ELK日志分析之安装
1.介绍:
- NRT
elasticsearch是一个近似实时的搜索平台,从索引文档到可搜索有些延迟,通常为1秒。 - 集群
集群就是一个或多个节点存储数据,其中一个节点为主节点,这个主节点是可以通过选举产生的,并提供跨节点的联合索引和搜索的功能。集群有一个唯一性标示的名字,默认是elasticsearch,集群名字很重要,每个节点是基于集群名字加入到其集群中的。因此,确保在不同环境中使用不同的集群名字。一个集群可以只有一个节点。强烈建议在配置elasticsearch时,配置成集群模式。 - 节点
节点就是一台单一的服务器,是集群的一部分,存储数据并参与集群的索引和搜索功能。像集群一样,节点也是通过名字来标识,默认是在节点启动时随机分配的字符名。当然啦,你可以自己定义。该名字也蛮重要的,在集群中用于识别服务器对应的节点。
节点可以通过指定集群名字来加入到集群中。默认情况下,每个节点被设置成加入到elasticsearch集群。如果启动了多个节点,假设能自动发现对方,他们将会自动组建一个名为 elasticsearch的集群。
- 索引
索引是有几分相似属性的一系列文档的集合。如nginx日志索引、syslog索引等等。索引是由名字标识,名字必须全部小写。这个名字用来进行索引、搜索、更新和删除文档的操作。
索引相对于关系型数据库的库。 - 类型
在一个索引中,可以定义一个或多个类型。类型是一个逻辑类别还是分区完全取决于你。通常情况下,一个类型被定于成具有一组共同字段的文档。如ttlsa运维生成时间所有的数据存入在一个单一的名为logstash-ttlsa的索引中,同时,定义了用户数据类型,帖子数据类型和评论类型。
类型相对于关系型数据库的表。
- 文档
文档是信息的基本单元,可以被索引的。文档是以JSON格式表现的。
在类型中,可以根据需求存储多个文档。
虽然一个文档在物理上位于一个索引,实际上一个文档必须在一个索引内被索引和分配一个类型。
文档相对于关系型数据库的列。
- 分片和副本
在实际情况下,索引存储的数据可能超过单个节点的硬件限制。如一个十亿文档需1TB空间可能不适合存储在单个节点的磁盘上,或者从单个节点搜索请求太慢了。为了解决这个问题,elasticsearch提供将索引分成多个分片的功能。当在创建索引时,可以定义想要分片的数量。每一个分片就是一个全功能的独立的索引,可以位于集群中任何节点上。
分片的两个最主要原因:
a、水平分割扩展,增大存储量
b、分布式并行跨分片操作,提高性能和吞吐量
分布式分片的机制和搜索请求的文档如何汇总完全是有elasticsearch控制的,这些对用户而言是透明的。
网络问题等等其它问题可以在任何时候不期而至,为了健壮性,强烈建议要有一个故障切换机制,无论何种故障以防止分片或者节点不可用。
为此,elasticsearch让我们将索引分片复制一份或多份,称之为分片副本或副本。
副本也有两个最主要原因:
高可用性,以应对分片或者节点故障。出于这个原因,分片副本要在不同的节点上。
提供性能,增大吞吐量,搜索可以并行在所有副本上执行。
总之,每一个索引可以被分成多个分片。索引也可以有0个或多个副本。复制后,每个索引都有主分片(母分片)和复制分片(复制于母分片)。分片和副本数量可以在每个索引被创建时定义。索引创建后,可以在任何时候动态的更改副本数量,但是,不能改变分片数。
默认情况下,elasticsearch为每个索引分片5个主分片和1个副本,这就意味着集群至少需要2个节点。索引将会有5个主分片和5个副本(1个完整副本),每个索引总共有10个分片。
每个elasticsearch分片是一个Lucene索引。一个单个Lucene索引有最大的文档数LUCENE-5843, 文档数限制为2147483519(MAX_VALUE – 128)。 可通过_cat/shards来监控分片大小。 - 索引和类型的解释:

