功"
对于粘连性及部分被切割的验证码,还需要再研究一番~
另,因为验证码识别率还不能达到100%,且后期可能因为版本迭代的原因,更换不同方式的验证码类型,所以这里只是提供一个图像预处理思路给到大家,实现登录自动化还有其他方式,如白名单控制、关闭验证码校验等。