- 自适应哈希索引(AHI)
哈希表是一种常见的数据结构,即通过哈希算法计算出一个数字在表中的位置,并将数字存入该表。哈希索引就是通过哈希表来实现的,一般情况下查找时间复杂度为O(1)。InnoDB会监控对表上各索引页的查询,会自动根据访问的频率和模式为某些热点页建立哈希索引,所以又叫自适应哈希索引,访问模式一样指查询的条件一样。
比如我们维护一张身份证信息和用户姓名的表,需要根据身份证号查询姓名,哈希索引大概是这样的:

哈希索引适合只有等值查询的场景,例如select * from T where index_col = '##'。哈希索引是无序的,如果需要区间查询,那就要把所有数据扫描一遍。
- 有序数组索引
有序数组在等值查询和区间查询场景中效率都很高,同样用上面的表举例,索引大概是这样的:
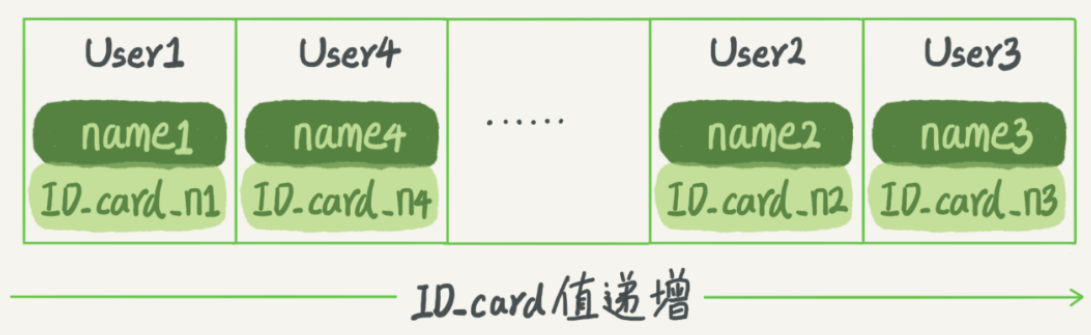
要查询某条数据或者区间的时候,使用二分法时间复杂度为O(logN)。但如果需要在中间更新数据时,那么就要移动后面所有的数据。有序数组索引只适用于静态存储引擎,比如保存2019年度学校所有学生信息。
B+树是为磁盘或其他直接存取辅助设备设计的一种平衡查找树。下面是一颗高度为2的B+树,所有记录都在叶子结点上顺序存放,叶子结点通过指针相连。
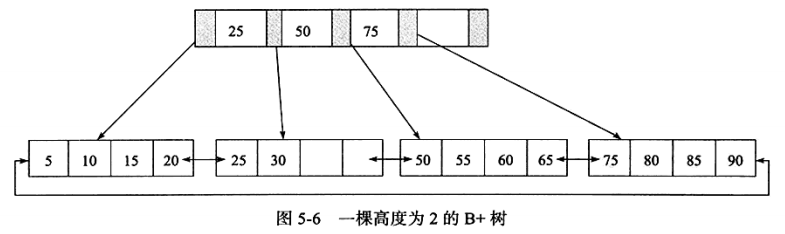
B+树索引就是B+树在数据库中的实现,由于B+索引在数据库中具有高扇出性,在数据库中B+树的高度一般为2~4层。查找某一键值的行记录时最多只需要2~4次IO。以InnoDB的一个整数字段索引为例,这颗B+树大概是1200叉树,这里N叉树的N取决于数据块的大小。高度为4的时候就可以存1200的3次方个值,大概为17亿。考虑到树根的数据块总是在内存中,一个10亿行的表上一个整数字段的索引,查找一个值最多只需要访问3次磁盘。
在InnoDB存储引擎中,表是根据主键顺序存放的。根据叶子结点内容,B+树索引又分为聚簇索引和辅助索引。
-
- 聚簇索引:按照每张表的主键构造一颗B+树,叶子结点的key是主键值, value是该行的其他字段值,聚簇索引的叶子结点也称为数据页。
- 辅助索引:叶子结点的内容是主键的值。
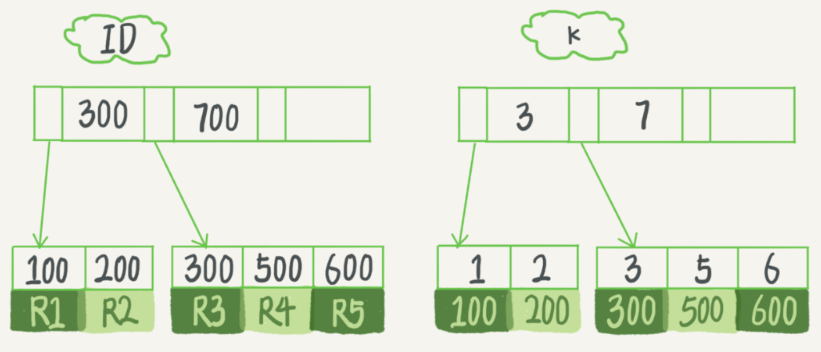
我们用一个例子来说明上面的概念,创建一张表,在字段k上有索引:
create table T( id int primary key, k int not null, name varchar(16), index (k))engine=InnoDB;
表中R1~R5的(ID,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)和(600,6),两颗B+树如下,可以明显看到这两个颗树的区别。