-
ELK的含义:
E: elasticsearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
也就是将logstach收集上来的日志储存,建立索引(便于查找),搜索(提供web展示)
l:logstash
收集日志
数据源:各种log,文本,session,silk,snmp
k:kibana
数据展示,web页面,可视化
可以完成批量分析
数据集之间关联
产生图表
报警 (python / R 语言 )
ES python api的文档
-
ELK 关系:
2.安装
1、下载tar包直接解压(灵活)
2、配置yum源直接安装(方便)
服务器部署:
logstatsh : 部署在想收集日志的服务器上。
elasticsearch:主要是用于数据收集,索引,搜索提供展示,随意安装在那台服务器上都可以,重要的是es支持分布式,而且再大规模的日志分析中必须做分布式集群。这样可以跨节点索引和搜索。提高吞吐量与计算能力。
kibana:数据展示,部署在任意服务器上。
这里我们做实验使用的是两台服务器
|
1
2
|
node1.wawa.com : 192.168.31.179node2.wawa.com : 192.168.31.205 |
a、准备环境:
配置hosts两台服务器网络通畅
node1 安装es,node2安装es 做成集群,后期可能还会用到redis,redis提供的功能相当于kafka,收集logstatsh发来的数据,es从redis中提取数据。
node1 安装kibana 做数据展示
node2 安装logstatsh 做数据收集
创建 elasticsearch 用户
b、安装:
由于es logstatsh kibana基于java 开发,所以安装jdk ,jdk版本不要过低,否则会提醒升级jdk。
安装elasticsearch(node1,node2全都安装es)
下载并安装GPG key
2.x
|
1
|
[root@linux-node1 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch |
5.1
|
1
|
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch |
添加yum仓库
|
1
2
3
4
5
6
7
|
[root@linux-node2 ~]# vim /etc/yum.repos.d/elasticsearch.repo[elasticsearch-2.x]name=Elasticsearch repository for 2.x packagesbaseurl=http://packages.elastic.co/elasticsearch/2.x/centosgpgcheck=1gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearchenabled=1 |
|
1
2
3
4
5
6
7
8
|
[elasticsearch-5.x]name=Elasticsearch repository for 5.x packagesbaseurl=https://artifacts.elastic.co/packages/5.x/yumgpgcheck=1gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearchenabled=1autorefresh=1type=rpm-md |
es需要jdk8,但是由于服务器有的业务需要1.7,所以可以让两个共存
安装elasticsearch
|
1
|
[root@hadoop-node2 ~]# yum install -y elasticsearch |
问题:
阿里服务器下载和用yum安装由于链接是https的问题报错
增加yum 源报错

[root@szdz-SLAVE svr]# yum repolist Loaded plugins: security https://artifacts.elastic.co/packages/5.x/yum/repodata/repomd.xml: [Errno 14] PYCURL ERROR 51 - "SSL: certificate subject name 'server.co.com' does not match target host name 'artifacts.elastic.co'"
下载GPG key
[root@szdz-SLAVE src]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch curl: (6) Couldn't resolve host 'artifacts.elastic.co' error: https://artifacts.elastic.co/GPG-KEY-elasticsearch: import read failed(2). [root@szdz-SLAVE src]# curl https://artifa
- 下载tar包安装,更简单,解压即可运行,只不过没有yum安装提供的启动脚本
安装kibana(这里使用的tar包安装,es、log tar包方法一样)
|
1
2
3
4
5
|
[root@linux-node2 ~]#cd /usr/local/src[root@linux-node2 ~]#wget https://download.elastic.co/kibana/kibana/kibana-4.3.1-linux-x64.tar.gztar zxf kibana-4.3.1-linux-x64.tar.gz[root@linux-node1 src]# mv kibana-4.3.1-linux-x64 /usr/local/[root@linux-node2 src]# ln -s /usr/local/kibana-4.3.1-linux-x64/ /usr/local/kibana |
安装logstatsh (node2安装)
下载并安装GPG key
|
1
|
[root@linux-node2 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch |
添加yum仓库
|
1
2
3
4
5
6
7
|
[root@linux-node2 ~]# vim /etc/yum.repos.d/logstash.repo[logstash-2.1]name=Logstash repository for 2.1.x packagesbaseurl=http://packages.elastic.co/logstash/2.1/centosgpgcheck=1gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearchenabled=1 |
安装logstash
|
1
|
[root@linux-node2 ~]# yum install -y logstash |
c、配置管理elasticsearch
|
1
2
3
4
5
6
7
8
9
10
|
[root@linux-node1 src]# grep -n '^[a-Z]' /etc/elasticsearch/elasticsearch.yml17:cluster.name: chuck-cluster 判别节点是否是统一集群,多台统一集群的es名称要一致23:node.name: linux-node1 节点的hostname33:path.data: /data/es-data 数据存放路径37:path.logs: /var/log/elasticsearch/ 日志路径43:bootstrap.memory_lock: true 锁住内存,使内存不会再swap中使用54:network.host: 0.0.0.0 允许访问的ip58:http.port: 9200 端口[root@linux-node1 ~]# mkdir -p /data/es-data[root@linux-node1 src]# chown elasticsearch.elasticsearch /data/es-data/ |
d、启动 elasticsearch

[root@node2 ~]# /etc/init.d/elasticsearch status
elasticsearch (pid 23485) 正在运行...
You have new mail in /var/spool/mail/root
[root@node2 ~]# ps aux| grep elasticsearch
505 23485 2.1 53.1 2561964 264616 ? Sl 17:09 6:07 /usr/bin/java -Xms256m -Xmx1g -Djava.awt.headless=true -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError -XX:+DisableExplicitGC -Dfile.encoding=UTF-8 -Djna.nosys=true -Des.path.home=/usr/share/elasticsearch -cp /usr/share/elasticsearch/lib/elasticsearch-2.4.2.jar:/usr/share/elasticsearch/lib/* org.elasticsearch.bootstrap.Elasticsearch start -p /var/run/elasticsearch/elasticsearch.pid -d -Des.default.path.home=/usr/share/elasticsearch -Des.default.path.logs=/var/log/elasticsearch -Des.default.path.data=/var/lib/elasticsearch -Des.default.path.conf=/etc/elasticsearch
root 26425 0.0 0.1 103260 844 pts/0 S+ 21:57 0:00 grep elasticsearch
[root@node2 ~]# ss -tunlp | grep elasticsearch
[root@node2 ~]# ss -tunlp | grep 23485
tcp LISTEN 0 50 :::9200 :::* users:(("java",23485,132))
tcp LISTEN 0 50 :::9300 :::* users:(("java",23485,89))
启动问题:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
[root@szdz-SLAVE svr]# /etc/init.d/elasticsearch start正在启动 elasticsearch:Exception in thread "main" BindTransportException[Failed to bind to [9300-9400]]; nested: ChannelException[Failed to bind to: /221.223.97.142:9400]; nested: BindException[无法指定被请求的地址];Likely root cause: java.net.BindException: 无法指定被请求的地址 at sun.nio.ch.Net.bind0(Native Method) at sun.nio.ch.Net.bind(Net.java:344) at sun.nio.ch.Net.bind(Net.java:336) at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:199) at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74) at org.jboss.netty.channel.socket.nio.NioServerBoss$RegisterTask.run(NioServerBoss.java:193) at org.jboss.netty.channel.socket.nio.AbstractNioSelector.processTaskQueue(AbstractNioSelector.java:391) at org.jboss.netty.channel.socket.nio.AbstractNioSelector.run(AbstractNioSelector.java:315) at org.jboss.netty.channel.socket.nio.NioServerBoss.run(NioServerBoss.java:42) at org.jboss.netty.util.ThreadRenamingRunnable.run(ThreadRenamingRunnable.java:108) at org.jboss.netty.util.internal.DeadLockProofWorker$1.run(DeadLockProofWorker.java:42) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1110) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:603) at java.lang.Thread.run(Thread.java:722)Refer to the log for complete error details. |
network.host: 要填写本机的ip地址,最好是内网。
e、测试
交互方式:
交互的两种方法
- Java API :
node client
Transport client - RESTful API
Javascript
.NET
php
Perl
Python
Ruby - ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
1、我们使用RESTful web接口
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
[root@linux-node1 src]# curl -i -XGET 'http://192.168.56.11:9200/_count?pretty' -d '{"query" { #查询 "match_all": {} #所有信息}}'<br>####################<br>HTTP/1.1 200 OKContent-Type: application/json; charset=UTF-8Content-Length: 95{ "count" : 0, 索引0个 "_shards" : { 分区0个 "total" : 0, "successful" : 0, 成功0个 "failed" : 0 失败0个 }} |
2、使用es 强大的插件 : head插件显示索引和分片情况
f、安装插件
|
1
2
|
[root@linux-node1 src]# /usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head[root@linux-node1 src]# /usr/share/elasticsearch/bin/plugin list 可以查看当前已经安装的插件 |

访问刚刚安装的head插件
|
1
|
http://192.168.31.179:9200/_plugin/head/ |

添加数据测试


增加:
命令行插入数据与查询数据(RESTful接口处理的JSON请求)
|
1
|
curl -XPOST http://127.0.0.1:9330/logstash-2017.01.09/testlog -d '{"date":"123456","user":"chenlin7","mesg":"first mesasge"}' |
返回值
|
1
|
{"_index":"logstash-2017.01.09","_type":"testlog","_id":"AVmBUmd9WXPobNRX0V5f","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"created":true} |
可以看到,在数据写入的时候,会返回该数据的 。这就是后续用来获取数据 的关键:
获取数据
|
1
|
curl -XGET http://127.0.0.1:9330/logstash-2017.01.09/testlog/AVmBUmd9WXPobNRX0V5f |
返回值:
|
1
|
{"_index":"logstash-2017.01.09","_type":"testlog","_id":"AVmBUmd9WXPobNRX0V5f","_version":1,"found":true,"_source":{"date":"123456","user":"chenlin7","mesg":"first mesasge"}} |
这个 里的内容,正是之前写入的数据。
如果觉得这个返回看起来有点太过麻烦,可以使用_source 直接指定要获取内容
|
1
|
curl -XGET http://127.0.0.1:9330/logstash-2017.01.09/testlog/AVmBUmd9WXPobNRX0V5f/_source |
返回值
|
1
|
{"date":"123456","user":"chenlin7","mesg":"first mesasge"} |
也可以直接指定字段:
curl -XGET http://115.29.229.72:9330/logstash-2017.01.09/testlog/AVmBUmd9WXPobNRX0V5f?fields=user,mesg
返回值
|
1
|
{"_index":"logstash-2017.01.09","_type":"testlog","_id":"AVmBUmd9WXPobNRX0V5f","_version":1,"found":true,"fields":{"user":["chenlin7"],"mesg":["first mesasge"]}}% |
删除
删除指定的单条数据
curl -XDELETE http://115.29.229.72:9330/logstash-2017.01.09/testlog/AVmB7OKdWXPobNRX0V5m
删除整个索引(尝试删除某一个类型应该是不支持)
curl -XDELETE http://115.29.229.72:9330/logstash-2017.01.09 or curl -XDELETE http://115.29.229.72:9330/logstash-2017.01.* (支持通配符)
更新
更新有两种方法,意识全量提交,指明_id才发一次请求
|
1
2
3
4
5
6
|
# curl -XPOST http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK -d '{ "date" : "1434966686000", "user" : "chenlin7", "mesg" " "first message into Elasticsearch but version 2"}' |
另一个是局部更新使用/_update接口
指定doc 添加或修改字段
|
1
|
curl -XPOST 'http://127.0.0.1:9330/logstash-2017.01.09/testlog/AVmB92lCWXPobNRX0V5v/_update' -d '{"doc":{"age":"18"}}' |
指定script(文档中操作是这样。没有试过)
# curl -XPOST 'http://127.0.0.1:9200/logstash-2015.06.21/testlog
/AU4ew3h2nBE6n0qcyVJK/_update' -d '{
"script" : "ctx._source.user = "someone""
}'
搜索请求
全文搜索:ES的搜索请求,有简易语法和完整语法两种
简易语法作为以后在kibana上最常用的方式。
|
1
|
curl -XGET http://115.29.229.72:9330/logstash-2017.01.09/testlog1/_search?q=first |
这样就获取到了logstash-2017.01.09索引中的testlog1类型中first关键字的所有数据
{"took":4,"timed_out":false,"_shards":{
"total":5,"successful":5,"failed":0
},
"hits":{
"total":1,"max_score":0.30685282,
"hits":[{
"_index":"logstash-2017.01.09",
"_type":"testlog1","_id":"AVmB90IfWXPobNRX0V5u",
"_score":0.30685282,"_source":{
"date":"123456",
"user":"chenlin7",
"mesg":"first mesasge"}
}]
}
}
还可以使用
|
1
|
curl -XGET http://115.29.229.72:9330/logstash-2017.01.09/testlog/_search?q=user:"chenlin7" |
或者知道某个字段一定在那个key中:例子中就是 first一定是在mesg中
|
1
|
curl -XGET http://115.29.229.72:9330/logstash-2017.01.09/testlog/_search?q=mesg:first |
node2安装好以后配置集群模式
|
1
2
3
4
|
[root@node1 src]# scp /etc/elasticsearch/elasticsearch.yml 192.168.56.12:/etc/elasticsearch/elasticsearch.yml[root@node2 elasticsearch]# sed -i '23s#node.name: linux-node1#node.name: linux-node2#g' elasticsearch.yml[root@node2 elasticsearch]# mkdir -p /data/es-data[root@node2 elasticsearch]# chown elasticsearch.elasticsearch /data/es-data/ |
node1与node2中都配置上(单播模式,听说还有组播默认,可以尝试一下)
|
1
2
3
|
[root@linux-node1 ~]# grep -n "^discovery" /etc/elasticsearch/elasticsearch.yml79:discovery.zen.ping.unicast.hosts: ["linux-node1", "linux-node2"][root@linux-node1 ~]# systemctl restart elasticsearch.service |
在浏览器中查看分片信息,一个索引默认被分成了5个分片,每份数据被分成了五个分片(可以调节分片数量),下图中外围带绿色框的为主分片,不带框的为副本分片,主分片丢失,副本分片会复制一份成为主分片,起到了高可用的作用,主副分片也可以使用负载均衡加快查询速度,但是如果主副本分片都丢失,则索引就是彻底丢失。

安装使用kopf插件,监控elasticsearch(elasticsearch服务器都安装)
|
1
|
[root@linux-node1 bin]# /usr/share/elasticsearch/bin/plugin install lmenezes/elasticsearch-kopf |

重启es服务,访问,没有意外你就能看到这个界面


还有什么别的用暂时还不知道
安装logstatsh
下载并安装GPG key
|
1
|
[root@linux-node2 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch |
添加yum仓库
|
1
2
3
4
5
6
7
|
[root@linux-node2 ~]# vim /etc/yum.repos.d/logstash.repo[logstash-2.1]name=Logstash repository for 2.1.x packagesbaseurl=http://packages.elastic.co/logstash/2.1/centosgpgcheck=1gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearchenabled=1 |
安装logstash
|
1
|
[root@linux-node2 ~]# yum install -y logstash |
- 也可以下载logstash的tar包解压即可使用
安装后就可以测试了
logstatsh有两种启动方式,一种用就是测试启动,一种就是正式启动
logstash工作方式:logstatsh的功能是收集日志文件,并将收集的日志文件发送给es服务器。然后es服务器产生索引,提供搜索,并且再交给web展示
但是日志类型和索引名称都是在logstatsh中定义的
a、首先我们熟悉logstatsh的格式是以jason为格式,其中定义输入输出
|
1
|
‘input { stdin{} } output { stdout{} }’ |
input :输入,output :输出
input可以是命令行手动输入,也可以是指定一个文件,或者一个服务,
output是输出位置。可以是屏幕打印,也可以指定es服务器
- 我们先做一个最基础的命令行输入,和屏幕输出
|
1
2
3
4
5
6
|
[root@node2 bin]# /opt/logstash/bin/logstash -e 'input { stdin{} } output { stdout{} }' <br>#stdin 指定输入为stdin标准输入 output:指定stdout标准输出<br><br>Settings: Default filter workers: 1Logstash startup completed<br>chuck --> 命令行输入2016-01-14T06:01:07.184Z node2 chuck ==>屏幕输出<br>www.chuck-blog.com --> 命令行输入2016-01-14T06:01:18.581Z node2 www.chuck-blog.com ==>屏幕输出 |
- 使用rubudebug显示详细输出,codec为一种编解码器
|
1
2
3
4
5
6
7
8
9
10
|
[root@node2 bin]# /opt/logstash/bin/logstash -e 'input { stdin{} } output { stdout{ codec => rubydebug} }' #codec 指定输出的解码器,不知道还有没有别的解码器Settings: Default filter workers: 1Logstash startup completedchuck ---> 屏幕输入{ "message" => "chuck", "@version" => "1", "@timestamp" => "2016-01-14T06:07:50.117Z", "host" => "node2"} --->rubydebug格式输出 |
上述每一条输出的内容称为一个事件,多个相同的输出的内容合并到一起称为一个事件(举例:日志中连续相同的日志输出称为一个事件)!
** Logstash 会给时间添加一些额外信息,最重要的就是@timestamp,用来标记时间的发生时间。因为这个字段涉及到Logs他说的内部流传,所以必须是一个joda对象,如果你尝试自己给一个字符串
字段命名为@timestamp,Logstash会直接报错。所以,青丝用filter/data插件来管理这个特殊字段
此外大多数时候,还可以见到另外几个。
|
1
2
3
4
5
|
1、host标记时间发生在哪里2、type标记时间的唯一类型3、tags标记时间的某方面属性。这是一个数组,一个时间可以有多个标签。 |
Logstash 格式及支持的数据类型: Logstash 格式被命名为区段(section)
section的格式是:
input{
stdin{
}
syslog{
}
}
数据类型
- bool
debug => true
- string
host => "hostname"
- number
ip => 127.0.0.1
- array
match => ["datetime","Unix"]
- hash
options => {
key1 = > "value1",
key2 => "value2"
}
** 如果版本低于1.2.0 hash的写法和array是一样的
字段:

- 使用logstash将信息写入到elasticsearch
|
1
|
[root@linux-node2 bin]# /opt/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch { hosts => ["192.168.1.105:9200"] } }' |
|
1
2
3
4
5
6
7
|
#这里定义的output 就是指定es服务器的地址以及端口,也可以直接写hostnameSettings: Default filter workers: 1Logstash startup completedmaliangchuckwww.google.comwww.baidu.com |


也可以本地输出,和远程发送同时进行
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
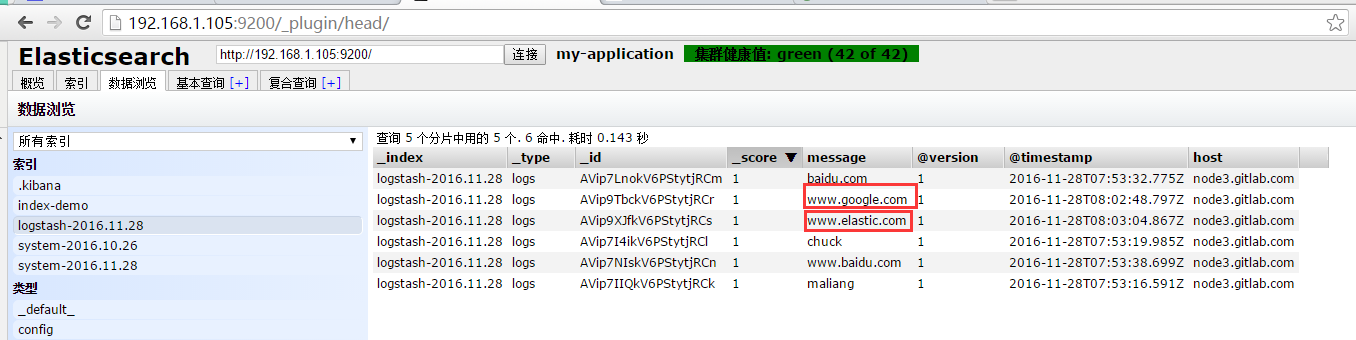
[root@-node2 bin]# /opt/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch { hosts => ["192.168.1.105:9200"] } stdout{ codec => rubydebug } }'Settings: Default filter workers: 1Logstash startup completedwww.google.com{ "message" => "www.google.com", "@version" => "1", "@timestamp" => "2016-01-14T06:27:49.014Z", "host" => "node2"}www.elastic.com { "message" => "www.elastic.com", "@version" => "1", "@timestamp" => "2016-01-14T06:27:58.058Z", "host" => "node2"} |
- 使用logstatsh读取一个配置文件,把写好的规则放在文件中
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
[root@node2 ~]# cat test.confinput { stdin { } }output { elasticsearch { hosts => ["192.168.31.105:9200"] } #发送 stdout { codec => rubydebug } #并且显示}<br><strong>[root@linux-node1 ~]# /opt/logstash/bin/logstash -f test.conf</strong><br>Settings: Default filter workers: 1Logstash startup completed123<br>{ "message" => "123", "@version" => "1", "@timestamp" => "2016-01-14T06:51:13.411Z", "host" => "lnode1 |
如果你是yum安装,就可以把这个位置文件放在 /etc/logstash/conf.d/ 下面 直接启动logstatsh 就直接发送给es服务器了
b、学习编写conf格式
- 输入插件配置,此处以file为例,可以设置多个
|
1
2
3
4
5
6
7
8
9
10
|
input { file { path => "/var/log/messages" type => "syslog" #类型 } file { path => "/var/log/apache/access.log" type => "apache" #类型 }} |
- 介绍几种收集文件的方式,可以使用数组方式或者用*匹配,也可以写多个path
|
1
2
|
path => ["/var/log/messages","/var/log/*.log"]path => ["/data/mysql/mysql.log"] |
- 设置boolean值
|
1
|
ssl_enable => true |
- 文件大小单位
|
1
2
3
4
|
my_bytes => "1113" # 1113 bytesmy_bytes => "10MiB" # 10485760 bytesmy_bytes => "100kib" # 102400 bytesmy_bytes => "180 mb" # 180000000 bytes |
- jason收集
|
1
|
codec => “json” |
- hash收集
|
1
2
3
4
5
|
match => { "field1" => "value1" "field2" => "value2" ...} |
- 端口
|
1
|
port => 33 |
- 密码
|
1
|
my_password => "password" |
c、学习编写input的file插件

sincedb_path:记录logstash读取位置的路径
start_postion :包括beginning和end,指定收集的位置,默认是end,从尾部开始
add_field 加一个域
discover_internal 发现间隔,每隔多久收集一次,默认15秒
d、学习编写output的file插件

e、通过input和output插件编写conf文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@node3 ~]# cat /etc/logstash/conf.d/syslog.confinput { file { path => "/var/log/my_syslog" #日志地址 type => "syslog" #自定义类型 start_position => "beginning" #从头开始读取日志 }}output { elasticsearch { #输出推送给es服务器 hosts => ["node2.gitlab.com"] #es服务器地址 index => "system-%{+YYYY.MM.dd}" #自定义索引 }} |
- 我们不是配置了两台es吗,怎么就发给一个呢?是因为es服务器本身支持集群分片,当数据到达es服务器的时候,es服务器自己会将日志信息分散到所有其他的服务器上。
- 然后我们就能够在页面上看到了
两台服务器,然后每台服务分成了5份,在浏览器中查看分片信息,一个索引默认被分成了5个分片,每份数据被分成了五个分片(可以调节分片数量),下图中外围带绿色框的为主分片,不带框的为副本分片,主分片丢失,副本分片会复制一份成为主分片,起到了高可用的作用,主副分片也可以使用负载均衡加快查询速度,但是如果主副本分片都丢失,则索引就是彻底丢失。 
f、使用type来匹配类型
**start_position 仅在文件未被监控过的时候起作用,如果sincedb文件中已经有监控文件的inode记录了,那么Logstash依然会从记录过的pos开始读取。所以重复测试的时候每次需要删除sincedb文件。不过有一个巧妙的方法
就是把sincedb文件的位置定义在/dev/null中,这样每次重启自动从开头读取
g、把多行整个报错收集到一个事件中

以at.org开头的内容都属于同一个事件,但是显示在不同行,这样的日志格式看起来很不方便,所以需要把他们合并到一个事件中
引入codec的multiline插件
官方文档提供
|
1
2
3
4
5
6
7
8
9
|
input { stdin { codec => multiline { ` pattern => "pattern, a regexp" negate => "true" or "false" what => "previous" or "next"` } }} |
regrxp:使用正则,什么情况下把多行合并起来
negate:正向匹配和反向匹配
what:合并到当前行还是下一行
在标准输入和标准输出中测试以证明多行收集到一个日志成功
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
[root@linux-node1 ~]# cat muliline.confinput { stdin { codec => multiline { pattern => "^[" negate => true what => "previous" } }}output { stdout { codec => "rubydebug" }}[root@linux-node1 ~]# /opt/logstash/bin/logstash -f muliline.confSettings: Default filter workers: 1Logstash startup completed[1[2{ "@timestamp" => "2016-01-15T06:46:10.712Z", "message" => "[1", "@version" => "1", "host" => "linux-node1"}chuckchuck-blog.com123456[3{ "@timestamp" => "2016-01-15T06:46:16.306Z", "message" => "[2
chuck
chuck-bloh
chuck-blog.com
123456", "@version" => "1", "tags" => [ [0] "multiline" ], "host" => "linux-node1" |
继续将上述实验结果放到all.conf的es-error索引中
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
[root@linux-node1 ~]# cat all.confinput { file { path => "/var/log/messages" type => "system" start_position => "beginning" } file { path => "/var/log/elasticsearch/chuck-clueser.log" type => "es-error" start_position => "beginning" codec => multiline { pattern => "^[" negate => true what => "previous" } }}output { if [type] == "system" { elasticsearch { hosts => ["192.168.56.11:9200"] index => "system-%{+YYYY.MM.dd}" } } if [type] == "es-error" { elasticsearch { hosts => ["192.168.56.11:9200"] index => "es-error-%{+YYYY.MM.dd}" } }} |
Logstash 使用一个名叫FileWatch 的Ruby Gem 库来监听文件变化。这个库支持glob展开文件路径,并且会记录一个叫.sincedb的数据库文件来跟踪被坚挺的日志文件的当前读取位置。
sincedb文件中记录了每个被坚挺的文件的 inode,major number, minor number 和 pos
h. 使用log4j插件收集tomcat日志
首先在tomcat的log4j配置文件中进行修改,让日志输出到一个地方,然后使用Logstash去这个地方收集
这个地方就是一个ip+port
一般tomat中log4j的配置有两种形式,一种是log4j.properties 另一种是log4j.xml 文件位置:
第一种:
|
1
|
webapps/ROOT/WEB-INF/classes/log4j.properties |
 log4j.properties
log4j.propertiesinput {
log4j {
type => "testapi3" #日志类型
host => "127.0.0.1" #接受的地址
port => 4990 #接受的端口
}
}
output {
stdout{
codec => rubydebug
}
}
其他参数
add_field :添加一个字段到时间中
类型 hash
默认为空 {}
codec:输入时的字符编码
默认为"plain"
data_timeout : 超时时间
默认值为5
读超时秒。如果一个特定的TCP连接空闲时间超过这个超时周期,就认为这个任务死了,并不在监听。如果你不想超时,用-1。
host: 监听地址
默认: 0.0.0.0
如实是服务器的话,就监听这个。如果是客户端则连接这个地址
mode:设置是服务器还是客户端(server|client)
默认 server
模式切换:服务器监听客户端的连接,客户端发送到服务器
tags
类型:array
没有设置默认值
添加任意数量的任意标签的事件。这可以帮助处理。
处理结果样式图:

kibana的配置
|
1
2
3
4
5
|
[root@node2 logs]# grep '^[a-Z]' /opt/svr/kibana/config/kibana.ymlserver.port: 5601server.host: "0.0.0.0"elasticsearch.url: "http://localhost:9200"kibana.index: ".kibana" |
启动
|
1
2
|
[root@node2 kibana]# nohup ./bin/kibana &[1] 6722 |
|
1
2
|
[root@node2 kibana]# ss -tunlp | grep 5601tcp LISTEN 0 128 *:5601 *:* users:(("node",6722,11)) |
在kibana中添加一个elklog索引

点击create 创建
kibana通过elklog的索引去es服务器上搜索有关日志

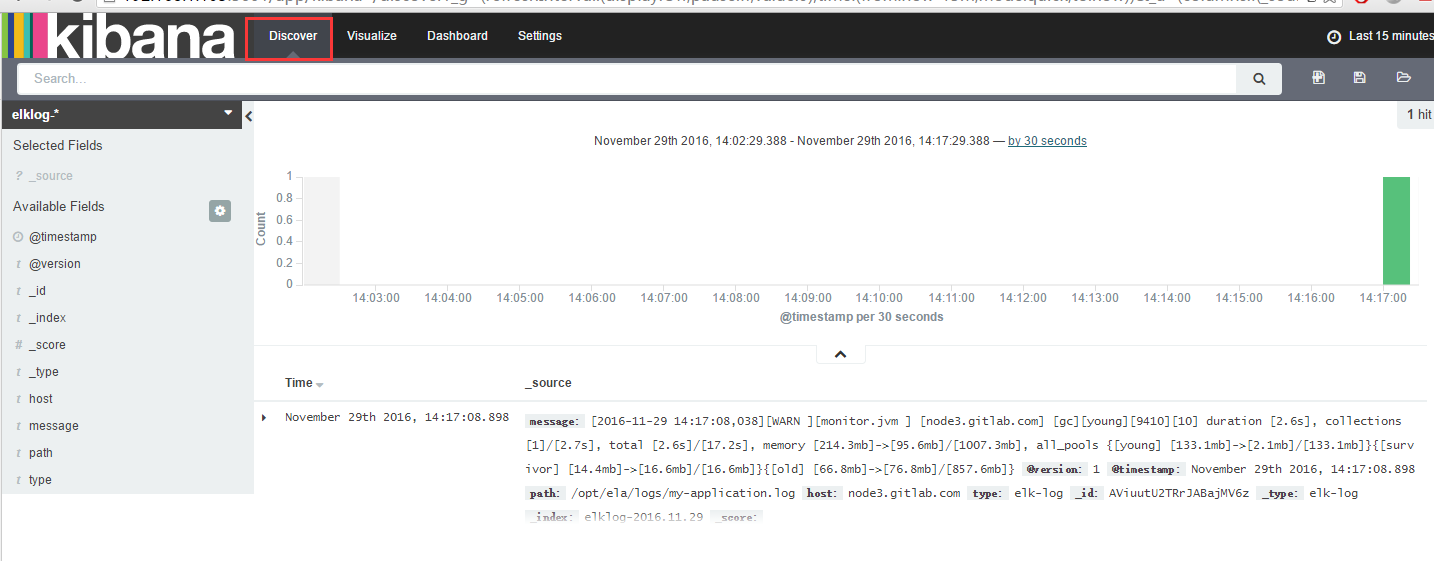
点击discover即可查看到图形界面